Clear Sky Science · pl
Kalibrowane względem wariancji międzyosobowe bootstrapowanie dla neurobiologii z małymi próbkami
Dlaczego warto osiągać więcej przy mniejszej liczbie danych
Wiele współczesnych eksperymentów dotyczących mózgu i zachowania opiera się na zaledwie kilku zwierzętach lub ludziach, mimo że każdy uczestnik dostarcza setek pomiarów. Ta nierównowaga — niewielu osobników, wiele prób — powoduje, że wyciąganie wiarygodnych wniosków jest zaskakująco trudne. Artykuł przedstawia nowy sposób ponownego wykorzystania i zrównoważenia takich danych, dzięki któremu badacze mogą uzyskać godne zaufania odpowiedzi bez konieczności stałego zwiększania liczby badanych, co ma kluczowe znaczenie, gdy eksperymenty są kosztowne, trudne lub budzą kwestie etyczne.
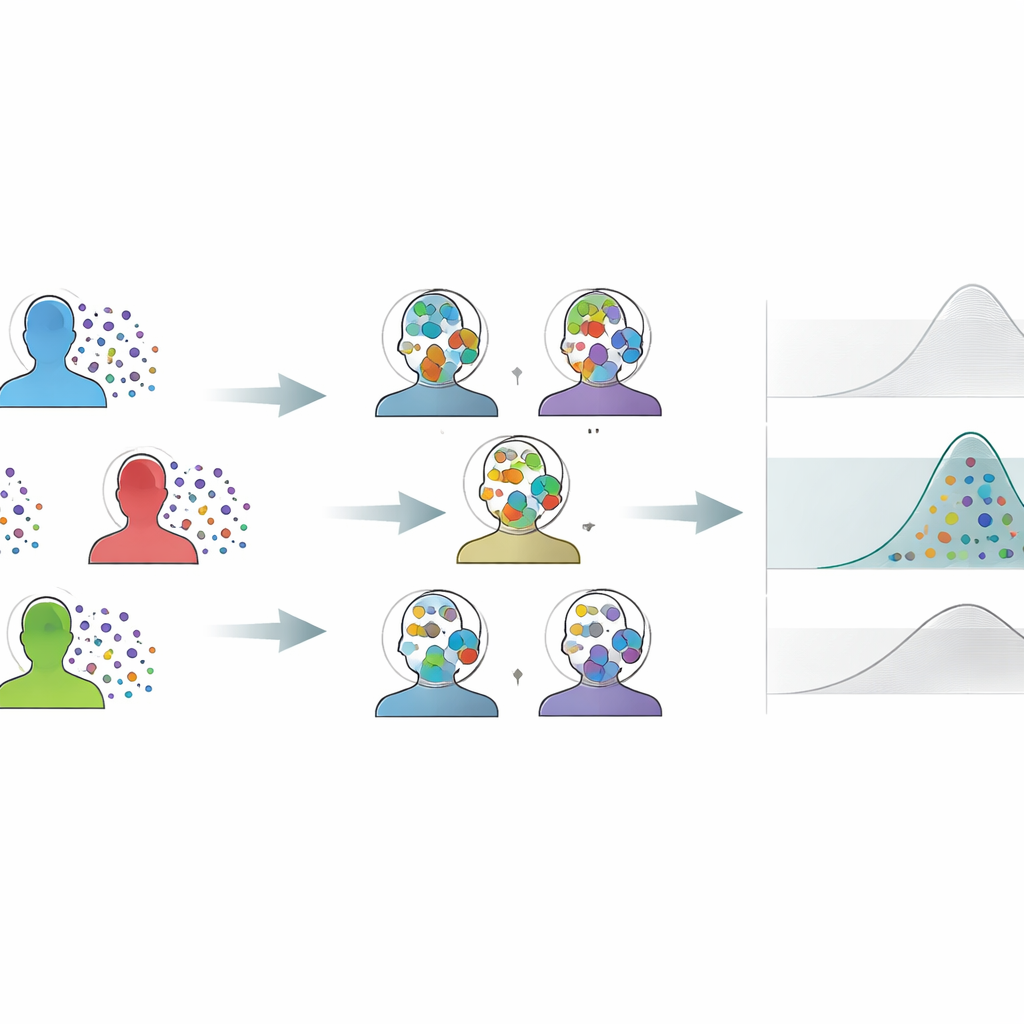
Problem małych grup i zaszumionych pomiarów
Neuronauki, psychologia, biomechanika i pokrewne dziedziny często badają niewielką liczbę uczestników, ale rejestrują wiele powtarzanych odpowiedzi od każdego z nich. Tradycyjne analizy zwykle sprowadzają te powtórzenia do pojedynczej średniej na osobnika, pozostawiając tylko kilka punktów danych reprezentujących cały eksperyment. To sprawia, że estymaty są niestabilne, rośnie szansa przeoczenia prawdziwych efektów i przyczynia się do niepowtarzalnych wyników. Standardowe triki z ponownym próbkowaniem — jak wielokrotne przetasowywanie danych w celu oszacowania niepewności — również mają tu problemy: jedno popularne podejście bywa zbyt optymistyczne, dając przedziały ufności zbyt wąskie, podczas gdy inne gra bezpiecznie, generując przedziały tak szerokie, że subtelne, lecz rzeczywiste efekty giną w szumie.
Nowy sposób łączenia i dopasowywania informacji
Autor proponuje Kalibrowane względem wariancji Międzyosobowe Bootstrapowanie (Variance-Calibrated Cross-Individual Bootstrapping, CIB-VC) jako praktyczne rozwiązanie. Zamiast ponownie pobierać próby oddzielnie dla każdego uczestnika, metoda tworzy „syntetycznych osobników” przez łączenie pojedynczych prób losowanych od każdego uczestnika. Każdy syntetyczny osobnik jest złożonym obrazem całej grupy, co wygładza kłopotliwą dyskretność pojawiającą się przy niewielkiej liczbie realnych osobników do przetasowywania. Jednak takie mieszanie normalnie zmniejsza pozorne różnice między osobami. Aby to naprawić, CIB-VC wprowadza krok kalibracji, który rozciąga zmienność tych syntetycznych osobników tak, aby odpowiadała rzeczywistej wariacji obserwowanej między prawdziwymi uczestnikami. Końcowy efekt to zestaw przedziałów niepewności, które właściwie odzwierciedlają, o ile indywidualnie rzeczywiście się różnią, przy jednoczesnym pełnym wykorzystaniu bogatych danych na poziomie prób.
Testowanie metody
Aby sprawdzić, czy CIB-VC działa w praktyce, badanie używa dużych symulacji naśladujących typowe rodzaje danych naukowych: rozkłady dzwonowe, o grubych ogonach z okazjonalnymi wartościami ekstremalnymi oraz silnie skośne, jak czasy reakcji czy częstości wyładowań. Metoda była też testowana pod kątem niedopasowań, które często występują w prawdziwych laboratoriach, takich jak powolne dryfy w czasie czy uczestnicy nagrywani z różnymi poziomami szumu. We wszystkich tych scenariuszach CIB-VC konsekwentnie dostarcza przedziały ufności, które zawierają prawdziwą wartość w około 95 procentach przypadków — dokładnie tak, jak zostały zaprojektowane. Dla porównania, jedno standardowe podejście często zawodzi, zwłaszcza gdy dane są skośne i obciążone, dając mylnie wąskie przedziały, które prawie nigdy nie zawierają prawdy. Drugie standardowe podejście zachowuje się jak ostrożny sędzia — rzadko się myli, ale często jest tak konserwatywne, że jego przedziały zbliżają się do całego możliwego zakresu.
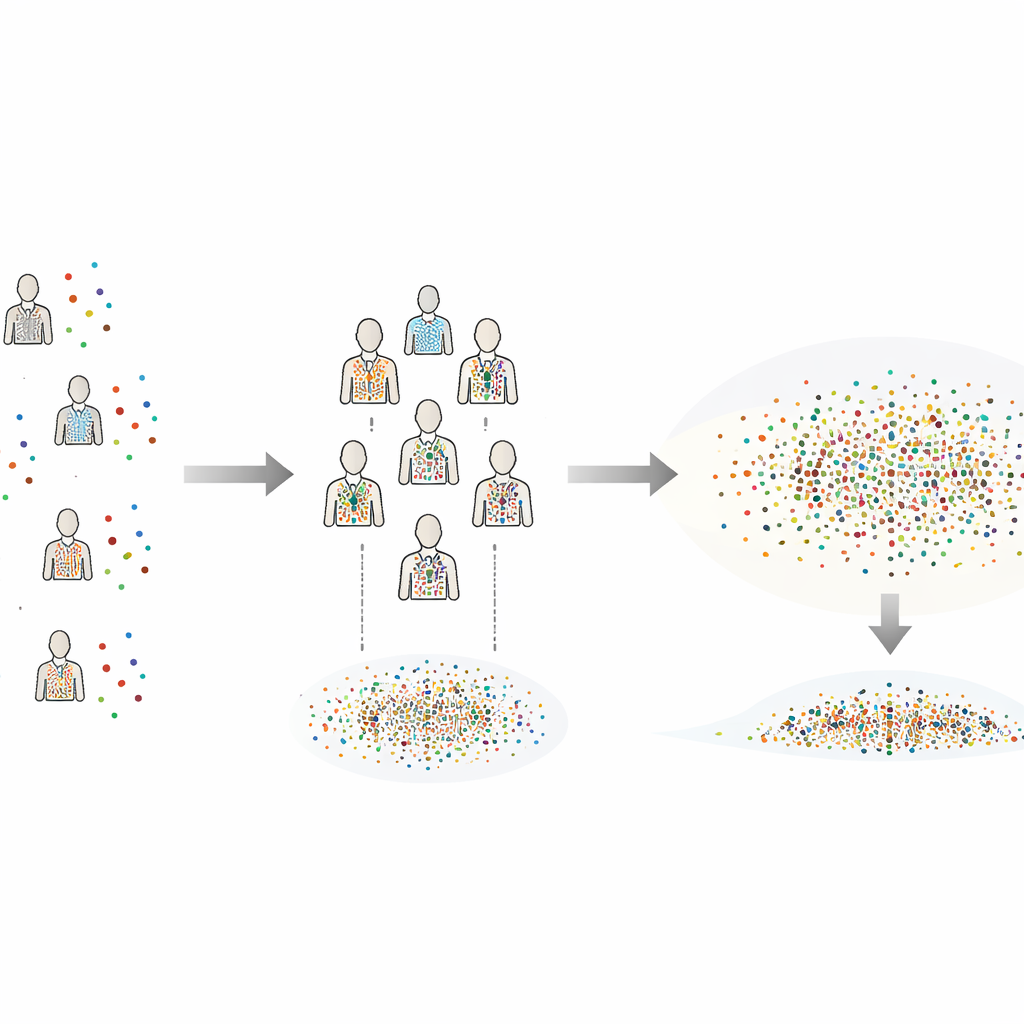
Od symulacji do prawdziwych zwierząt
Metoda została następnie zastosowana do klasycznego eksperymentu z małą próbką w neurobiologii: zadania śledzenia wykonanego przez pięć słabo elektrycznych ryb. Każda ryba wykonała wiele prób w różnych warunkach oświetlenia, a pytanie dotyczyło, jak poziom światła wpływa na wydajność śledzenia. Na tych samych danych CIB-VC i standardowa konserwatywna metoda zgodziły się co do średniego efektu, ale CIB-VC wygenerowało przedziały ufności około 23 procent węższe, bez zwiększenia obciążenia czy liczby fałszywych alarmów. Oznacza to, że badacze mogą precyzyjniej oszacować wielkość efektu bez testowania większej liczby osobników. Dodatkowe kontrole wykazały, że estymaty metody stabilizują się szybko po wygenerowaniu większej liczby syntetycznych osobników i że rozsądne ustawienia można łatwo obsłużyć na komputerze stacjonarnym.
Co to oznacza dla przyszłych badań
Dla czytelników spoza statystyki główny przekaz jest taki, że sprytne ponowne wykorzystanie istniejących danych może pomóc pogodzić względy etyczne, koszty i rygor naukowy. CIB-VC daje sposób przekształcenia wielu zaszumionych, powtarzanych pomiarów od kilku osobników w wiarygodne wnioski na poziomie populacji, przy jednoczesnym kontrolowaniu liczby wyników fałszywie pozytywnych. Unika fałszywego poczucia pewności wynikającego z nadmiernie wąskich przedziałów, ale także uchyla się od pesymizmu podejść wymagających znacznie większych próbek. Ponieważ małe i wyspecjalizowane badania pozostają normą w wielu obszarach badań nad mózgiem i zachowaniem, narzędzia takie jak CIB-VC oferują praktyczną drogę do bardziej powtarzalnej nauki bez konieczności stałego zwiększania liczby uczestników.
Cytowanie: Uyanik, I. Variance-calibrated cross-individual bootstrapping for small-sample neuroscience. Sci Rep 16, 14502 (2026). https://doi.org/10.1038/s41598-026-44126-y
Słowa kluczowe: neuronauka na małych próbkach, ponowne próbkowanie bootstrap, dane hierarchiczne, moc statystyczna, powtarzalność