Clear Sky Science · es
Un nuevo marco de redes neuronales convolucionales cuánticas para la clasificación mejorada por quantum de imágenes en color pixeladas
Ver más en imágenes borrosas
La vida moderna gira en torno a las imágenes, desde exploraciones médicas y fotos satelitales hasta emojis y sprites de videojuegos. Pero a medida que estas colecciones de imágenes crecen, los ordenadores que las analizan afrontan un dilema: los modelos grandes y sofisticados requieren conjuntos de datos enormes y mucha energía, mientras que muchas tareas reales deben trabajar con un puñado de imágenes pequeñas y de baja resolución. Este artículo explora si las reglas extrañas de la física cuántica pueden ayudar a los ordenadores a detectar patrones en imágenes pequeñas y ruidosas con más fiabilidad que las herramientas estándar actuales.
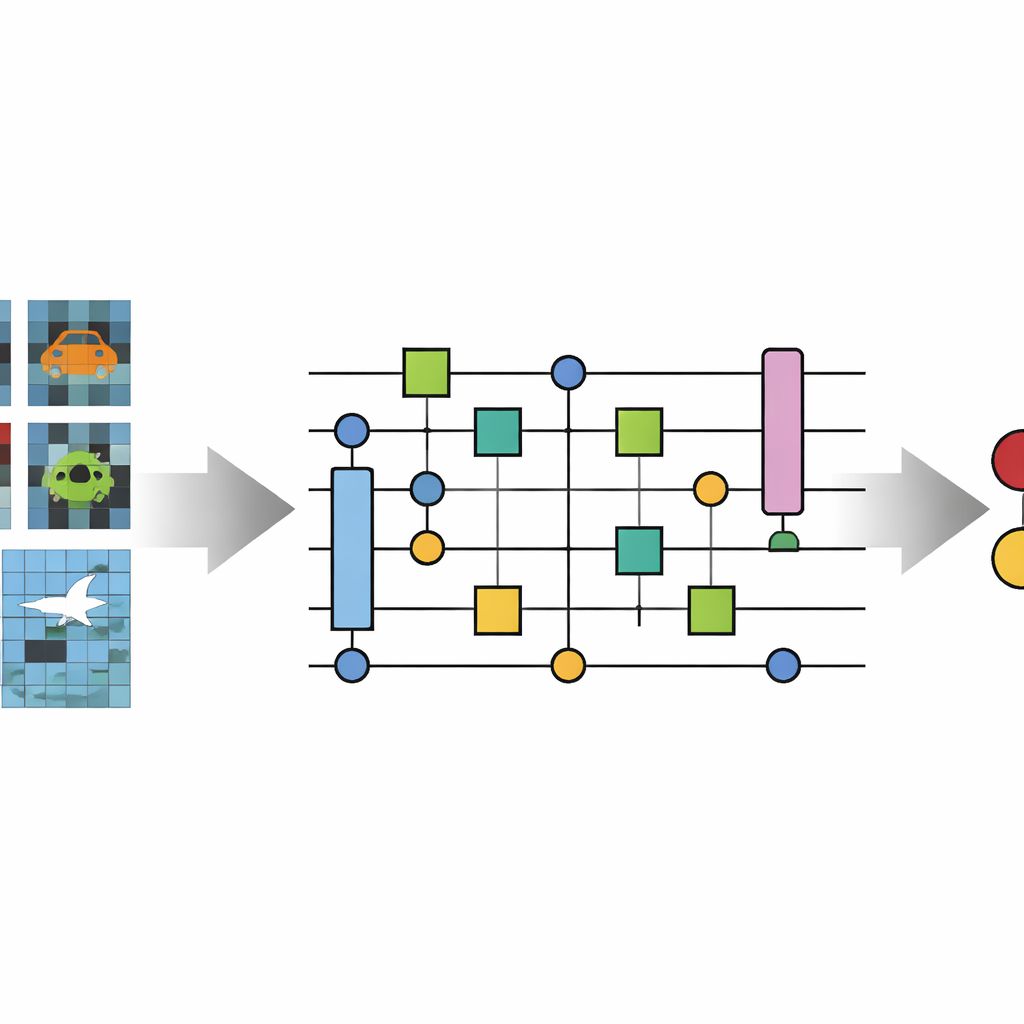
Por qué las imágenes diminutas son un gran reto
Las redes neuronales convolucionales (CNN) clásicas han transformado el reconocimiento de imágenes al escanear fotografías con filtros pequeños y aprender capas de patrones. Son excelentes con imágenes grandes y detalladas y conjuntos de datos masivos, como los usados para etiquetar fotos en internet. Sin embargo, en muchos entornos prácticos —sensores embebidos, cámaras de bajo coste, teledetección o displays de tamaño icono— solo están disponibles imágenes pequeñas de 4×4 u 8×8 píxeles, a menudo en número limitado. En este régimen de pocos datos, las CNN estándar tienden a sobreajustar: memorizan los ejemplos de entrenamiento en vez de aprender reglas generales, lo que conduce a una precisión aparentemente alta en las imágenes conocidas pero a un rendimiento pobre en nuevas muestras.
Incorporando la física cuántica a la visión
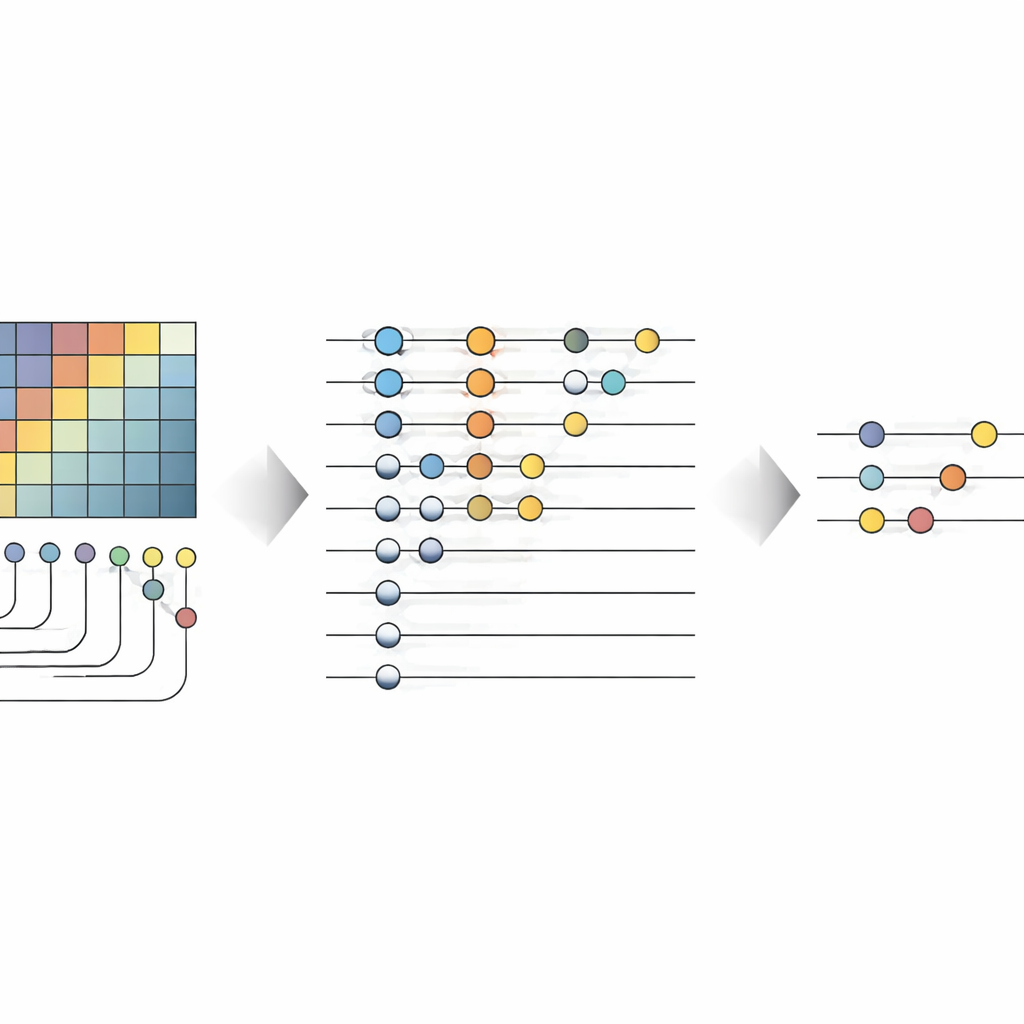
Los autores presentan la Red Neuronal Convolucional Cuántica Novel (No-QCNN), un modelo híbrido que emplea tanto un ordenador convencional como un dispositivo cuántico simulado. La idea central es representar cada imagen diminuta en color como una colección de bits cuánticos (qubits). En lugar de alimentar los valores de píxel crudos directamente a una red, el método convierte primero las intensidades rojo‑verde‑azul de cada píxel y su posición en un bloque compacto de datos tridimensional. Este bloque se codifica luego en un estado cuántico mediante rotaciones cuidadosamente elegidas y operaciones de entrelazamiento entre pares de qubits. Debido a que los qubits pueden existir en superposición y entrelazarse, un único estado cuántico puede representar de forma natural muchas combinaciones de colores y posiciones de píxeles a la vez, capturando en principio correlaciones sutiles sin redes muy profundas.
Cómo la red cuántica procesa las imágenes
Una vez que la imagen está almacenada en qubits, No-QCNN la procesa mediante una secuencia que refleja las CNN clásicas pero que se ejecuta íntegramente en un circuito cuántico. Pares de qubits pasan por bloques de transformación pequeños y repetidos que actúan como análogos cuánticos de los filtros de convolución, mezclando información de "localizaciones" vecinas en la imagen. Tras cada uno de estos pasos de "convolución" cuántica, una operación de pooling cuántico reduce el número efectivo de qubits, plegando la información de dos qubits en uno. Capa tras capa, el circuito se reduce hasta quedar sólo unos pocos qubits cuyos resultados de medición se interpretan, mediante un posprocesado clásico, como la clase predicha —por ejemplo, si una línea es horizontal o vertical, y de qué color es. Las intensidades de estas operaciones cuánticas se ajustan automáticamente usando un optimizador clásico que trata todo el conjunto como un modelo entrenable.
Comparando enfoques cuánticos y clásicos
Para evaluar el rendimiento de No-QCNN, los investigadores crearon conjuntos de datos de imágenes simples pero reveladores. En la tarea básica, cada imagen de 4×4 contenía una línea brillante horizontal o vertical contra un fondo ruidoso, constituyendo un problema de dos clases (binario). En la tarea más exigente, las imágenes de 8×8 contenían una línea que podía ser horizontal o vertical y de color rojo, verde o azul, dando lugar a seis combinaciones posibles. Para ser justos, el modelo cuántico se ejecutó en un simulador sin ruido y su rendimiento se comparó con una CNN clásica compacta de complejidad similar. En la tarea binaria, la CNN clásica alcanzó una precisión de validación perfecta, mientras que No-QCNN llegó a alrededor del 90 %, mostrando que para problemas sencillos con estructura clara, el enfoque convencional aún tiene ventaja. Sin embargo, en el problema de seis clases con solo 50 imágenes, la situación cambió: No-QCNN alcanzó una precisión de validación de aproximadamente el 82 %, mientras que la CNN clásica cayó al 40 %, señal de un fuerte sobreajuste.
Dónde la visión cuántica ayuda más
Los experimentos revelaron tanto promesas como límites. A medida que los autores aumentaron el tamaño del conjunto de datos y el tiempo de entrenamiento, el rendimiento de No-QCNN disminuyó gradualmente. El número fijo de qubits y la poca profundidad del circuito implicaban que el modelo no podía absorber fácilmente más datos, y el muestreo repetido de estados cuánticos introdujo ruido en el proceso de entrenamiento. Aun así, en conjuntos de datos pequeños y ricos en correlaciones —especialmente la tarea de seis clases con muy pocas imágenes por clase— el modelo cuántico generalizó mejor que la CNN clásica. En términos sencillos, el circuito cuántico resistió la tentación de memorizar las imágenes de entrenamiento y, en su lugar, aprendió una regla que se transfirió con más fiabilidad a ejemplos nuevos.
Qué significa esto para el futuro
Para un lector no especializado, la conclusión principal es que las versiones cuánticas de redes neuronales no son aceleradores mágicos para todos los problemas de imágenes, ni están listas para reemplazar los sistemas de aprendizaje profundo actuales. En cambio, este estudio identifica un nicho realista donde el hardware cuántico podría importar primero: tareas de imágenes diminutas y con pocos datos donde los patrones son sutiles y los modelos clásicos se sobreajustan fácilmente. No-QCNN demuestra que incluso en las primeras plataformas cuánticas ruidosas (simuladas aquí), los circuitos cuánticos diseñados con cuidado pueden competir con —y a veces superar— a las CNN clásicas en capacidad de generalización, aunque con tiempos de entrenamiento mucho más largos. A medida que los procesadores cuánticos se vuelvan más potentes y menos propensos a errores, arquitecturas como No-QCNN podrían evolucionar hasta convertirse en herramientas prácticas para tareas visuales especializadas en medicina, teledetección y otros ámbitos.
Cita: Daka, C., Bhattacharyya, S. A novel quantum convolutional neural network framework for quantum-enhanced classification of pixelated colour images. Sci Rep 16, 10828 (2026). https://doi.org/10.1038/s41598-026-45140-w
Palabras clave: aprendizaje automático cuántico, clasificación de imágenes, redes neuronales cuánticas, imágenes de baja resolución, modelos híbridos cuántico‑clásicos