Clear Sky Science · de
Varianzkalibrierte cross-individuelle Bootstrapping-Methode für Neurowissenschaften mit kleinen Stichproben
Warum es wichtig ist, mit weniger Daten mehr zu erreichen
Viele moderne Gehirn‑ und Verhaltensstudien arbeiten nur mit einer Handvoll Tiere oder Personen, obwohl jeder einzelne Hunderte Messwerte beiträgt. Dieses Ungleichgewicht – wenige Individuen, viele Versuche – macht es überraschend schwer, verlässliche Schlussfolgerungen zu ziehen. Die Arbeit stellt eine neue Methode vor, um solche Daten sinnvoll wiederzuverwenden und auszugleichen, sodass Forschende vertrauenswürdige Antworten erhalten können, ohne stets mehr Versuchspersonen zu benötigen – besonders wichtig, wenn Experimente teuer, schwierig oder ethisch sensibel sind.
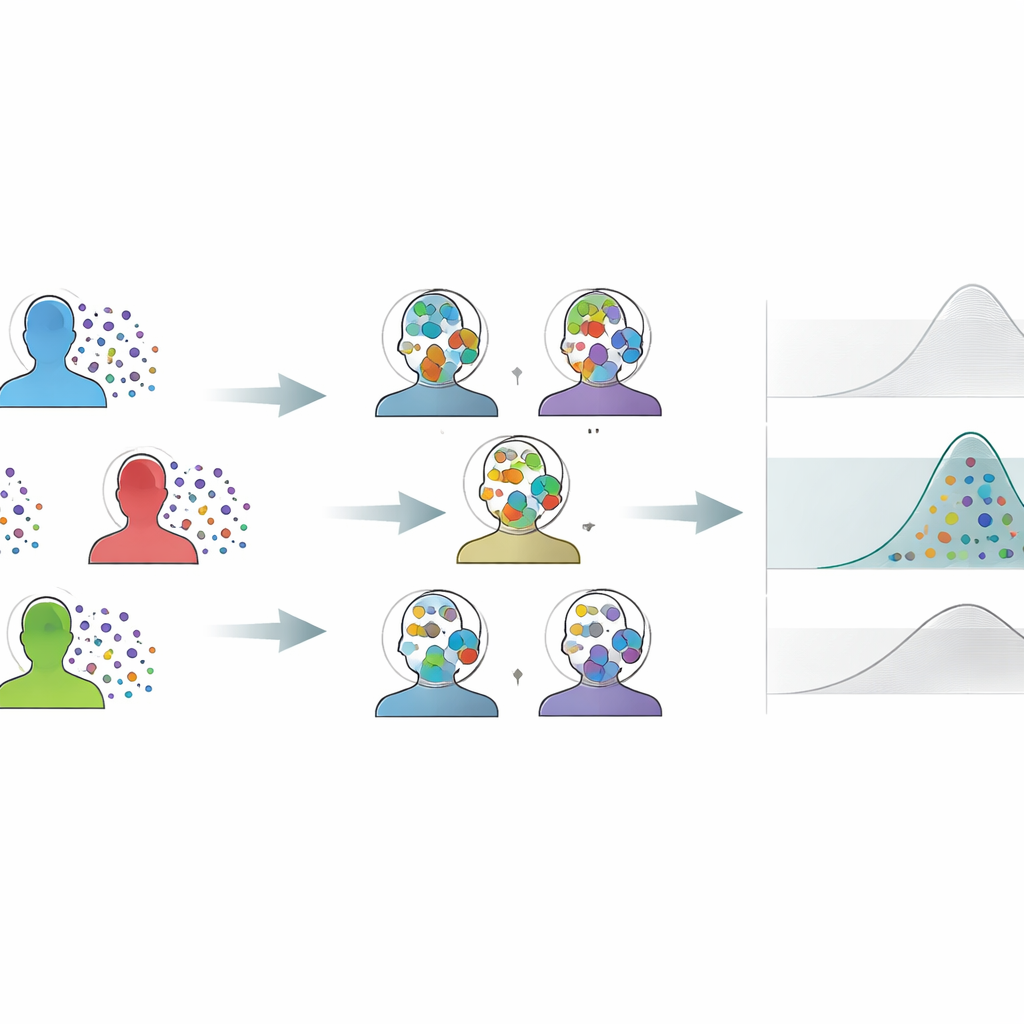
Die Herausforderung winziger Gruppen und lauter Messungen
Neurowissenschaften, Psychologie, Biomechanik und verwandte Felder untersuchen oft nur eine kleine Zahl von Teilnehmenden, erfassen aber viele wiederholte Antworten pro Person. Konventionelle Analysen verdichten diese Wiederholungen meist zu einem einzigen Mittelwert pro Subjekt und hinterlassen damit nur wenige Datenpunkte, die ein ganzes Experiment repräsentieren. Das macht Schätzungen instabil, erhöht die Wahrscheinlichkeit, echte Effekte zu übersehen, und trägt zu nicht reproduzierbaren Ergebnissen bei. Standard‑Resampling‑Tricks – etwa wiederholtes Zufallsziehen zur Abschätzung von Unsicherheit – stoßen hier ebenfalls an Grenzen: Ein verbreiteter Ansatz ist tendenziell zu optimistisch und liefert zu enge Konfidenzbereiche, während ein anderer sehr konservativ vorgeht und Bereiche erzeugt, die so breit sind, dass subtile, aber echte Effekte im Rauschen verschwinden.
Ein neuer Weg, Informationen zu mischen
Der Autor schlägt die varianzkalibrierte Cross‑Individual Bootstrapping‑Methode (CIB‑VC) als praktikable Lösung vor. Anstatt die Versuche jedes Subjekts isoliert neu zu sampeln, erzeugt die Methode „synthetische Individuen“, indem einzelne Trials aus allen Subjekten kombiniert werden. Jedes synthetische Individuum ist ein gemischtes Abbild der gesamten Gruppe, wodurch die unangenehme Diskretheit geglättet wird, die entsteht, wenn nur wenige reale Individuen zum Shuffeln zur Verfügung stehen. Dieses Vermischen würde allerdings normalerweise die scheinbaren Unterschiede zwischen Subjekten verkleinern. Um das zu korrigieren, fügt CIB‑VC einen Kalibrierungsschritt hinzu, der die Variabilität der synthetischen Individuen so streckt, dass sie der tatsächlichen Variation zwischen den realen Subjekten entspricht. Das Endergebnis sind Unsicherheitsbereiche, die korrekt widerspiegeln, wie stark sich Individuen wirklich unterscheiden, während die reichhaltigen Trial‑Daten vollständig genutzt werden.
Die Methode auf die Probe gestellt
Um zu prüfen, ob CIB‑VC in der Praxis funktioniert, verwendet die Studie groß angelegte Simulationen, die gängige Datenarten nachbilden: glockenförmige Verteilungen, schwere Schwanzverteilungen mit gelegentlichen Extremwerten und stark schiefe Verteilungen wie Reaktionszeiten oder Feuerraten. Die Methode wird außerdem mit Realitätsabweichungen belastet, die in Laboren oft vorkommen, etwa langsame Drifts über die Zeit oder Subjekte mit unterschiedlichen Rauschpegeln. In all diesen Szenarien liefert CIB‑VC konstant Konfidenzbereiche, die den wahren Wert in etwa 95 Prozent der Fälle einschließen – genau das, wofür sie ausgelegt sind. Im Gegensatz dazu versagt eine Standardmethode häufig, insbesondere bei schiefen oder verzerrten Daten, indem sie trügerisch enge Bereiche produziert, die fast nie die Wahrheit enthalten. Die andere Standardmethode verhält sich wie ein vorsichtiger Schiedsrichter: selten falsch, aber oft so konservativ, dass ihre Bereiche den gesamten plausiblen Raum annähern.
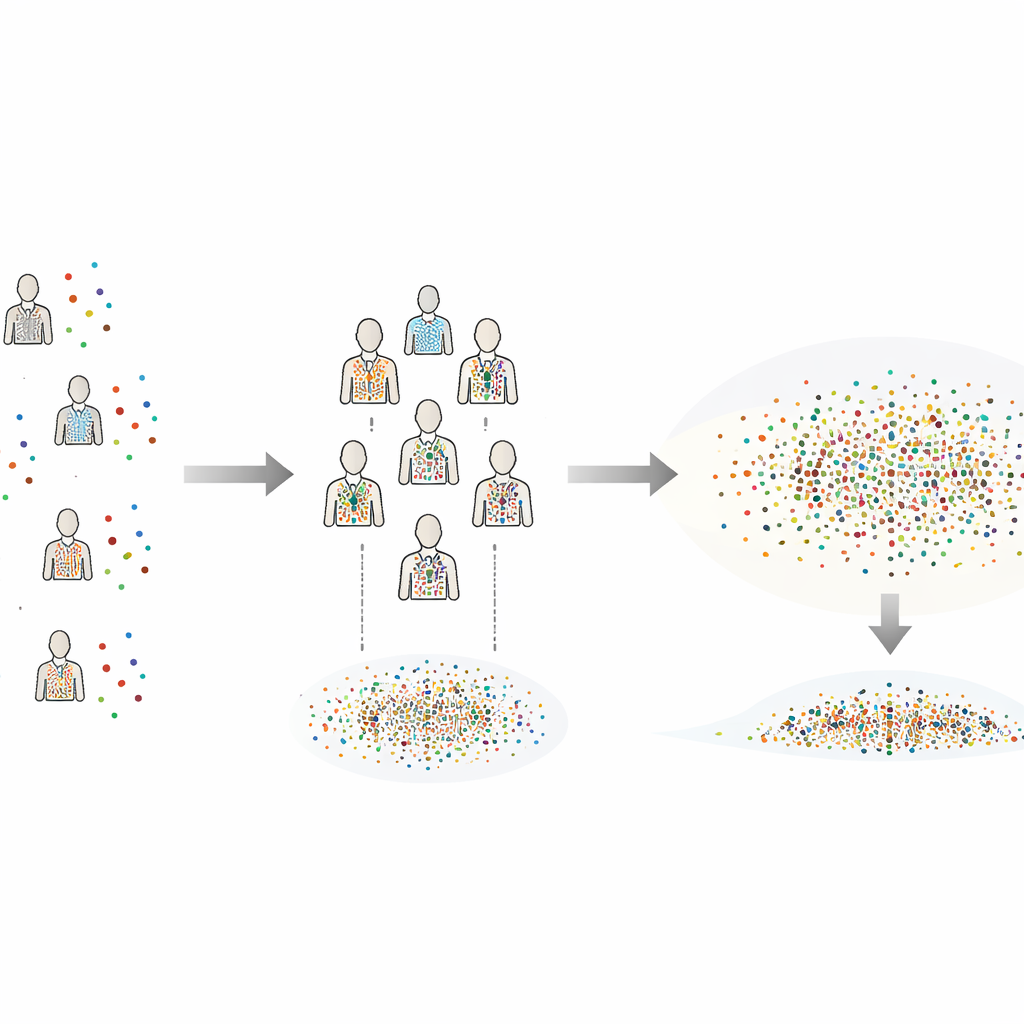
Von Simulationen zu realen Versuchstieren
Die Methode wird anschließend auf ein klassisches Experiment mit kleiner Stichprobe angewandt: eine Tracking‑Aufgabe, die von fünf schwach elektrischen Fischen durchgeführt wurde. Jeder Fisch absolvierte mehrere Trials unter verschiedenen Beleuchtungsbedingungen, und die Frage war, wie sich der Lichtpegel auf die Tracking‑Leistung auswirkte. Bei denselben Daten stimmten CIB‑VC und eine standardmäßige konservative Methode in Bezug auf den mittleren Effekt überein, doch CIB‑VC erzeugte Konfidenzbereiche, die etwa 23 Prozent schmaler waren, ohne Bias oder Fehlalarme zu erhöhen. Das bedeutet, Forschende können die Effektgröße genauer bestimmen, ohne mehr Tiere testen zu müssen. Weitere Kontrollen zeigten, dass die Schätzungen der Methode schnell stabilisieren, sobald mehr synthetische Individuen generiert werden, und dass sinnvolle Einstellungen leicht auf einem Desktop‑Computer handhabbar sind.
Was das für zukünftige Studien bedeutet
Für Leser außerhalb der Statistik lautet die Kernbotschaft: Clevere Wiederverwendung vorhandener Daten kann helfen, Ethik, Kosten und wissenschaftliche Strenge in Einklang zu bringen. CIB‑VC bietet einen Weg, viele verrauschte, wiederholte Messungen von wenigen Individuen in verlässliche Aussagen auf Populationsebene zu verwandeln und dabei falsch positive Ergebnisse unter Kontrolle zu halten. Die Methode vermeidet das falsche Sicherheitsgefühl, das aus zu engen Bereichen entsteht, und entgeht zugleich dem Pessimismus von Ansätzen, die wesentlich größere Stichproben verlangen. Da kleine und spezialisierte Studien in vielen Bereichen der Gehirn‑ und Verhaltensforschung weiterhin die Regel sind, bieten Werkzeuge wie CIB‑VC einen praktischen Pfad zu reproduzierbarerer Wissenschaft, ohne immer mehr Versuchspersonen zu benötigen.
Zitation: Uyanik, I. Variance-calibrated cross-individual bootstrapping for small-sample neuroscience. Sci Rep 16, 14502 (2026). https://doi.org/10.1038/s41598-026-44126-y
Schlüsselwörter: kleine Stichprobe Neurowissenschaften, Bootstrap-Resampling, hierarchische Daten, statistische Power, Reproduzierbarkeit