Clear Sky Science · pl
Hybrydowy framework RL–GA–LSTM–AE do planowania zadań z uwzględnieniem zużycia energii i wymogów SLA w środowiskach chmurowych
Chmury mądrzejsze dla codziennego życia cyfrowego
Za każdym razem, gdy oglądasz film na żądanie, tworzysz kopię zapasową zdjęć lub robisz zakupy online, odległe komputery w „chmurze” działają w tle. Utrzymanie tych gigantycznych centrów danych w stanie szybkiego, niezawodnego i energooszczędnego działania staje się coraz większym wyzwaniem wraz ze wzrostem naszego zapotrzebowania na usługi cyfrowe. W artykule przedstawiono nowy inteligentny system planowania, który pomaga dostawcom chmury obsługiwać miliony zadań, jednocześnie zmniejszając zużycie energii i dotrzymując obietnic dotyczących szybkości i dostępności usług.
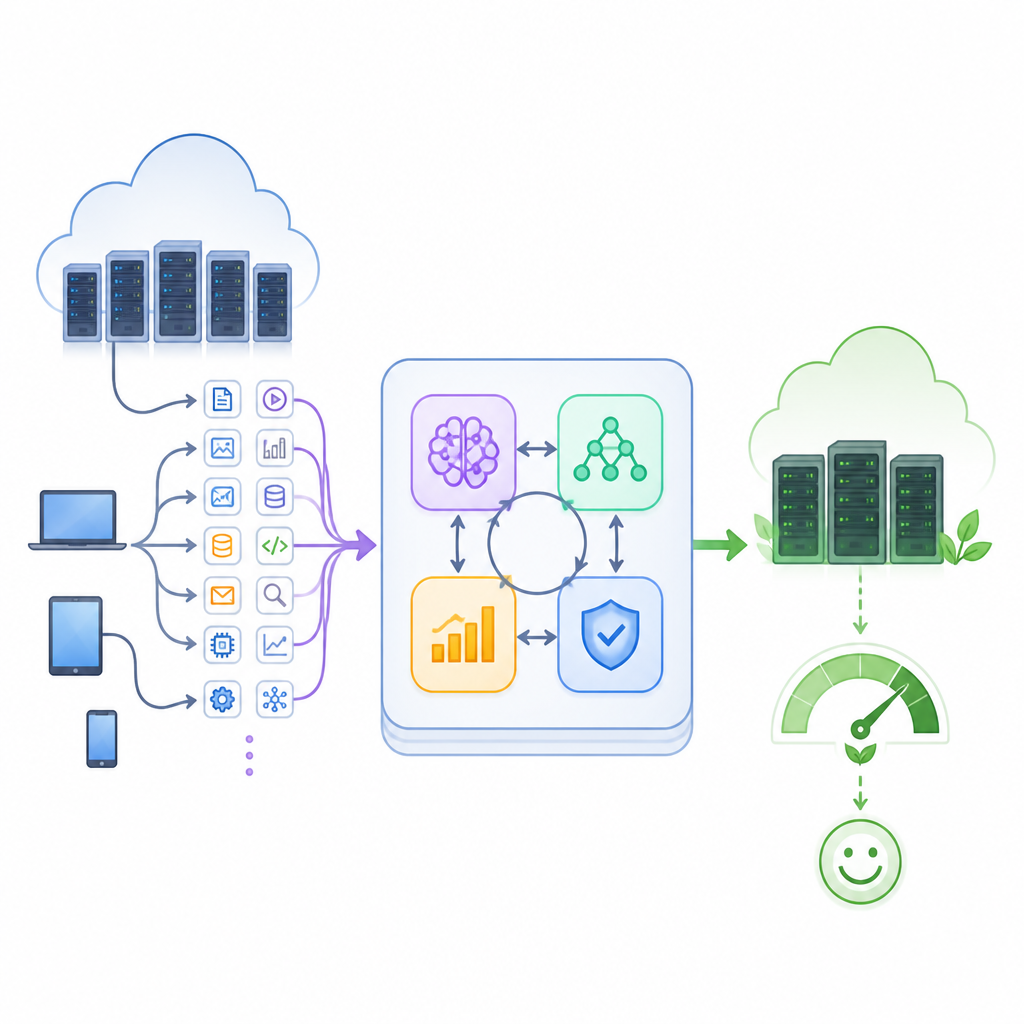
Dlaczego współczesna chmura ma problemy pod obciążeniem
Nowoczesne chmury obsługują mieszankę zadań — od krótkich kliknięć webowych po długotrwałe analizy danych — wszystkie pojawiają się w nieprzewidywalnych momentach. Tradycyjne harmonogramy stosują proste reguły, takie jak obsługa zadań w kolejności przybycia lub zawsze wybieranie najszybszego serwera. Metody te są łatwe w uruchomieniu, ale niewrażliwe na nagłe szczyty, zmiany zachowań użytkowników i różnice między maszynami. Efekt jest znany: niektóre serwery stoją bezczynnie, podczas gdy inne są przeciążone, zadania kończą się z opóźnieniem, energia jest marnowana, a umowy dotyczące czasu reakcji i dostępności są łamane.
Połączenie czterech rodzajów inteligencji
Autorzy proponują hybrydowy framework, który splata cztery narzędzia AI w jednej pętli sterowania. Moduł prognozujący oparty na odmianie sieci rekurencyjnej zwanej LSTM analizuje przeszłą aktywność, by przewidzieć obciążenie w najbliższej przyszłości. Autoenkoder obserwuje, jak dobrze potrafi odtworzyć normalne wzorce, i podnosi alarm, gdy zachowanie wydaje się nietypowe, na przykład przy nagłym wzroście ruchu lub awarii węzła. Agent uczenia ze wzmocnieniem uczy się przez próbę i błąd, które przypisania zadań do maszyn prowadzą do szybkiej i niezawodnej obsługi. Równolegle algorytm genetyczny eksploruje wiele alternatywnych harmonogramów, ewoluując lepsze rozwiązania przez pokolenia i pomagając agentowi uniknąć utknięcia w nieskutecznych strategiach.
Jak pętla utrzymuje chmurę w równowadze
Te cztery komponenty współpracują w zamkniętej pętli sprzężenia zwrotnego. Najpierw opisy przychodzących zadań i bieżące pomiary wykorzystania serwerów są oczyszczane i pakowane w skondensowany stan centrum danych. Predyktor szacuje, ile pracy nadchodzi, podczas gdy detektor anomalii sygnalizuje nietypowe obciążenie. Hybrydowy harmonogram łączy te informacje, by mapować zadania na maszyny wirtualne oraz decydować, które serwery powinny być aktywne, uśpione lub wyłączone. W miarę realizacji zadań system mierzy czasy zakończenia, przekroczone terminy, pobór mocy i niewykorzystaną pojemność. Te wyniki stają się nagrodami i karami, które dalej szkolą agenta uczącego się i przekształcają poszukiwania algorytmu genetycznego, dzięki czemu cały system stopniowo się doskonali wraz ze zmianami warunków.
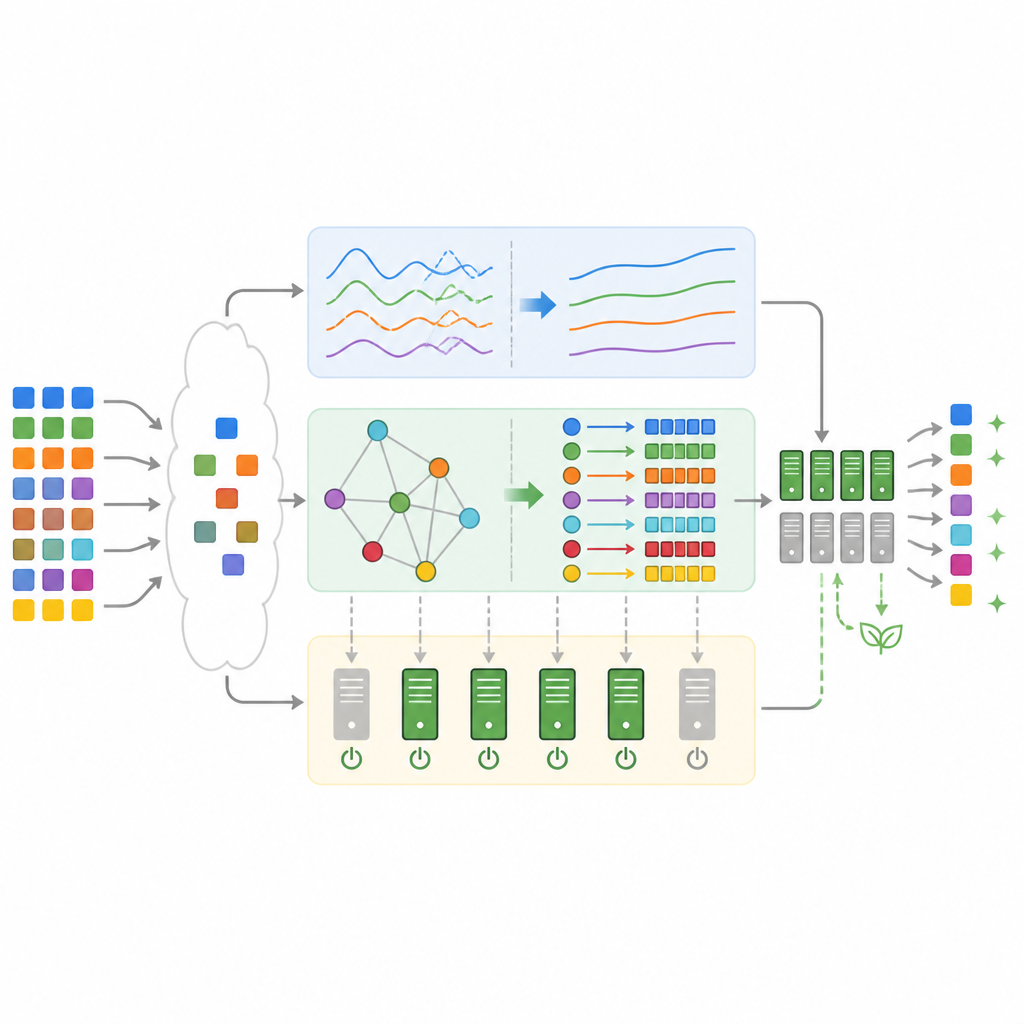
Co pokazały testy na realistycznych obciążeniach
Aby sprawdzić działanie projektu w praktyce, zespół zaimplementował go w symulacji, korzystając z rzeczywistych śladów z klastrów produkcyjnych Google i popularnego benchmarku e‑commerce. W porównaniu z klasycznymi metodami, takimi jak First‑Come‑First‑Serve, Min‑Min i samodzielne głębokie Q‑learning, hybrydowy framework wykonywał zadania szybciej, rzadziej przekraczał terminy i zużywał mniej energii. Średnio całkowity czas wykonania spadł nawet o około jedną trzecią, wykorzystanie CPU wzrosło do blisko dziewięćdziesięciu procent, a energia wymagana przy statycznym przydziale zmniejszyła się o ponad czterdzieści procent. Naruszenia poziomów usług spadły do nieco ponad czterech procent, co stanowi poprawę o około dwie trzecie w porównaniu z harmonogramem opartym wyłącznie na głębokim uczeniu ze wzmocnieniem bez dodatkowych komponentów.
Niezawodne, skalowalne i gotowe do rozwoju
Testy statystyczne i liczne powtórzenia wykazały, że te korzyści nie są przypadkowe: proces uczenia stabilizował się w ciągu kilku setek cykli treningowych, a decyzje harmonogramowe pozostawały spójne w miarę wzrostu liczby zadań od setek do tysiąca. Cały proces decyzyjny dodawał tylko ułamek sekundy opóźnienia, co jest niewielkie w porównaniu z czasem wykonywania typowych zadań chmurowych. Autorzy zauważają, że istnieją nadal ograniczenia — takie jak koszty trenowania głębokich modeli i brak formalnych gwarancji w najgorszym przypadku — ale wyniki sugerują, że ścisłe powiązanie predykcji, świadomości anomalii i adaptacyjnej optymalizacji może uczynić duże centra danych zarówno bardziej ekologicznymi, jak i bardziej niezawodnymi dla codziennych użytkowników.
Co to oznacza dla użytkowników chmury i planety
Dla laika przesłanie jest proste: inteligentniejsze oprogramowanie może pomóc chmurze robić więcej przy mniejszym nakładzie. Ucząc się, jak obciążenia przychodzą i opadają, wykrywając problemy wcześnie i ciągle dostrajając rozmieszczenie zadań, ten hybrydowy system utrzymuje responsywność usług, jednocześnie wyłączając niepotrzebne maszyny. Oznacza to mniej spowolnień przy nagłych skokach zapotrzebowania, mniej złamanych obietnic wobec klientów oraz niższe rachunki za energię i emisje dla dostawców. W miarę jak usługi cyfrowe będą się rozwijać, takie inteligentne harmonogramy mogą stać się kluczowym elementem czystszego, bardziej zrównoważonego przetwarzania danych.
Cytowanie: Narsimhulu, B., Kumar, T.S. A hybrid RL–GA–LSTM–AE framework for energy-aware and SLA-driven task scheduling in cloud computing environments. Sci Rep 16, 14961 (2026). https://doi.org/10.1038/s41598-026-43108-4
Słowa kluczowe: przetwarzanie w chmurze, planowanie zadań, efektywność energetyczna, uczenie ze wzmocnieniem, predykcja obciążenia