Clear Sky Science · it
Bootstrap cross-individual calibrato per la varianza per la neuroscienza con campioni piccoli
Perché fare di più con meno dati è importante
Molti esperimenti moderni su cervello e comportamento coinvolgono solo una manciata di animali o persone, sebbene ciascuno fornisca centinaia di misurazioni. Questo sbilanciamento — pochi individui, molte prove — rende sorprendentemente difficile trarre conclusioni affidabili. L’articolo propone un nuovo modo di riciclare e riequilibrare questi dati in modo che i ricercatori possano ottenere risposte attendibili senza dover sempre aumentare il numero dei soggetti, cosa cruciale quando gli esperimenti sono costosi, complessi o eticamente delicati.
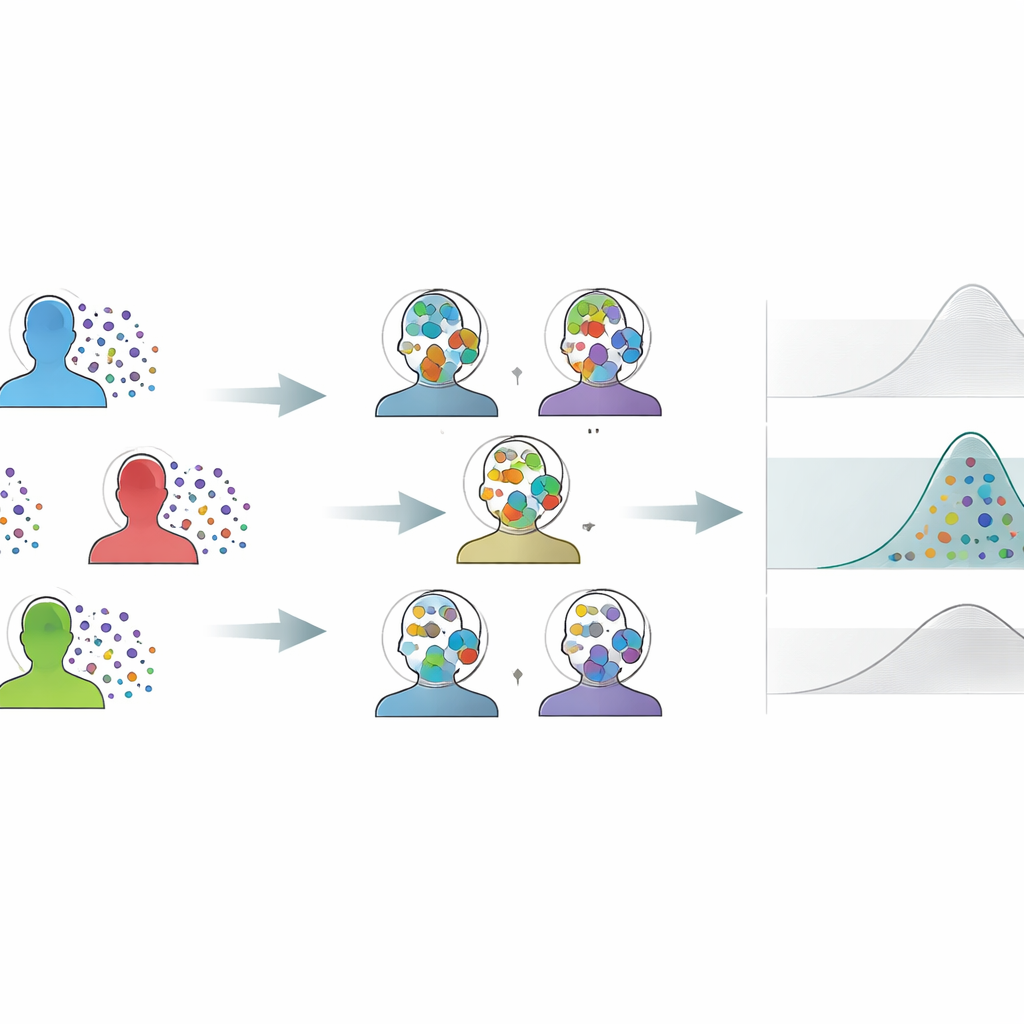
La sfida dei gruppi piccoli e delle misurazioni rumorose
La neuroscienza, la psicologia, la biomeccanica e campi affini spesso studiano un numero limitato di partecipanti, ma registrano molte risposte ripetute per ciascuno. Le analisi tradizionali in genere comprimono quelle ripetizioni in una singola media per soggetto, lasciando solo pochi punti dati a rappresentare l’intero esperimento. Questo rende le stime instabili, aumenta la probabilità di perdere effetti reali e contribuisce a risultati non riproducibili. Anche i trucchi standard di resampling — come rimescolare ripetutamente i dati per valutare l’incertezza — faticano in questi casi: un approccio popolare tende a essere troppo ottimista, producendo intervalli di confidenza troppo stretti, mentre un altro gioca sul sicuro in modo eccessivo, generando intervalli così ampi che effetti sottili ma reali scompaiono nel rumore.
Un nuovo modo di mescolare e combinare le informazioni
L’autore propone il Variance-Calibrated Cross-Individual Bootstrapping (CIB-VC) come soluzione pratica. Invece di risamplingare le prove di ciascun soggetto in isolamento, il metodo crea “individui sintetici” combinando singole prove estratte da ogni soggetto. Ogni individuo sintetico è un’istantanea composita del gruppo intero, che attenua la discrepanza che emerge quando ci sono pochi individui reali da rimescolare. Tuttavia, questa fusione tenderebbe normalmente a ridurre le differenze apparenti tra soggetti. Per correggere ciò, CIB-VC aggiunge un passaggio di calibrazione che allarga la variabilità di questi individui sintetici per farla corrispondere alla variazione reale osservata tra i soggetti veri. Il risultato finale sono intervalli di incertezza che riflettono correttamente quanto gli individui differiscono effettivamente, sfruttando pienamente i ricchi dati a livello di prova.
Mettere il metodo alla prova
Per verificare se CIB-VC funziona nella pratica, lo studio utilizza simulazioni su larga scala che riproducono tipi comuni di dati scientifici: distribuzioni a campana, code pesanti con valori estremi occasionali e fortemente asimmetriche come i tempi di reazione o i tassi di scarica. Il metodo viene anche messo sotto stress con disallineamenti che spesso si osservano nei laboratori reali, come derive lente nel tempo o soggetti registrati con livelli di rumore differenti. In tutti questi scenari, CIB-VC fornisce coerentemente intervalli di confidenza che includono il valore vero circa il 95 percento delle volte — esattamente quanto dovrebbero fare. In confronto, un metodo standard fallisce frequentemente, soprattutto quando i dati sono asimmetrici o distorti, producendo intervalli ingannevolmente stretti che quasi mai contengono la verità. L’altro metodo standard si comporta come un arbitro prudente: raramente sbaglia ma spesso è così conservativo che i suoi intervalli si avvicinano all’intero spazio plausibile.
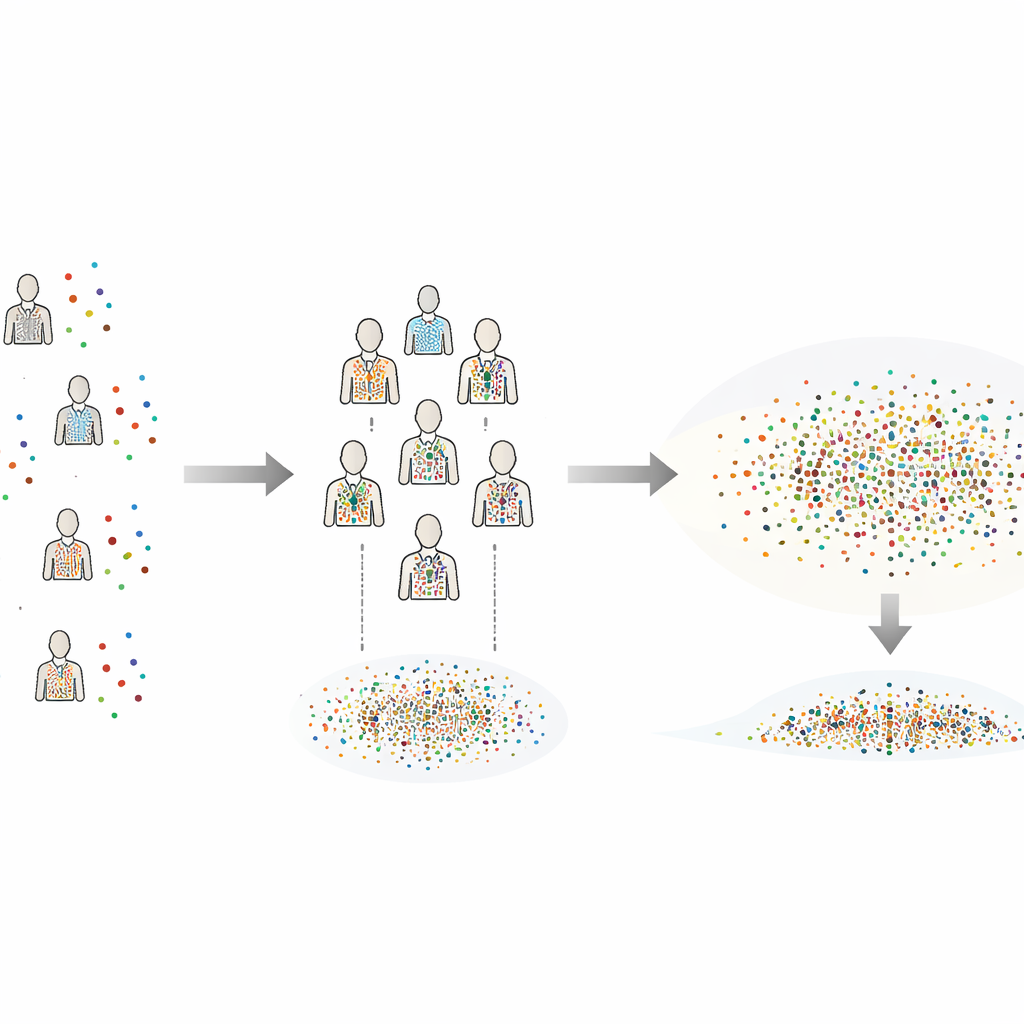
Dalle simulazioni agli animali reali
Il metodo viene poi applicato a un classico esperimento di neuroscienza con piccoli campioni: un compito di tracciamento eseguito da cinque pesci elettrici deboli. Ogni pesce ha completato più prove sotto diverse condizioni di illuminazione, e la domanda era come il livello di luce influenzasse la performance di tracciamento. Usando gli stessi dati, CIB-VC e un metodo conservativo standard hanno concordato sull’effetto medio, ma CIB-VC ha prodotto intervalli di confidenza circa il 23 percento più stretti senza aumentare bias o falsi allarmi. Ciò significa che i ricercatori possono stimare con maggiore precisione l’entità dell’effetto senza testare più animali. Controlli aggiuntivi hanno mostrato che le stime del metodo si stabilizzano rapidamente man mano che si generano più individui sintetici e che impostazioni ragionevoli sono gestibili con un computer desktop.
Cosa significa per gli studi futuri
Per i lettori non esperti di statistica, il messaggio principale è che un riuso intelligente dei dati esistenti può aiutare a bilanciare etica, costi e rigore scientifico. CIB-VC offre un modo per trasformare molte misurazioni rumorose e ripetute di pochi individui in affermazioni affidabili a livello di popolazione mantenendo il controllo sui falsi positivi. Evita il falso senso di certezza derivante da intervalli eccessivamente stretti, ma sfugge anche al pessimismo degli approcci che richiedono campioni molto più grandi. Poiché studi piccoli e specializzati rimangono la norma in molte aree della ricerca su cervello e comportamento, strumenti come CIB-VC offrono una via pratica verso una scienza più riproducibile senza dover sempre reclutare più soggetti.
Citazione: Uyanik, I. Variance-calibrated cross-individual bootstrapping for small-sample neuroscience. Sci Rep 16, 14502 (2026). https://doi.org/10.1038/s41598-026-44126-y
Parole chiave: neuroscienza con piccoli campioni, resampling bootstrap, dati gerarchici, potenza statistica, riproducibilità