Clear Sky Science · fr
Bootstrap inter-individuel calibré en variance pour les neurosciences à petits échantillons
Pourquoi faire plus avec moins de données compte
De nombreuses expériences modernes sur le cerveau et le comportement utilisent seulement quelques animaux ou personnes, même si chacune fournit des centaines de mesures. Ce déséquilibre — peu d’individus, de nombreux essais — rend étonnamment difficile l’obtention de conclusions fiables. L’article présente une nouvelle façon de recycler et de rééquilibrer ce type de données afin que les chercheurs puissent obtenir des réponses dignes de confiance sans toujours avoir besoin de plus de sujets, ce qui est crucial lorsque les expériences sont coûteuses, difficiles ou sensibles sur le plan éthique.
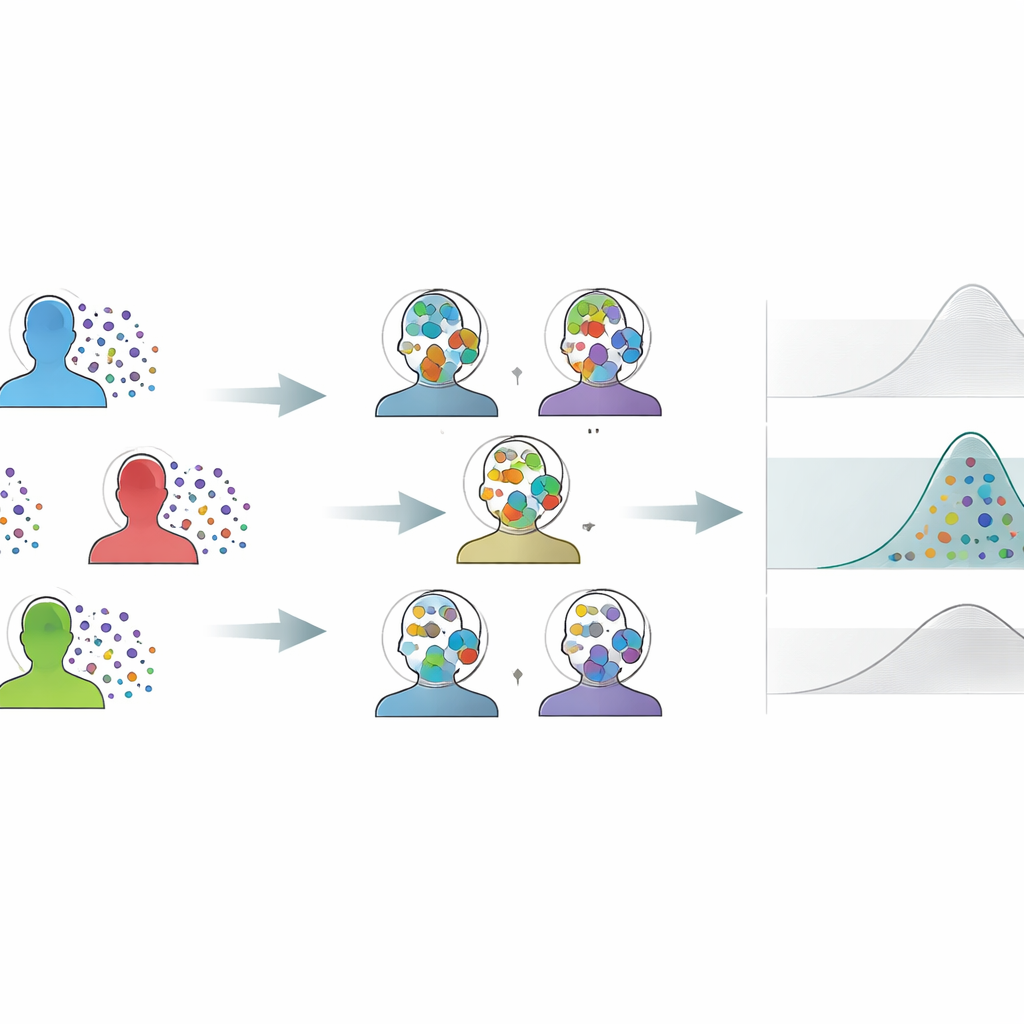
Le défi des petits groupes et des mesures bruitées
Les neurosciences, la psychologie, la biomécanique et des domaines similaires étudient souvent un petit nombre de participants, mais enregistrent de nombreuses réponses répétées par individu. Les analyses traditionnelles comprimment généralement toutes ces répétitions en une seule moyenne par sujet, ne laissant que quelques points de données pour représenter une expérience entière. Cela rend les estimations instables, augmente la probabilité de manquer des effets réels et contribue aux résultats non reproductibles. Les ruses de rééchantillonnage standard — comme le mélange répété des données pour estimer l’incertitude — peinent aussi ici : une approche populaire a tendance à être trop optimiste, fournissant des intervalles de confiance trop étroits, tandis qu’une autre joue la carte de la prudence et produit des intervalles si larges que des effets subtils mais réels disparaissent dans le bruit.
Une nouvelle façon de mélanger et associer l’information
L’auteur propose le Bootstrap Inter-Individual calibré en variance (CIB-VC) comme solution pratique. Plutôt que de rééchantillonner isolément les essais de chaque sujet, la méthode crée des « individus synthétiques » en combinant des essais uniques tirés de chaque sujet. Chaque individu synthétique est un instantané mixte du groupe entier, ce qui lisse la discrétion maladroite qui surgit quand il y a peu de sujets réels à mélanger. Cependant, ce mélange réduirait normalement les différences apparentes entre sujets. Pour corriger cela, CIB-VC ajoute une étape de calibration qui étire la variabilité de ces individus synthétiques pour correspondre à la variation réelle observée entre les sujets réels. Le résultat final est un ensemble d’intervalles d’incertitude qui reflètent correctement l’ampleur des différences individuelles, tout en exploitant pleinement les riches données au niveau des essais.
Mettre la méthode à l’épreuve
Pour vérifier si CIB-VC fonctionne en pratique, l’étude utilise des simulations à grande échelle qui imitent les types de données scientifiques courants : distributions en cloche, à longues queues avec valeurs extrêmes occasionnelles, et très asymétriques comme les temps de réaction ou les taux de décharge. La méthode est aussi testée avec des discordances fréquentes en laboratoire, telles que des dérives lentes dans le temps ou des sujets enregistrés avec des niveaux de bruit différents. À travers ces scénarios, CIB-VC fournit systématiquement des intervalles de confiance qui contiennent la valeur vraie environ 95 % du temps — exactement ce à quoi ils sont destinés. En revanche, une méthode standard échoue fréquemment, surtout lorsque les données sont biaisées et asymétriques, produisant des intervalles trompeusement serrés qui contiennent rarement la vérité. L’autre méthode standard se comporte comme un arbitre prudent : rarement fausse mais souvent tellement conservatrice que ses intervalles couvrent presque tout l’espace plausible.
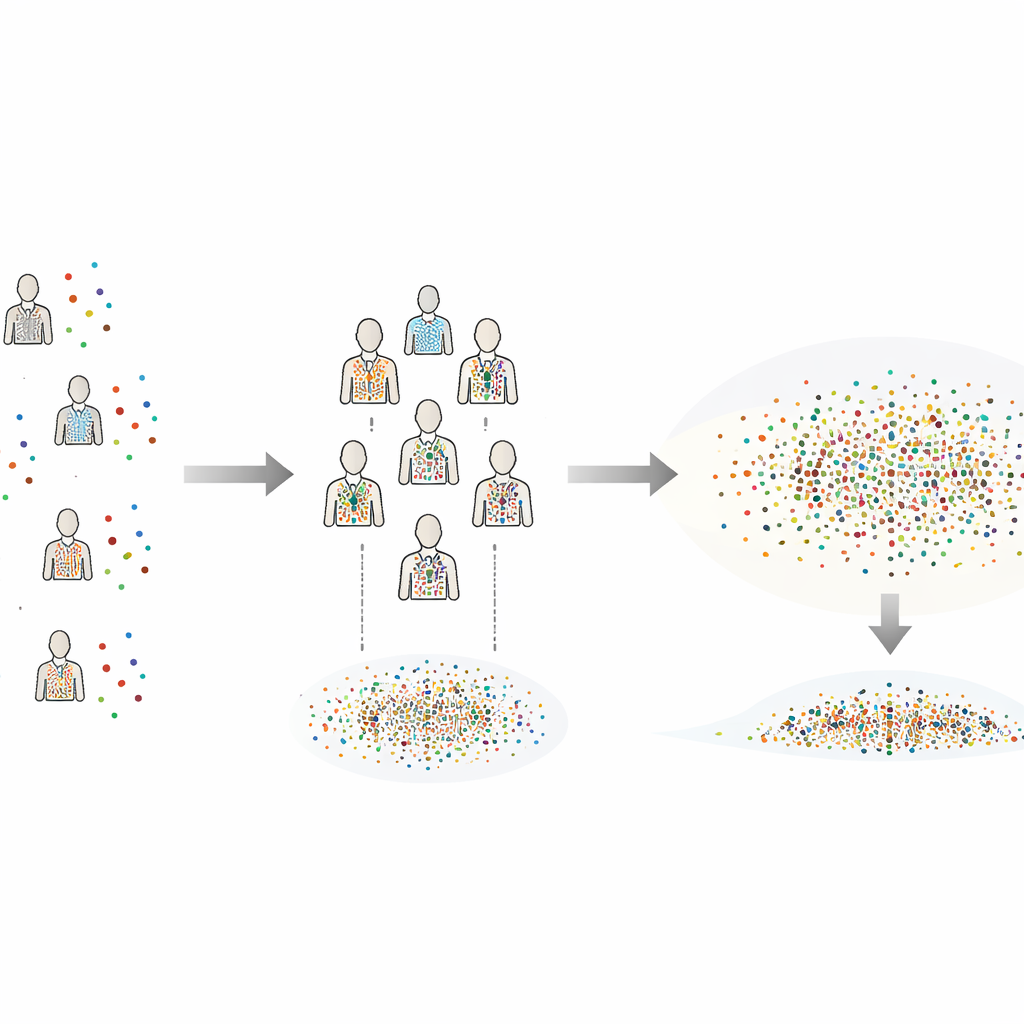
Des simulations aux animaux réels
La méthode est ensuite appliquée à une expérience classique de neurosciences à petit échantillon : une tâche de suivi réalisée par cinq poissons électriques faibles. Chaque poisson a effectué plusieurs essais sous différentes conditions d’éclairage, et la question était de savoir comment le niveau de lumière affectait la performance de suivi. Sur ces mêmes données, CIB-VC et une méthode conservatrice standard se sont accordées sur l’effet moyen, mais CIB-VC a produit des intervalles de confiance environ 23 % plus étroits sans augmenter le biais ni les faux positifs. Cela signifie que les chercheurs peuvent estimer la taille de l’effet plus précisément sans tester davantage d’animaux. Des vérifications supplémentaires ont montré que les estimations de la méthode se stabilisent rapidement à mesure que plus d’individus synthétiques sont générés, et que des paramètres raisonnables peuvent être gérés aisément par un ordinateur de bureau.
Ce que cela signifie pour les études futures
Pour les non-spécialistes en statistique, le message principal est que la réutilisation astucieuse des données existantes peut aider à concilier éthique, coût et rigueur scientifique. CIB-VC offre un moyen de transformer de nombreuses mesures bruyantes et répétées provenant de quelques individus en énoncés fiables au niveau de la population tout en gardant les faux positifs sous contrôle. Il évite le faux sentiment de certitude engendré par des intervalles trop étroits, tout en échappant au pessimisme des approches qui exigent des échantillons beaucoup plus grands. Alors que les études petites et spécialisées restent la norme dans de nombreux domaines des recherches sur le cerveau et le comportement, des outils comme CIB-VC offrent une voie pratique vers une science plus reproductible sans exiger systématiquement davantage de sujets.
Citation: Uyanik, I. Variance-calibrated cross-individual bootstrapping for small-sample neuroscience. Sci Rep 16, 14502 (2026). https://doi.org/10.1038/s41598-026-44126-y
Mots-clés: neurosciences petit échantillon, rééchantillonnage bootstrap, données hiérarchiques, puissance statistique, reproductibilité