Clear Sky Science · pl
Nowatorska ramowa sieć splotowa kwantowa do kwantowo-wzmocnionej klasyfikacji pikselizowanych obrazów kolorowych
Widzieć więcej w rozmytych obrazach
Współczesne życie opiera się na obrazach — od skanów medycznych i zdjęć satelitarnych po emotikony i grafiki w grach wideo. W miarę rozrostu tych zbiorów danych komputery analizujące obrazy stają przed dylematem: duże, zaawansowane modele potrzebują ogromnych zestawów danych i dużo energii, podczas gdy w wielu rzeczywistych zadaniach dostępne są tylko pojedyncze, drobne i niskoresolucyjne obrazy. Artykuł bada, czy dziwne prawa fizyki kwantowej mogą pomóc komputerom wykrywać wzorce w takich małych, zaszumionych obrazach bardziej niezawodnie niż współczesne narzędzia.
Dlaczego drobne obrazy to poważne wyzwanie
Klasyczne splotowe sieci neuronowe (CNN) zrewolucjonizowały rozpoznawanie obrazów, skanując je małymi filtrami i ucząc się wielowarstwowych wzorców. Świetnie radzą sobie z dużymi, szczegółowymi obrazami i masywnymi zestawami danych, jak te używane do tagowania zdjęć w sieci. Jednak w wielu praktycznych zastosowaniach — czujniki wbudowane, tanie kamery, detekcja zdalna czy ikony — dostępne są jedynie małe obrazy 4×4 lub 8×8 pikseli, często w ograniczonej liczbie. W takim reżimie małej ilości danych standardowe CNN mają tendencję do przeuczenia: zapamiętują przykłady treningowe zamiast uczyć się ogólnych reguł, co daje imponującą dokładność na znanych obrazach, lecz słabą wydajność na nowych.
Wprowadzenie fizyki kwantowej do widzenia maszynowego
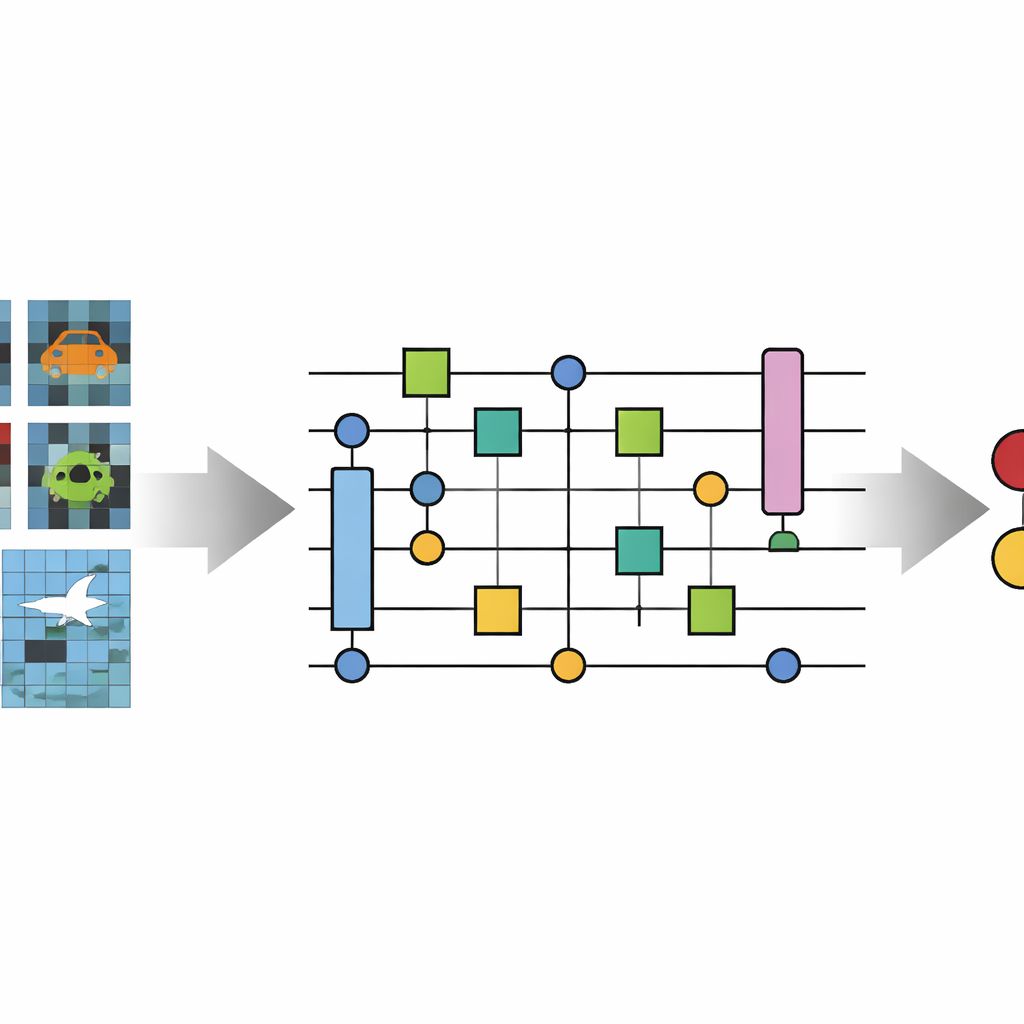
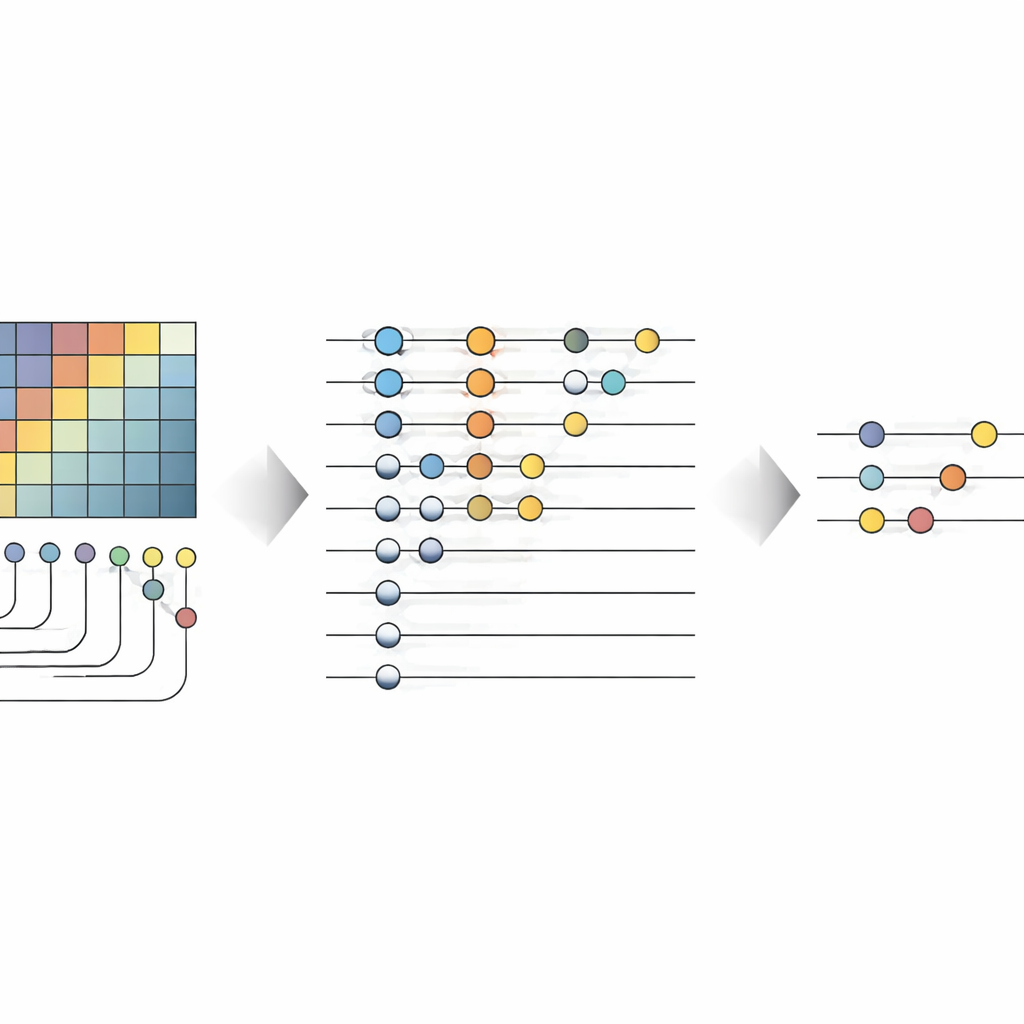
Autorzy przedstawiają Nowatorską Kwantową Splotową Sieć Neuronową (No-QCNN), model hybrydowy wykorzystujący zarówno klasyczny komputer, jak i symulowane urządzenie kwantowe. Główna idea polega na reprezentowaniu każdego drobnego, kolorowego obrazu jako zbioru kubitów. Zamiast bezpośrednio podawać surowe wartości pikseli do sieci, metoda najpierw konwertuje intensywności czerwieni–zieleni–błękitu każdego piksela oraz jego pozycję do zwartego, trójwymiarowego bloku danych. Ten blok jest następnie kodowany w stanie kwantowym za pomocą starannie dobranych rotacji i operacji splątujących pary kubitów. Ponieważ kubity mogą istnieć w superpozycjach i ulegać splątaniu, pojedynczy stan kwantowy może jednocześnie reprezentować wiele kombinacji kolorów i pozycji pikseli, co w zasadzie pozwala uchwycić subtelne korelacje bez bardzo głębokich sieci.
Jak sieć kwantowa przetwarza obrazy
Po zapisaniu obrazu w kubitach, No-QCNN przetwarza go przez sekwencję odzwierciedlającą działanie klasycznych CNN, ale realizowaną w całości na obwodzie kwantowym. Pary kubitów przechodzą przez niewielkie, powtarzane bloki transformacji, które działają jak kwantowe odpowiedniki filtrów splotowych, mieszając informacje z sąsiednich „lokalizacji” na obrazie. Po każdym z tych kwantowych „splotów” operacja kwantowego pooling’u zmniejsza efektywną liczbę kubitów, składując informację z dwóch kubitów w jednym. Warstwa po warstwie obwód zawęża się do zaledwie kilku kubitów, których wyniki pomiarów są interpretowane, poprzez klasyczny etap post‑processingowy, jako przewidywana klasa — na przykład czy linia jest pozioma czy pionowa oraz jaki ma kolor. Siły tych operacji kwantowych są automatycznie dostrajane za pomocą klasycznego optymalizatora, który traktuje cały układ jako model do wytrenowania.
Testowanie podejść kwantowych i klasycznych
Aby sprawdzić działanie No-QCNN, badacze stworzyli proste, lecz wymowne zbiory obrazów. W podstawowym zadaniu każdy obraz 4×4 zawierał albo poziomą, albo pionową jasną linię na zaszumionym tle, tworząc problem dwu‑klasowy. W trudniejszym zadaniu obrazy 8×8 zawierały linię, która mogła być pozioma lub pionowa oraz mieć kolor czerwony, zielony lub niebieski, co dawało sześć możliwych kombinacji. Dla uczciwości model kwantowy uruchomiono na symulatorze wolnym od hałasu, a jego wyniki porównano z kompaktowym klasycznym CNN o podobnej złożoności. W zadaniu binarnym klasyczny CNN osiągnął doskonałą dokładność walidacyjną, podczas gdy No-QCNN osiągnął około 90%, pokazując, że dla prostych problemów o wyraźnej strukturze podejście konwencjonalne wciąż ma przewagę. W bogatszym zadaniu sześcioklasowym przy jedynie 50 obrazach obraz odwrócił się: No-QCNN osiągnął walidacyjną dokładność około 82%, podczas gdy klasyczny CNN spadł do 40%, co świadczy o silnym przeuczeniu.
Gdzie kwantowe widzenie pomaga najbardziej
Eksperymenty ujawniły zarówno obietnicę, jak i ograniczenia. W miarę zwiększania rozmiaru zestawu danych i czasu treningu wydajność No-QCNN stopniowo malała. Stała liczba kubitów i płytka głębokość obwodu oznaczały, że model nie mógł łatwo wchłonąć większej ilości danych, a wielokrotne próbkowanie stanów kwantowych wprowadzało do procesu treningowego dodatkowy szum. Jednak w małych zbiorach danych bogatych w korelacje — w szczególności w zadaniu sześcioklasowym przy bardzo niewielkiej liczbie obrazów na klasę — model kwantowy uogólniał lepiej niż klasyczny CNN. Mówiąc prosto, obwód kwantowy opierał się pokusie zapamiętywania obrazów treningowych i zamiast tego nauczył się reguły, która przenosiła się bardziej niezawodnie na nowe przykłady.
Co to oznacza na przyszłość
Dla osób niebędących specjalistami kluczowa konkluzja jest taka, że kwantowe wersje sieci neuronowych nie są uniwersalnym, magicznym przyspieszaczem dla wszystkich problemów z obrazami ani nie zastąpią od razu dzisiejszych systemów głębokiego uczenia. Zamiast tego badanie wskazuje realistyczną niszę, w której sprzęt kwantowy może najpierw mieć znaczenie: zadania z bardzo małymi obrazami i małą ilością danych, gdzie wzorce są subtelne, a modele klasyczne łatwo się przeuczają. No-QCNN pokazuje, że nawet na wczesnych, hałaśliwych platformach kwantowych (tu symulowanych) starannie zaprojektowane obwody kwantowe mogą konkurować z — a czasem przewyższać — klasyczne CNN pod względem uogólniania, choć kosztem znacznie dłuższego czasu treningu. W miarę jak procesory kwantowe staną się bardziej wydajne i mniej podatne na błędy, architektury takie jak No-QCNN mogą przekształcić się w praktyczne narzędzia do wyspecjalizowanych zadań wizualnych w medycynie, teledetekcji i dalej.
Cytowanie: Daka, C., Bhattacharyya, S. A novel quantum convolutional neural network framework for quantum-enhanced classification of pixelated colour images. Sci Rep 16, 10828 (2026). https://doi.org/10.1038/s41598-026-45140-w
Słowa kluczowe: kwantowe uczenie maszynowe, klasyfikacja obrazów, kwantowe sieci neuronowe, obrazy o niskiej rozdzielczości, hybrydowe modele kwantowo-klasyczne