Clear Sky Science · it
Previsione dei furti urbani mediante trasformatore spazio-temporale potenziato da LLM
Perché i cittadini dovrebbero interessarsene
Per chi vive, lavora o fa acquisti in una grande città, il furto è più di una statistica; condiziona la percezione di sicurezza per strada, nei negozi e nei mezzi pubblici. Questo studio prende in esame New York e pone una domanda pratica: possiamo usare l’intelligenza artificiale moderna per indicare, ora per ora e blocco per blocco, dove è più probabile che avvengano furti, evitando di riprodurre semplicemente vecchi bias di polizia? La risposta potrebbe aiutare le città a proteggere persone e beni impiegando le risorse di polizia in modo più mirato.
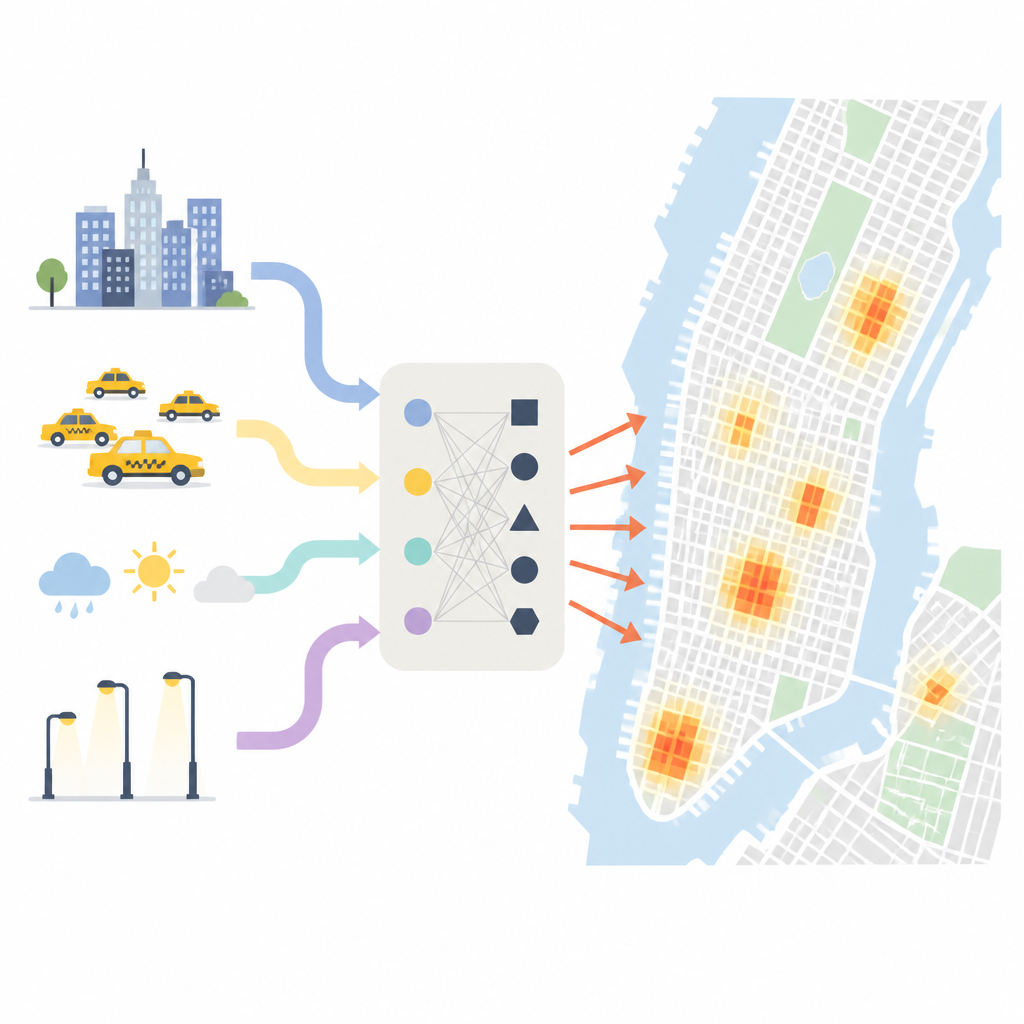
Dove e quando i furti si concentrano davvero
I ricercatori iniziano mostrando quanto i furti siano distribuiti in modo disomogeneo a New York. Usando una griglia fine sovrapposta alla città, trovano che alcune aree ridotte registrano centinaia di volte più furti rispetto ad altre. Circa la metà di tutti i furti è concentrata in una piccolissima frazione di isolati, in particolare nelle zone commerciali dense come Midtown Manhattan. Anche il periodo dell’anno e l’ora del giorno sono importanti: i mesi più caldi, i periodi di shopping festivo e le ore di punta dei pendolari portano più persone in strada e nei negozi, creando più occasioni per i furti. Meteo, illuminazione e tipologia di quartiere aggiungono ulteriori varianti, con notti chiare e asciutte nei distretti commerciali vivaci che emergono come momenti particolarmente a rischio.
Trasformare la vita cittadina in dati
Per cogliere questo quadro complesso, il team combina cinque tipi di informazioni. Utilizzano dettagliati archivi di polizia sui furti passati, salite e discese dei taxi orarie come proxy per i movimenti e gli assembramenti di persone, mappe di negozi, abitazioni, parchi e stazioni, immagini satellitari delle luci notturne e dati meteorologici e censuari di base. Da questi elementi costruiscono decine di indicatori: quanto spesso i reati si ripetono in ciascella della griglia, quanto si affollano le zone commerciali nelle prime ore serali, come il rischio di furto in un isolato si estende ai vicini e come i tassi di criminalità aumentano o diminuiscono con variazioni di pioggia o temperatura. Misurano anche quanto tempo è passato dall’ultimo furto in ogni luogo, che risulta essere un forte indizio sulla probabilità che se ne verifichi un altro a breve.
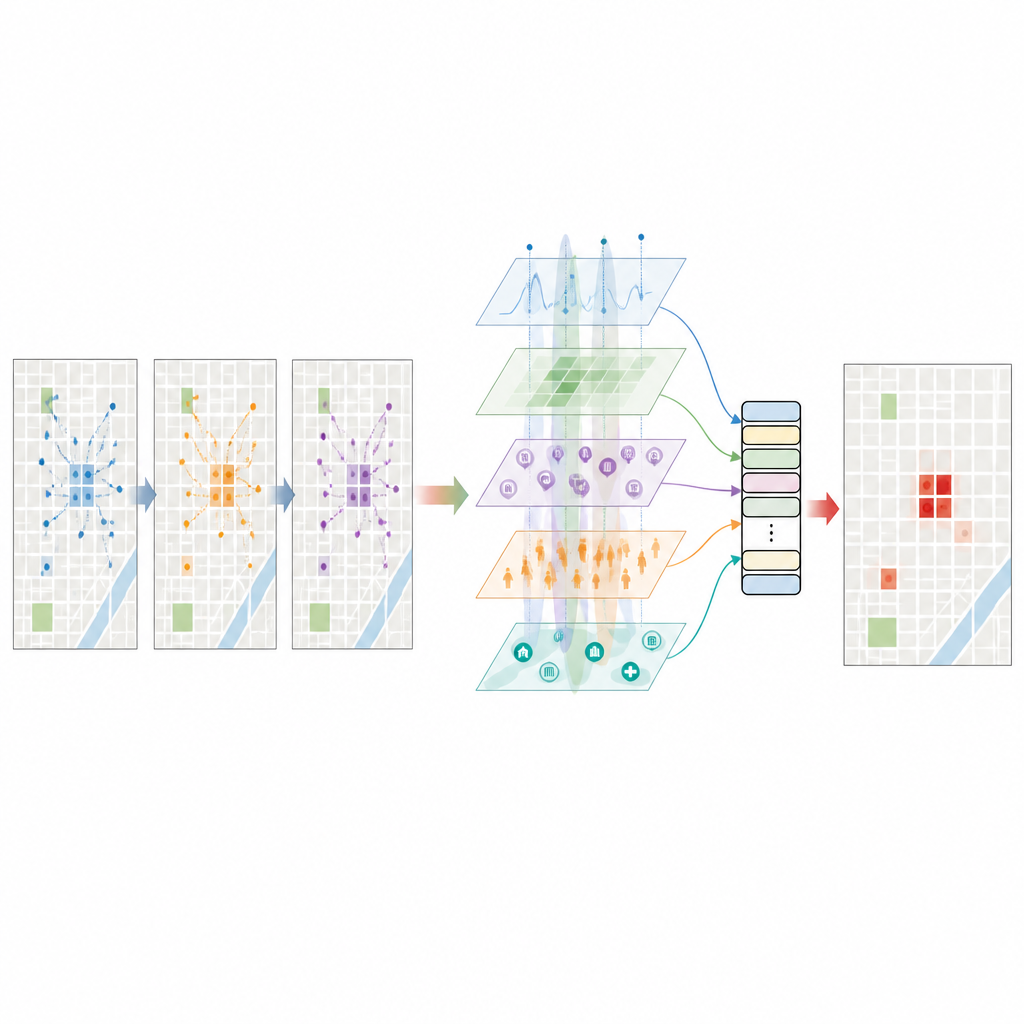
Dare a un modello linguistico una percezione della città
Un passo chiave è chiedere a un grande modello linguistico di leggere brevi descrizioni strutturate di ogni luogo e momento: dove si trova l’isolato, quali tipi di locali contiene, quanto sono intense le luci notturne, quanti passeggeri di taxi sono appena arrivati, com’è il meteo e con quale frequenza si sono verificati furti in precedenza. Il modello risponde quindi con una stima del rischio di furto e altri suggerimenti semantici su come funzione, affollamento e tempo interagiscono. Queste ricche intuizioni testuali vengono trasformate in vettori numerici e filtrate con cura in modo che non duplicano semplicemente i dati strutturati. Il risultato è un ritratto ad alta dimensionalità di ogni cella della griglia che riflette non solo conteggi grezzi, ma anche schemi che il modello linguistico ha appreso da un’ampia gamma di testi su città e criminalità.
Come funziona il motore di predizione
Tutte queste caratteristiche vengono alimentate in un trasformatore spazio-temporale, un tipo di rete neurale progettata per tracciare pattern sia nello spazio sia nel tempo. Il modello porta prima i diversi tipi di feature a uno stesso livello, quindi applica meccanismi di attenzione che imparano quali isolati vicini e quali ore recenti contano di più per ciascuna previsione. Usa inoltre il punteggio di rischio fornito dal modello linguistico come una credenza a priori e lo aggiusta delicatamente con i dati osservati, in modo che nessuna delle due componenti prevalga. Addestrato su diversi anni di dati di New York, il sistema prevede, per ogni cella della griglia e per ogni ora, la probabilità che si verifichi almeno un furto. Nei test raggiunge un elevato livello di discriminazione tra situazioni con e senza furto e un punteggio F1 che riflette un buon equilibrio tra individuare veri hotspot e evitare falsi allarmi.
Cosa significa per la sicurezza quotidiana
Per un non esperto, la conclusione è che il rischio di furto non è casuale; è strettamente legato a come le persone si muovono in città, a come sono utilizzate le diverse aree e a come si sono svolti gli eventi recenti. Mescolando statistiche classiche sulla criminalità con segnali quasi in tempo reale come i flussi di taxi e le luci notturne, oltre al potere interpretativo di un modello linguistico, questo approccio può segnalare una piccola porzione di isolati e ore in cui si verifica gran parte dei furti della città. Pur necessitando ancora di test in altre città e di controlli accurati sull’equità, indica strumenti che potrebbero aiutare polizia e pianificatori urbani a concentrarsi su zone specifiche, affollate e ad alto rischio in orari precisi, invece di estendere un’azione su interi quartieri.
Citazione: Tang, M., Wang, J., Bu, X. et al. Urban theft prediction via LLM-empowered spatiotemporal transformer. Sci Rep 16, 15525 (2026). https://doi.org/10.1038/s41598-026-45681-0
Parole chiave: predizione criminalità urbana, aree calde dei furti, modellizzazione spazio-temporale, flussi di popolazione dinamici, large language models