Clear Sky Science · ar
إطار شبكة عصبية تلافيفية كمية جديد لتصنيف معزز كميًا للصور الملونة المبعثرة بالبكسل
رؤية أعمق في الصور الضبابية
الحياة الحديثة تعتمد على الصور، من المسح الطبي وصور الأقمار الصناعية إلى الرموز التعبيرية ورسومات ألعاب الفيديو. لكن مع تزايد مجموعات الصور هذه، تواجه الحواسيب التي تحللها معضلة: النماذج الكبيرة والمتطورة تحتاج إلى مجموعات بيانات هائلة وكثيرًا من الطاقة، بينما يجب على العديد من المهام الحقيقية أن تعمل مع عدد قليل فقط من الصور الصغيرة منخفضة الدقة. تستكشف هذه الورقة ما إذا كانت قواعد الفيزياء الكمومية الغريبة يمكن أن تساعد الحواسيب في اكتشاف الأنماط في مثل هذه الصور الصغيرة والصاخبة بشكل أكثر موثوقية من الأدوات القياسية الحالية.
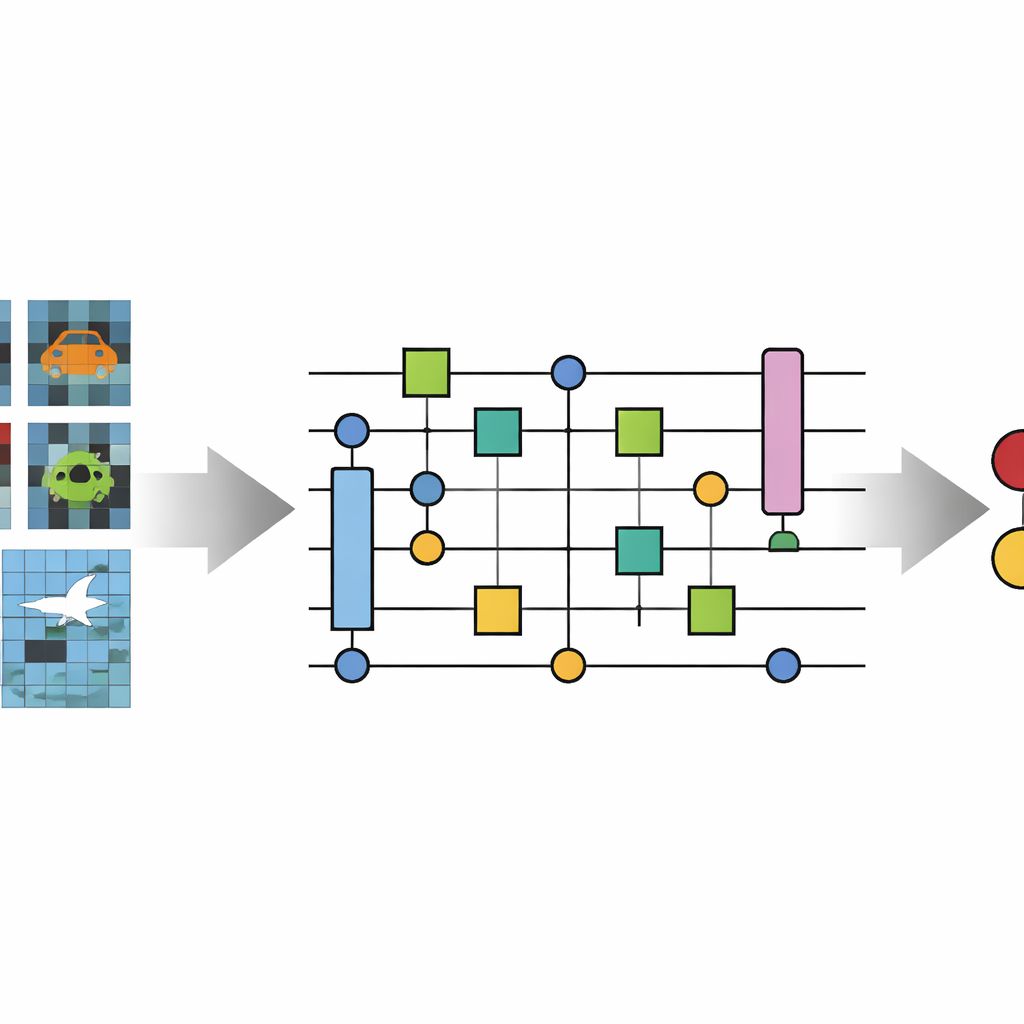
لماذا الصور الصغيرة تمثل تحديًا كبيرًا
حوّلت الشبكات العصبية التلافيفية (CNNs) التقليدية مجال تمييز الصور عبر مسح الصور بمرشحات صغيرة وتعلّم طبقات من الأنماط. تتفوق هذه الشبكات على الصور الكبيرة المفصّلة وعلى مجموعات البيانات الضخمة، مثل تلك المستخدمة في تمييز صور الإنترنت. ومع ذلك، في العديد من الحالات العملية—المستشعرات المدمجة، الكاميرات منخفضة التكلفة، الاستشعار عن بُعد، أو الشاشات بحجم أيقونة—تتوفر صور صغيرة فقط بحجم 4×4 أو 8×8 بيكسل، وغالبًا بأعداد محدودة. في هذا النطاق المنخفض البيانات، تميل شبكات الـCNN القياسية إلى الإفراط في التكيّف: فهي تحفظ أمثلة التدريب بدلًا من تعلّم قواعد عامة، مما يؤدي إلى دقة عالية على الصور المعروفة ولكن أداء ضعيف على أمثلة جديدة.
إدخال الفيزياء الكمومية في رؤية الحاسوب
يقدّم المؤلفون إطار شبكة عصبية تلافيفية كمية جديدة (No-QCNN)، وهو نموذج هجين يستخدم كلًا من حاسب تقليدي وجهاز كمي مُحاكَى. الفكرة الأساسية هي تمثيل كل صورة ملونة صغيرة كمجموعة من وحدات الكيوبتات (qubits). بدلًا من إدخال قيم البكسل الخام مباشرة في شبكة، يحوّل الأسلوب أولًا شدة الأحمر–الأخضر–الأزرق لكل بكسل وموقعه إلى كتلة بيانات ثلاثية الأبعاد مدمجة. تُشفَّر هذه الكتلة بعد ذلك في حالة كمومية باستخدام تدويرّات مُختارة بعناية وعمليات تشابك بين أزواج من الكيوبتات. وبما أن الكيوبتات يمكن أن توجد في حالات تراكب وتتشابك، فإن حالة كمومية واحدة يمكن أن تمثّل طبيعيًا العديد من تراكيبات ألوان البكسل ومواضعها دفعةً واحدة، مما يمكّن من التقاط الارتباطات الدقيقة دون شبكات عميقة جدًا.
كيف تعالج الشبكة الكمومية الصور
بعد تخزين الصورة في الكيوبتات، تعالج No-QCNN الصورة من خلال سلسلة تحاكي شبكات الـCNN الكلاسيكية لكنها تعمل بالكامل على دائرة كمية. تخضع أزواج الكيوبتات لكتل تحويل صغيرة ومكررة تعمل كتماثلات كمية لمرشحات الالتفاف، تمزج المعلومات من "المواقع" المجاورة في الصورة. بعد كل خطوة "التفاف" كمية، تقلل عملية تجميع كمية عدد الكيوبتات الفعّال، وتطوي المعلومات من كوبتَين إلى واحد. طبقة بعد طبقة، يضيق الدائرة لتصل إلى عدد قليل من الكيوبتات التي تُقاس نتائجها، وتُفسَّر عبر خطوة ما بعد المعالجة الكلاسيكية كالفئة المتوقعة—مثلما إذا كان الخط أفقيًا أم عموديًا، وما لونه. تُضبَط معاملات هذه العمليات الكمومية تلقائيًا باستخدام مُحسّن كلاسيكي يتعامل مع الإعداد بأكمله كنموذج قابل للتدريب.
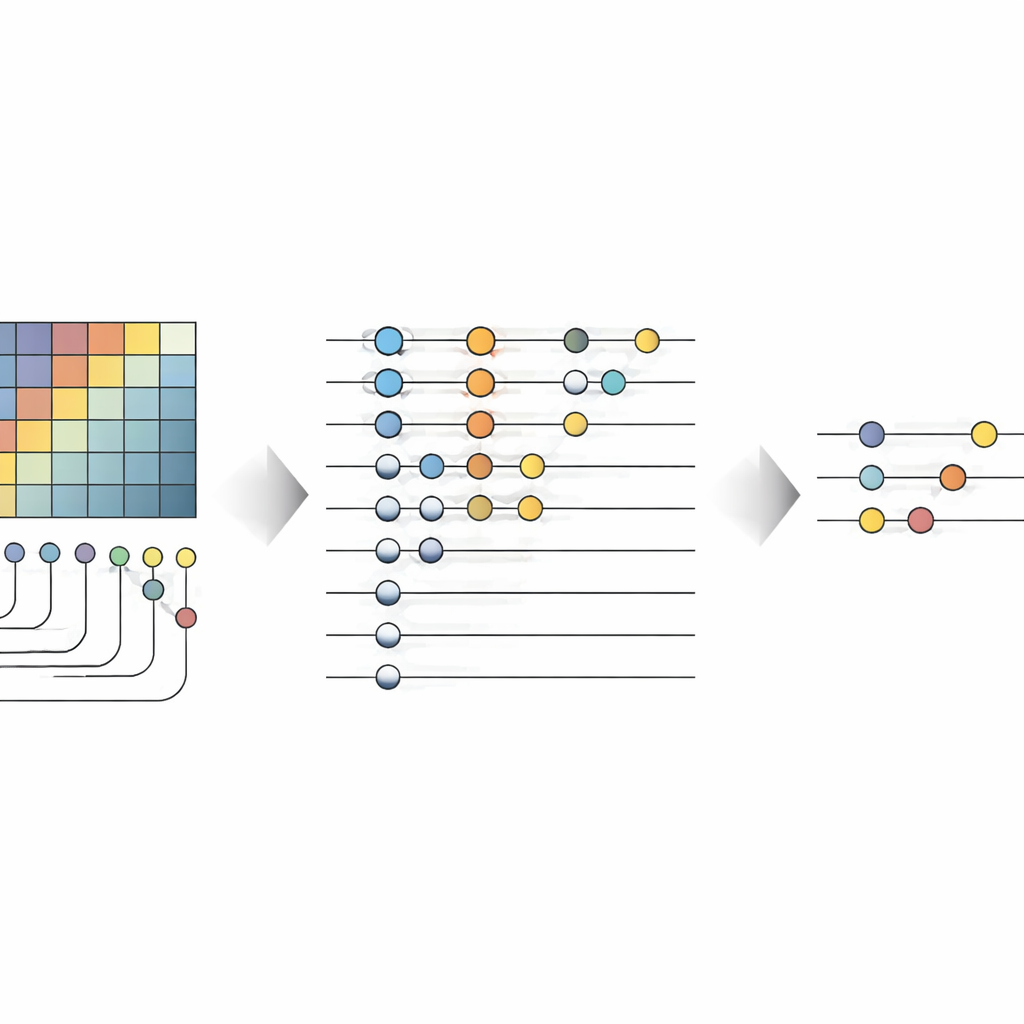
اختبار المقاربات الكمومية مقابل الكلاسيكية
لاختبار أداء No-QCNN، أنشأ الباحثون مجموعات بيانات بسيطة لكنها موضّحة. في المهمة الأساسية، احتوت كل صورة 4×4 على خط ساطع إما أفقي أو عمودي مقابل خلفية صاخبة، مشكلة ثنائية الفئة. في المهمة الأكثر تطلّبًا، احتوت صور 8×8 على خط قد يكون أفقيًا أو عموديًا وملونًا بالأحمر أو الأخضر أو الأزرق، مما ينتج ست تراكيب ممكنة. للمقارنة العادلة، شغّل النموذج الكمومي على محاكي خالٍ من الضوضاء، وقورن بأداء شبكة CNN كلاسيكية مدمجة ذات تعقيد مشابه. في المهمة الثنائية، حققت شبكة الـCNN الكلاسيكية دقة تحقق مثالية، بينما وصلت No-QCNN إلى نحو 90%، مما يبيّن أن النهج التقليدي لا يزال متفوقًا في المسائل البسيطة الواضحة البنية. أما في مهمة الست فئات الأغنى مع 50 صورة فقط، فقد انقلب الوضع: حققت No-QCNN دقة تحقق نحو 82%، بينما انخفض أداء شبكة الـCNN الكلاسيكية إلى 40%، وهو علامة على الإفراط القوي في التكيّف.
أين تفيد الرؤية الكمومية أكثر
كشفت التجارب عن وعود وحدود معًا. مع زيادة حجم مجموعة البيانات ووقت التدريب، تراجعت أداء No-QCNN تدريجيًا. العدد الثابت للكيوبتات وعمق الدائرة السطحي جعل النموذج غير قادر بسهولة على استيعاب بيانات أكثر، كما أن أخذ عينات متكررة من الحالات الكمومية أدخل ضوضاء في عملية التدريب. ومع ذلك، في مجموعات البيانات الصغيرة الغنية بالارتباطات—وخاصة مهمة الست فئات مع عدد قليل جدًا من الصور لكل فئة—عممت النموذج الكمومي أفضل من شبكة الـCNN الكلاسيكية. ببساطة، قاومت الدائرة الكمومية إغراء حفظ صور التدريب وتعلّمت بدلاً من ذلك قاعدة انتقلت إلى أمثلة جديدة بمزيد من الاعتمادية.
ماذا يعني هذا للمستقبل
بالنسبة للقارئ غير المتخصص، الخلاصة أن النسخ الكمومية من الشبكات العصبية ليست مسرعات سحرية لكل مشكلات الصور، ولا هي جاهزة لاستبدال أنظمة التعلم العميق الحالية. بل تحدد هذه الدراسة مجالًا واقعيًا قد تكون فيه الأجهزة الكمومية مفيدة أولًا: مهام صور صغيرة وقليلة البيانات حيث تكون الأنماط رفيعة والحلول الكلاسيكية تعاني من الإفراط في التكيّف. تُظهر No-QCNN أنه حتى على المنصات الكمومية المبكرة والصاخبة اليوم (المحاكاة هنا)، يمكن أن تتنافس الدوائر الكمومية المصممة بعناية مع شبكات الـCNN الكلاسيكية—وأحيانًا تتفوّق عليها—في التعميم، وإن كان ذلك مع أوقات تدريب أطول بكثير. مع تطور المعالجات الكمومية لتصبح أكثر قوة وأقل عرضة للأخطاء، قد تتطور هندسات مثل No-QCNN إلى أدوات عملية لمهام بصرية متخصصة في الطب والاستشعار عن بُعد وما بعدها.
الاستشهاد: Daka, C., Bhattacharyya, S. A novel quantum convolutional neural network framework for quantum-enhanced classification of pixelated colour images. Sci Rep 16, 10828 (2026). https://doi.org/10.1038/s41598-026-45140-w
الكلمات المفتاحية: تعلم الآلة الكمي, تصنيف الصور, الشبكات العصبية الكمومية, الصور منخفضة الدقة, نماذج هجينة كمية‑كلاسيكية