Clear Sky Science · fr
Un cadre hybride RL–GA–LSTM–AE pour l’ordonnancement des tâches sensible à l’énergie et piloté par les SLA dans les environnements de cloud computing
Des clouds plus intelligents pour la vie numérique quotidienne
Chaque fois que vous regardez un film en streaming, sauvegardez des photos ou faites des achats en ligne, des ordinateurs éloignés dans le « cloud » travaillent en coulisses. Maintenir ces gigantesques centres de données rapides, fiables et économes en énergie devient un défi croissant à mesure que notre appétit numérique augmente. Cet article présente un nouveau système d’ordonnancement intelligent qui aide les fournisseurs cloud à gérer des millions de tâches tout en réduisant la consommation d’énergie et en respectant les engagements de rapidité et de disponibilité pour les clients.
Pourquoi le cloud actuel peine sous la pression
Les clouds modernes hébergent un mélange de travaux, des clics web courts aux longues exécutions de calcul, tous arrivant à des moments imprévisibles. Les ordonnanceurs traditionnels suivent des règles simples comme servir les tâches dans l’ordre d’arrivée ou toujours choisir le serveur le plus rapide. Ces méthodes sont faciles à exécuter mais aveugles aux pics soudains, aux habitudes utilisateurs changeantes et aux différences entre machines. Le résultat est connu : certains serveurs restent inactifs tandis que d’autres surchauffent, les tâches prennent du retard, l’énergie est gaspillée et les accords sur les temps de réponse et la disponibilité sont rompus.
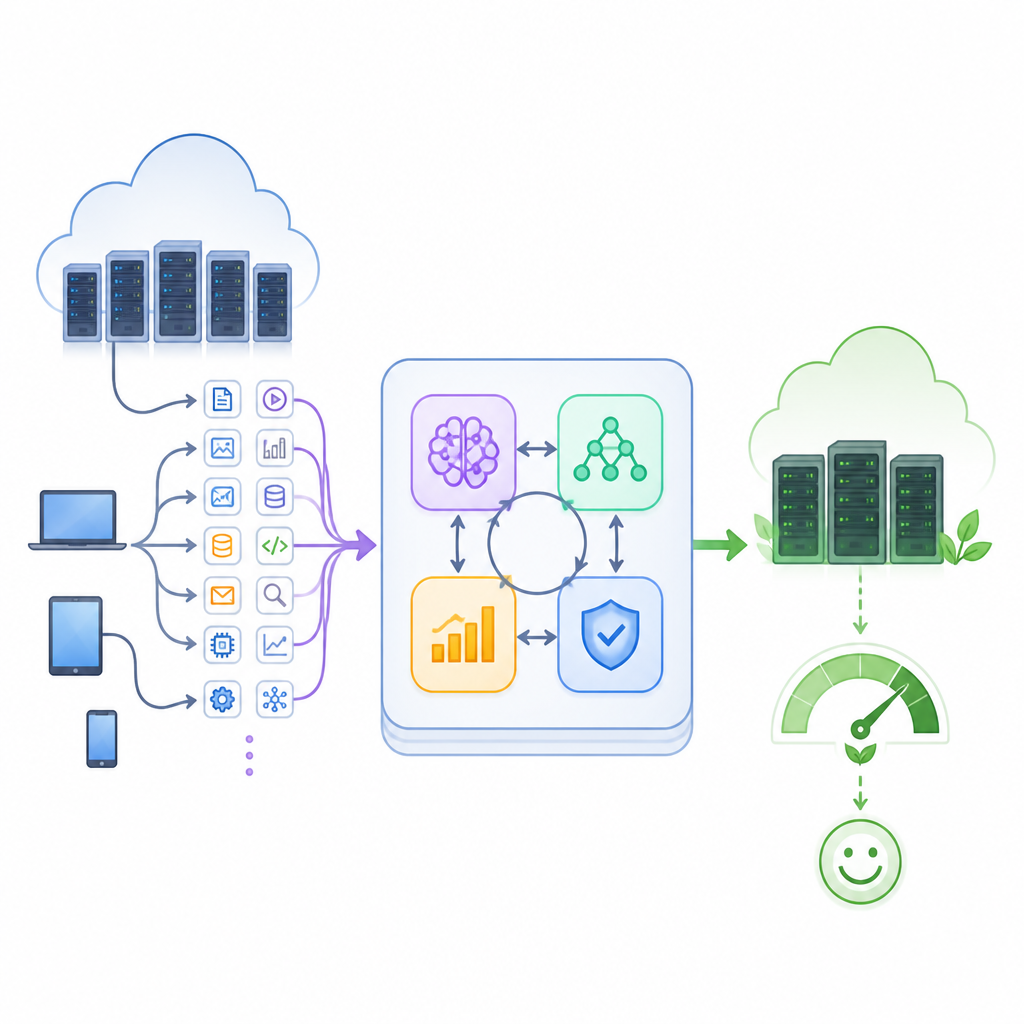
Rassembler quatre formes d’intelligence
Les auteurs proposent un cadre hybride qui tisse quatre outils d’IA en une boucle de contrôle unique. Un module de prévision basé sur un type de réseau récurrent appelé LSTM étudie l’activité passée pour prédire la charge à court terme. Un autoencodeur surveille sa capacité à reconstruire les schémas normaux et déclenche une alerte lorsque le comportement devient anormal, par exemple lors d’un pic de trafic ou d’un nœud défaillant. Un agent d’apprentissage par renforcement apprend ensuite, par essai‑erreur, quelles affectations tâche‑vers‑machine conduisent à un service rapide et fiable. En parallèle, un algorithme génétique explore de nombreuses alternatives d’ordonnancement, fait évoluer les meilleures solutions sur plusieurs générations et aide l’agent apprenant à ne pas rester coincé dans de mauvaises habitudes.
Comment la boucle maintient l’équilibre du cloud
Ces quatre composants coopèrent dans une boucle de rétroaction fermée. D’abord, les descriptions des tâches entrantes et les mesures en temps réel de l’utilisation des serveurs sont nettoyées et regroupées en un état compact du centre de données. Le prédicteur estime la charge à venir, tandis que le détecteur d’anomalies signale toute tension inhabituelle. L’ordonnanceur hybride combine ces informations pour mapper les tâches sur des machines virtuelles et décider quels serveurs doivent être actifs, en veille ou complètement éteints. Pendant l’exécution des tâches, le système mesure les temps d’achèvement, les délais manqués, la consommation électrique et la capacité oisive. Ces résultats servent de récompenses et de pénalités qui entraînent davantage l’agent apprenant et redéfinissent la recherche génétique, de sorte que le système s’améliore progressivement au fil des changements de conditions.
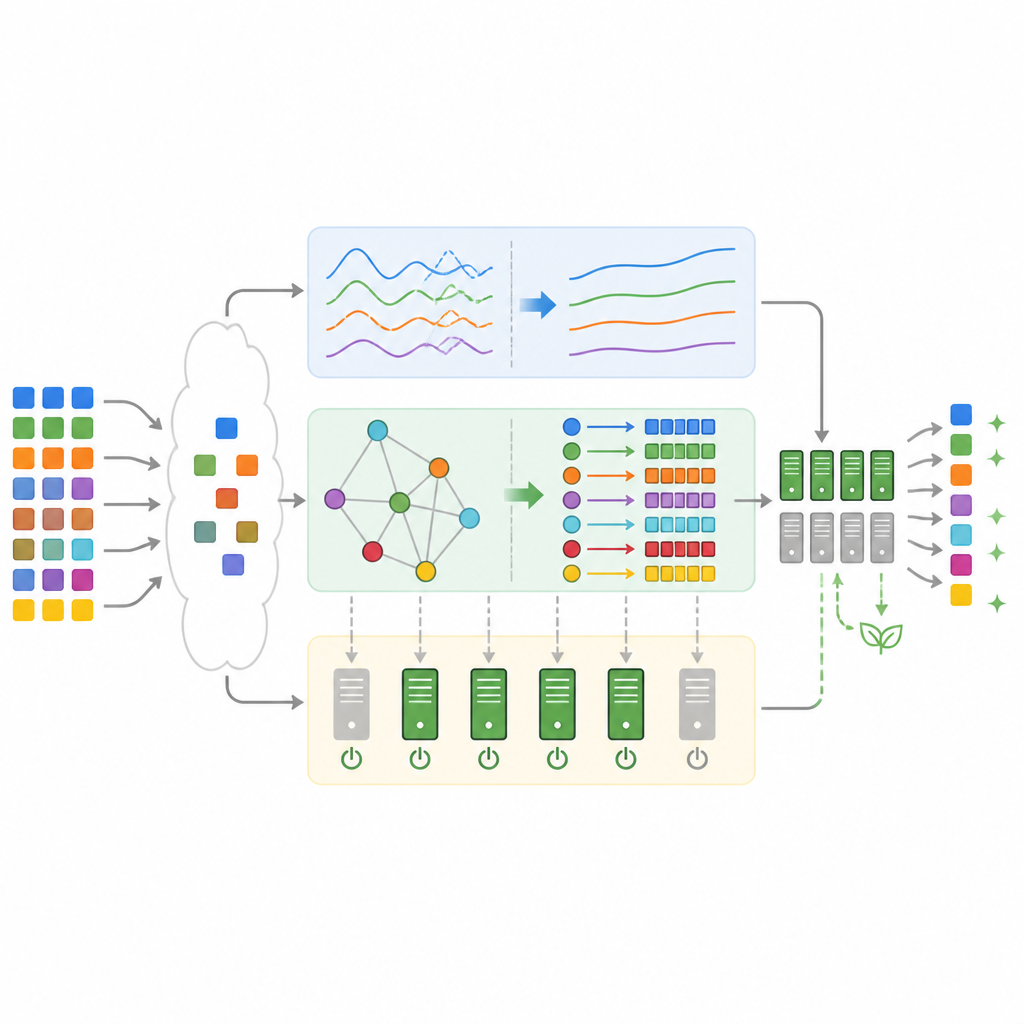
Ce que montrent les tests sur des charges réalistes
Pour vérifier si ce design fonctionne en pratique, l’équipe l’a implémenté en simulation en utilisant des traces réelles des clusters de production de Google et un benchmark d’e‑commerce populaire. Comparé aux méthodes classiques telles que First‑Come‑First‑Serve, Min‑Min et le deep Q‑learning seul, le cadre hybride a terminé les charges plus rapidement, manqué beaucoup moins de délais et consommé moins d’électricité. En moyenne, le temps total d’exécution a diminué jusqu’à environ un tiers, l’utilisation CPU est montée proche de quatre‑vingt‑dix pour cent, et l’énergie liée au provisionnement statique a chuté de plus de quarante pour cent. Les violations de SLA sont tombées à un peu plus de quatre pour cent, une amélioration d’environ deux tiers par rapport à un ordonnanceur par apprentissage profond sans les composants additionnels.
Fiable, scalable et prêt à évoluer
Des tests statistiques et de nombreuses répétitions ont montré que ces gains n’étaient pas dus au hasard : le processus d’apprentissage s’est stabilisé en quelques centaines de cycles d’entraînement, et les décisions d’ordonnancement sont restées cohérentes lorsque le nombre de tâches est passé de quelques centaines à mille. L’ensemble du processus de décision n’a ajouté qu’une fraction de seconde de latence, faible par rapport au temps d’exécution des tâches cloud typiques. Les auteurs notent qu’il subsiste des limites — comme le coût d’entraînement des modèles profonds et l’absence de garanties formelles en pire cas — mais les résultats suggèrent qu’un couplage étroit de la prédiction, de la détection d’anomalies et de l’optimisation adaptative peut rendre les grands centres de données à la fois plus verts et plus fiables pour les utilisateurs quotidiens.
Ce que cela signifie pour les utilisateurs du cloud et la planète
Pour un non‑spécialiste, le message est simple : des logiciels plus intelligents peuvent aider le cloud à faire plus avec moins. En apprenant comment les charges fluctuent, en repérant les problèmes tôt et en ajustant continuellement la répartition des tâches, ce système hybride maintient des services réactifs tout en éteignant les machines non nécessaires. Cela se traduit par moins de ralentissements lors des pics de demande, moins de promesses rompues envers les clients, et des factures d’énergie et des émissions réduites pour les fournisseurs. À mesure que les services numériques se développent, de tels ordonnanceurs intelligents pourraient devenir un pilier d’un informatique plus propre et plus durable.
Citation: Narsimhulu, B., Kumar, T.S. A hybrid RL–GA–LSTM–AE framework for energy-aware and SLA-driven task scheduling in cloud computing environments. Sci Rep 16, 14961 (2026). https://doi.org/10.1038/s41598-026-43108-4
Mots-clés: cloud computing, ordonnancement des tâches, efficacité énergétique, apprentissage par renforcement, prévision de la charge