Clear Sky Science · en
Variance-calibrated cross-individual bootstrapping for small-sample neuroscience
Why doing more with less data matters
Many modern brain and behavior experiments work with just a handful of animals or people, even though each one contributes hundreds of measurements. This imbalance—few individuals, many trials—makes it surprisingly hard to draw reliable conclusions. The paper introduces a new way to recycle and rebalance such data so that researchers can get trustworthy answers without always needing more subjects, which is crucial when experiments are costly, difficult, or ethically sensitive.
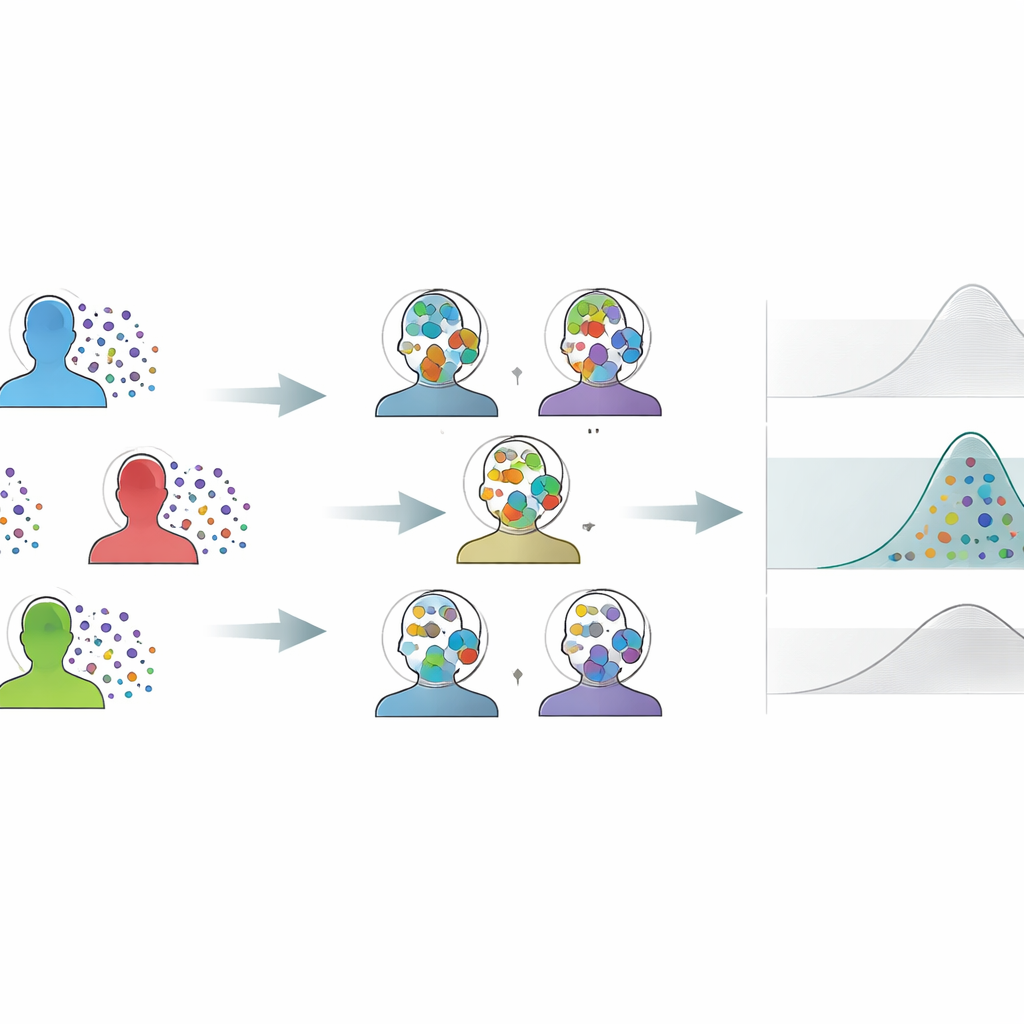
The challenge of tiny groups and noisy measurements
Neuroscience, psychology, biomechanics, and similar fields often study only a small number of participants, but record many repeated responses from each one. Traditional analyses usually squash all those repetitions into a single average per subject, leaving only a few data points to represent an entire experiment. That makes estimates unstable, increases the chance of missing real effects, and contributes to irreproducible findings. Standard resampling tricks—like repeatedly shuffling the data to gauge uncertainty—also struggle here: one popular approach tends to be too optimistic, giving confidence ranges that are too narrow, while another plays it very safe, producing ranges so wide that subtle but real effects disappear in the noise.
A new way to mix and match information
The author proposes Variance-Calibrated Cross-Individual Bootstrapping (CIB-VC) as a practical solution. Instead of resampling each subject’s trials in isolation, the method creates “synthetic individuals” by combining single trials drawn from every subject. Each synthetic individual is a blended snapshot of the whole group, which smooths out the awkward discreteness that arises when there are only a few real individuals to shuffle. However, this blending would normally shrink the apparent differences between subjects. To fix that, CIB-VC adds a calibration step that stretches the variability of these synthetic individuals to match the true variation observed between the real subjects. The final result is a set of uncertainty ranges that properly reflect how much individuals actually differ, while fully exploiting the rich trial-level data.
Putting the method to the test
To see whether CIB-VC works in practice, the study uses large-scale simulations that mimic common kinds of scientific data: bell-shaped, heavy-tailed with occasional extreme values, and strongly skewed like reaction times or firing rates. The method is also stressed with mismatches that often occur in real labs, such as slow drifts over time or subjects recorded with different noise levels. Across these scenarios, CIB-VC consistently delivers confidence ranges that include the true value about 95 percent of the time—exactly what they are designed to do. In contrast, one standard method frequently fails, especially when data are skewed and biased, producing deceptively tight ranges that almost never contain the truth. The other standard method behaves like a cautious referee, rarely wrong but often so conservative that its ranges approach the entire plausible space.
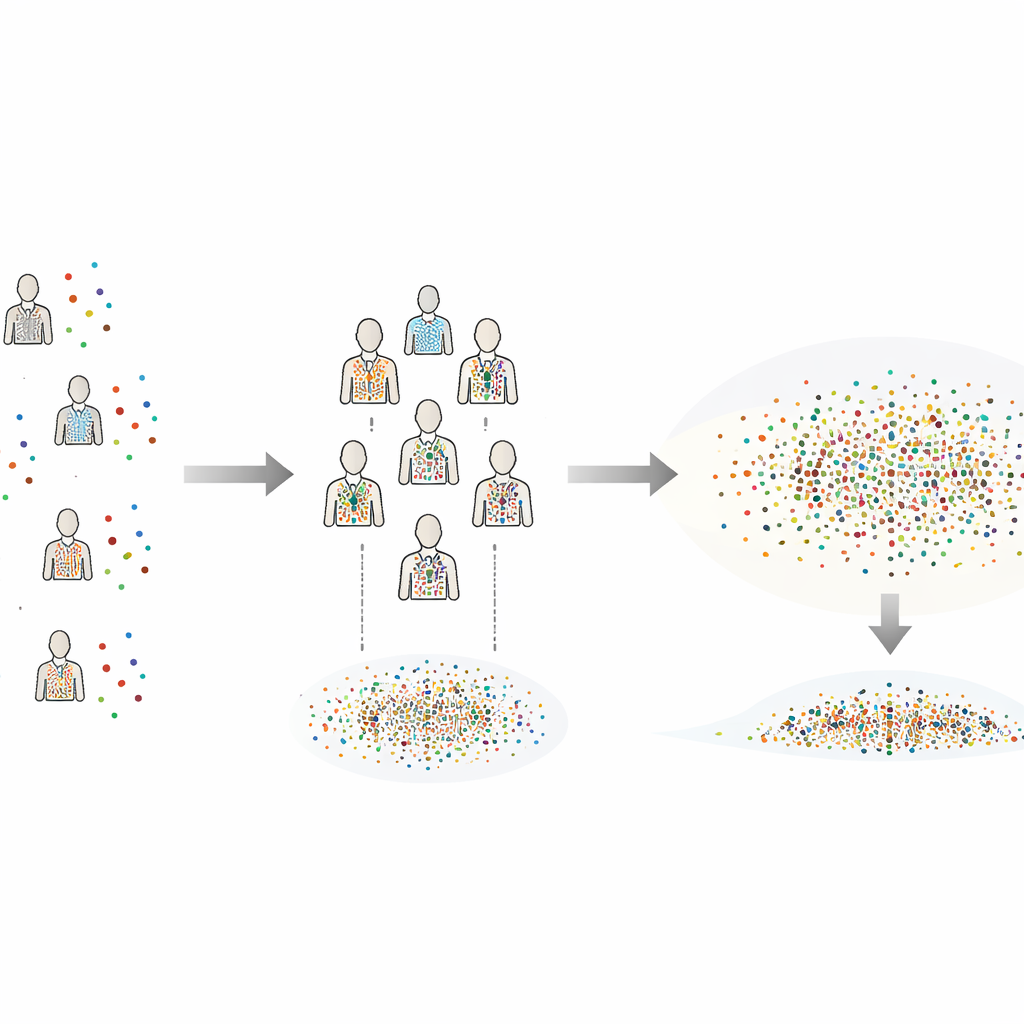
From simulations to real animals
The method is then applied to a classic small-sample neuroscience experiment: a tracking task performed by five weakly electric fish. Each fish completed multiple trials under different lighting conditions, and the question was how light level affected tracking performance. Using the same data, CIB-VC and a standard conservative method agreed on the average effect, but CIB-VC produced confidence ranges about 23 percent narrower without increasing bias or false alarms. This means researchers can pinpoint the size of the effect more precisely without testing more animals. Additional checks showed that the method’s estimates stabilize quickly as more synthetic individuals are generated, and that reasonable settings are easily handled by a desktop computer.
What this means for future studies
For readers outside statistics, the main message is that clever reuse of existing data can help balance ethics, cost, and scientific rigor. CIB-VC provides a way to turn many noisy, repeated measurements from a few individuals into reliable population-level statements while keeping false positives under control. It avoids the false sense of certainty that comes from overly narrow ranges, but also escapes the pessimism of approaches that demand much larger samples. As small and specialized studies remain the norm in many areas of brain and behavior research, tools like CIB-VC offer a practical path toward more reproducible science without always requiring more subjects.
Citation: Uyanik, I. Variance-calibrated cross-individual bootstrapping for small-sample neuroscience. Sci Rep 16, 14502 (2026). https://doi.org/10.1038/s41598-026-44126-y
Keywords: small sample neuroscience, bootstrap resampling, hierarchical data, statistical power, reproducibility