Clear Sky Science · en
A hybrid RL–GA–LSTM–AE framework for energy-aware and SLA-driven task scheduling in cloud computing environments
Smarter clouds for everyday digital life
Every time you stream a movie, back up photos, or shop online, distant computers in the “cloud” work behind the scenes. Keeping those giant data centres fast, reliable, and energy‑efficient is a growing challenge as our digital appetite soars. This paper introduces a new smart scheduling system that helps cloud providers juggle millions of tasks while cutting power use and keeping customer promises about speed and availability.
Why today’s cloud struggles under pressure
Modern clouds host a mix of jobs, from short web clicks to long data crunching runs, all arriving at unpredictable times. Traditional schedulers follow simple rules such as serving tasks in arrival order or always choosing the quickest server. These methods are easy to run but blind to sudden surges, changing user habits, and differences between machines. The result is familiar: some servers sit idle while others overheat, jobs finish late, energy is wasted, and agreements on response time and uptime are broken.
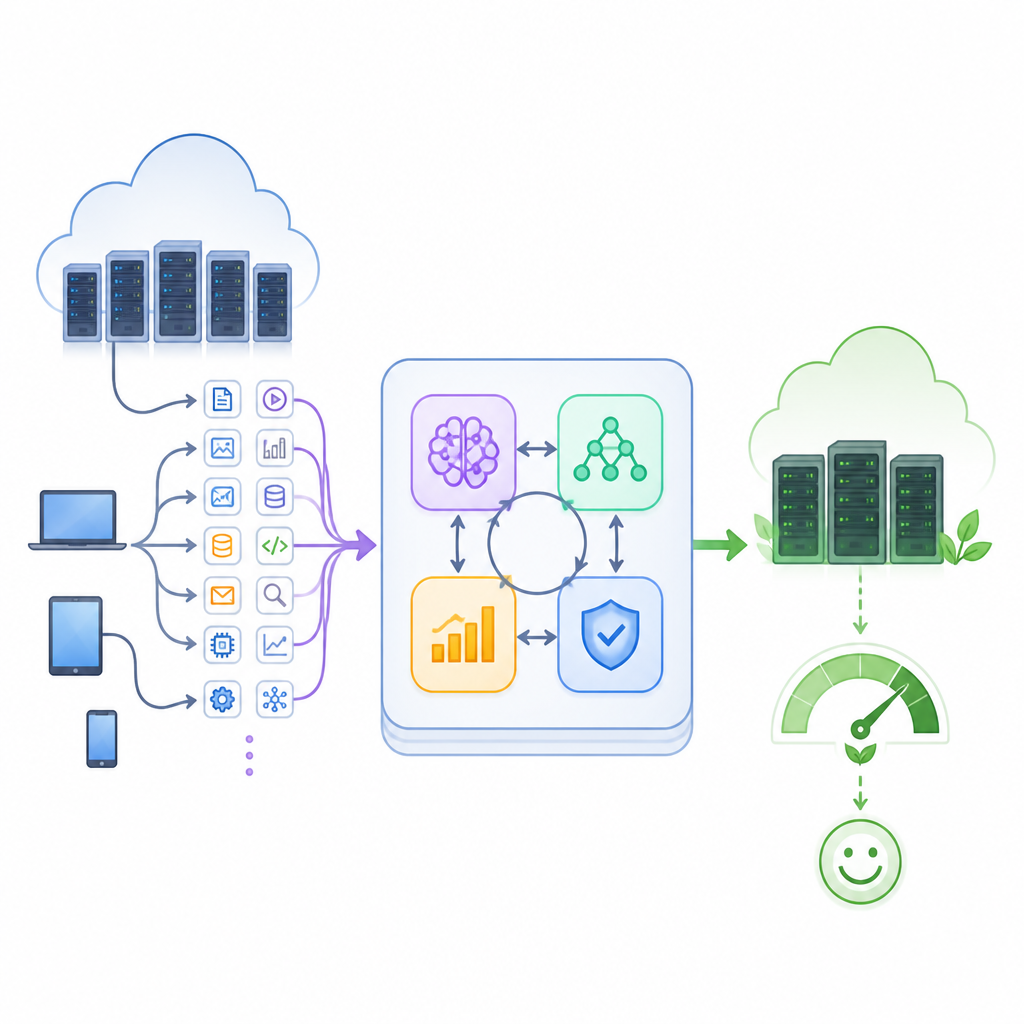
Bringing four kinds of intelligence together
The authors propose a hybrid framework that weaves four AI tools into a single control loop. A forecasting module based on a type of recurrent neural network called LSTM studies past activity to predict near‑future load. An autoencoder watches how well it can reconstruct normal patterns and raises a flag when behaviour looks abnormal, such as a traffic spike or a failing node. A reinforcement learning agent then learns, through trial and error, which task‑to‑machine choices lead to quick, reliable service. Alongside it, a genetic algorithm explores many alternative schedules, evolving better ones over generations and helping the learner avoid getting stuck in poor habits.
How the loop keeps the cloud in balance
These four components cooperate in a closed feedback loop. First, incoming task descriptions and live measurements of server usage are cleaned and packed into a compact state of the data centre. The predictor estimates how much work is coming, while the anomaly detector signals any unusual strain. The hybrid scheduler combines this insight to map tasks onto virtual machines and to decide which servers should be active, sleeping, or powered off. As jobs run, the system measures completion times, missed deadlines, power draw, and idle capacity. Those outcomes become rewards and penalties that further train the learning agent and reshape the genetic search, so the whole system steadily improves as conditions change.
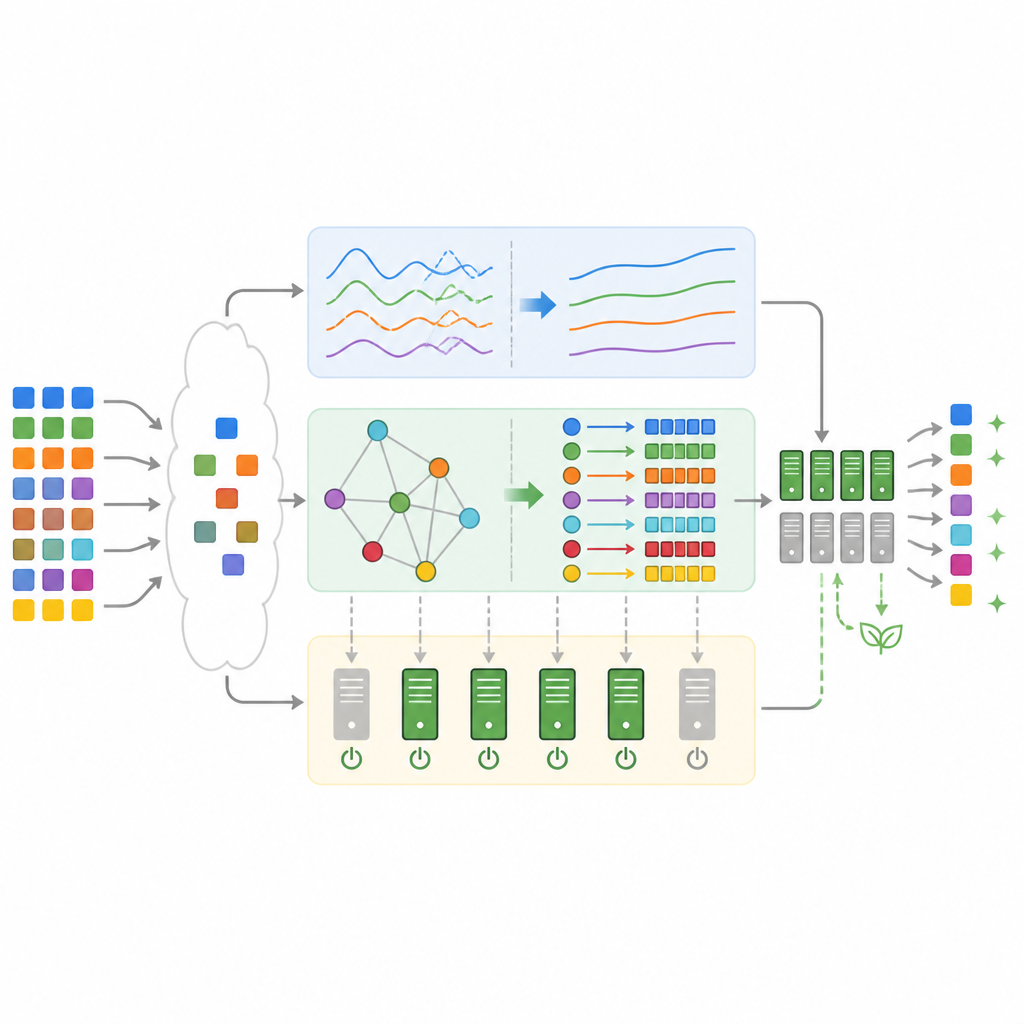
What the tests show in realistic workloads
To check whether this design works in practice, the team implemented it in simulation using real traces from Google’s production clusters and a popular e‑commerce benchmark. Compared with standard methods such as First‑Come‑First‑Serve, Min‑Min, and deep Q‑learning alone, the hybrid framework finished workloads faster, missed far fewer deadlines, and used less electricity. On average, total completion time dropped by up to about a third, CPU use rose close to ninety percent, and energy for static provisioning fell by more than forty percent. Service‑level violations fell to just over four percent, an improvement of roughly two‑thirds over a deep reinforcement learning scheduler without the extra components.
Reliable, scalable, and ready to grow
Statistical tests and many repeated runs showed that these gains were not flukes: the learning process stabilised within a few hundred training cycles, and scheduling decisions remained consistent as the number of tasks grew from hundreds to a thousand. The entire decision process added only a fraction of a second of delay, small compared with the time it takes to run typical cloud jobs. The authors note that there are still limits—such as the cost of training the deep models and the lack of formal worst‑case guarantees—but the results suggest that tightly coupling prediction, anomaly awareness, and adaptive optimisation can make large data centres both greener and more dependable for everyday users.
What this means for cloud users and the planet
For a layperson, the message is simple: smarter software can help the cloud do more with less. By learning how workloads ebb and flow, spotting trouble early, and continually tuning how tasks are placed, this hybrid system keeps services responsive while switching off unneeded machines. That means fewer slowdowns when demand spikes, fewer broken promises to customers, and lower power bills and emissions for providers. As digital services keep expanding, such intelligent schedulers could become a key building block of cleaner, more sustainable computing.
Citation: Narsimhulu, B., Kumar, T.S. A hybrid RL–GA–LSTM–AE framework for energy-aware and SLA-driven task scheduling in cloud computing environments. Sci Rep 16, 14961 (2026). https://doi.org/10.1038/s41598-026-43108-4
Keywords: cloud computing, task scheduling, energy efficiency, reinforcement learning, workload prediction