Clear Sky Science · it
Un nuovo framework di reti neurali convoluzionali quantistiche per la classificazione potenziata di immagini a colori pixelate
Vedere di più nelle immagini sfocate
La vita moderna è dominata dalle immagini, dalle scansioni mediche e foto satellitari fino alle emoji e agli sprite dei videogiochi. Ma man mano che queste raccolte crescono, i computer che le analizzano si trovano davanti a un dilemma: modelli grandi e sofisticati richiedono dataset enormi e molta energia, mentre molti compiti reali devono cavarsela con poche immagini minuscole a bassa risoluzione. Questo articolo esplora se le regole bizzarre della fisica quantistica possano aiutare i computer a rilevare pattern in immagini così piccole e rumorose in modo più affidabile rispetto agli strumenti standard odierni.
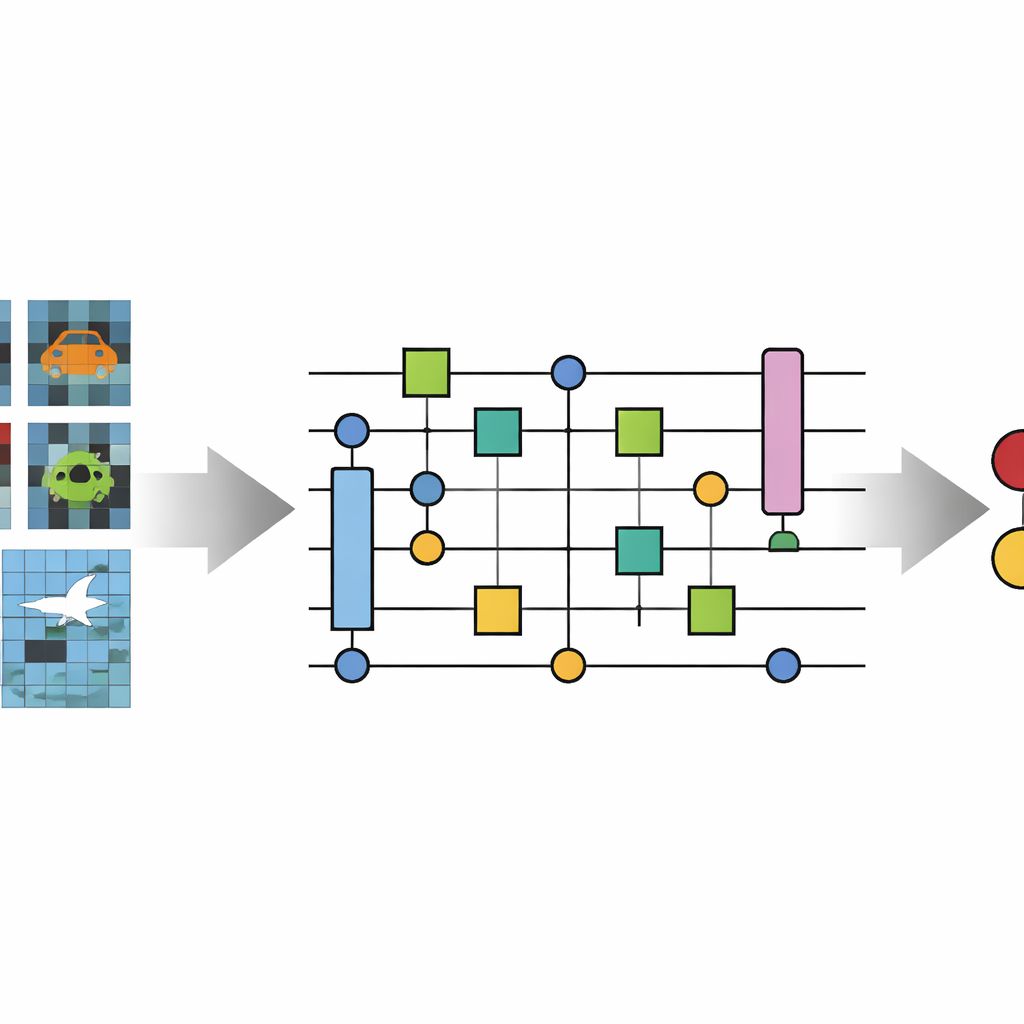
Perché le immagini piccole sono una grande sfida
Le reti neurali convoluzionali (CNN) classiche hanno rivoluzionato il riconoscimento delle immagini scansionando le foto con piccoli filtri e apprendendo livelli di pattern. Eccellono su immagini grandi e dettagliate e su dataset massivi, come quelli usati per il tagging di foto su internet. Tuttavia, in molti contesti pratici — sensori embedded, telecamere a basso costo, telerilevamento o display in formato icona — sono disponibili solo immagini piccole, 4×4 o 8×8 pixel, spesso in numero limitato. In questo regime a basso numero di dati, le CNN standard tendono a sovradattarsi: memorizzano gli esempi di addestramento anziché apprendere regole generali, portando a elevate accuratezze su immagini note ma scarsa performance su quelle nuove.
Portare la fisica quantistica nella visione
Gli autori introducono la Novel Quantum Convolutional Neural Network (No-QCNN), un modello ibrido che utilizza sia un computer convenzionale sia un dispositivo quantistico simulato. L'idea centrale è rappresentare ogni piccola immagine a colori come una collezione di bit quantistici (qubit). Invece di inserire i valori dei pixel grezzi direttamente in una rete, il metodo converte prima le intensità rosso‑verde‑blu di ogni pixel e la sua posizione in un blocco compatto di dati tridimensionale. Questo blocco viene poi codificato in uno stato quantistico usando rotazioni scelte con cura e operazioni di entanglement tra coppie di qubit. Poiché i qubit possono esistere in sovrapposizione ed entanglersi, un singolo stato quantistico può rappresentare molte combinazioni di colori e posizioni dei pixel contemporaneamente, catturando in linea di principio correlazioni sottili senza reti molto profonde.
Come la rete quantistica elabora le immagini
Una volta che l'immagine è immagazzinata nei qubit, No-QCNN la elabora tramite una sequenza che rispecchia le CNN classiche ma viene eseguita interamente su un circuito quantistico. Coppie di qubit subiscono piccoli blocchi di trasformazione ripetuti che agiscono come analoghi quantistici dei filtri di convoluzione, mescolando informazioni da "posizioni" vicine nell'immagine. Dopo ciascuno di questi passaggi di "convoluzione" quantistica, un'operazione di pooling quantistico riduce il numero effettivo di qubit, comprimendo l'informazione di due qubit in uno. Strato dopo strato, il circuito si riduce fino a pochi qubit i cui risultati di misura vengono interpretati, tramite un passaggio di post‑elaborazione classica, come la classe predetta — per esempio se una linea è orizzontale o verticale e quale colore ha. Le intensità di queste operazioni quantistiche sono regolate automaticamente da un ottimizzatore classico che tratta l'intero sistema come un modello addestrabile.
Testare approcci quantistici vs. classici
Per valutare l'efficacia di No-QCNN, i ricercatori hanno creato dataset di immagini semplici ma rivelatori. Nel compito di base, ogni immagine 4×4 conteneva una linea brillante orizzontale o verticale su uno sfondo rumoroso, formando un problema a due classi (binario). Nel compito più impegnativo, le immagini 8×8 contenevano una linea che poteva essere orizzontale o verticale e colorata di rosso, verde o blu, dando sei possibili combinazioni. Per una valutazione equa, il modello quantistico è stato eseguito su un simulatore senza rumore e le sue prestazioni sono state confrontate con una CNN classica compatta di complessità simile. Sul compito binario, la CNN classica ha raggiunto un'accuratezza di validazione perfetta, mentre No-QCNN si è fermata intorno al 90%, mostrando che per problemi semplici con struttura chiara l'approccio convenzionale mantiene ancora il vantaggio. Sul più ricco problema a sei classi con solo 50 immagini, però, la situazione si è invertita: No-QCNN ha raggiunto un'accuratezza di validazione di circa l'82%, mentre la CNN classica è crollata al 40%, segnale di forte overfitting.
Dove la visione quantistica aiuta di più
Gli esperimenti hanno rivelato sia promesse sia limiti. All'aumentare della dimensione del dataset e del tempo di addestramento, le prestazioni di No-QCNN sono progressivamente diminuite. Il numero fisso di qubit e la scarsa profondità del circuito significavano che il modello non poteva assorbire facilmente più dati, e il campionamento ripetuto degli stati quantistici introduceva rumore nel processo di addestramento. Eppure, in dataset piccoli e ricchi di correlazioni — in particolare il compito a sei classi con pochissime immagini per classe — il modello quantistico ha generalizzato meglio della CNN classica. In termini semplici, il circuito quantistico ha resistito alla tentazione di memorizzare le immagini di addestramento e ha invece appreso una regola che si è trasferita in modo più affidabile a nuovi esempi.
Cosa significa per il futuro
Per il non specialista, la conclusione principale è che le versioni quantistiche delle reti neurali non sono accelleratori magici per tutti i problemi di visione, né sono pronte a sostituire i sistemi di deep learning odierni. Piuttosto, questo studio individua una nicchia realistica in cui l'hardware quantistico potrebbe fare la differenza per primo: compiti su immagini minuscole e con pochi dati, dove i pattern sono sottili e i modelli classici tendono a sovradattarsi. No-QCNN dimostra che anche sulle prime piattaforme quantistiche, rumorose e limitate (simulate qui), circuiti quantistici progettati con cura possono competere con — e talvolta superare — le CNN classiche in termini di capacità di generalizzazione, sebbene con tempi di addestramento molto più lunghi. Con il progresso dei processori quantistici, che diventeranno più potenti e meno soggetti a errori, architetture come No-QCNN potrebbero evolversi in strumenti pratici per compiti visivi specialistici in medicina, telerilevamento e oltre.
Citazione: Daka, C., Bhattacharyya, S. A novel quantum convolutional neural network framework for quantum-enhanced classification of pixelated colour images. Sci Rep 16, 10828 (2026). https://doi.org/10.1038/s41598-026-45140-w
Parole chiave: apprendimento automatico quantistico, classificazione di immagini, reti neurali quantistiche, immagini a bassa risoluzione, modelli ibridi quantistico‑classici