Clear Sky Science · es
Un marco híbrido RL–GA–LSTM–AE para la planificación de tareas consciente de la energía y orientada por SLA en entornos de computación en la nube
Nubes más inteligentes para la vida digital diaria
Cada vez que ves una película en streaming, haces una copia de seguridad de fotos o compras en línea, ordenadores remotos en la “nube” trabajan entre bastidores. Mantener esos gigantescos centros de datos rápidos, fiables y energéticamente eficientes es un desafío creciente a medida que nuestra apetencia digital se dispara. Este artículo presenta un nuevo sistema de planificación inteligente que ayuda a los proveedores de la nube a gestionar millones de tareas mientras reduce el consumo energético y mantiene las promesas de velocidad y disponibilidad a los clientes.
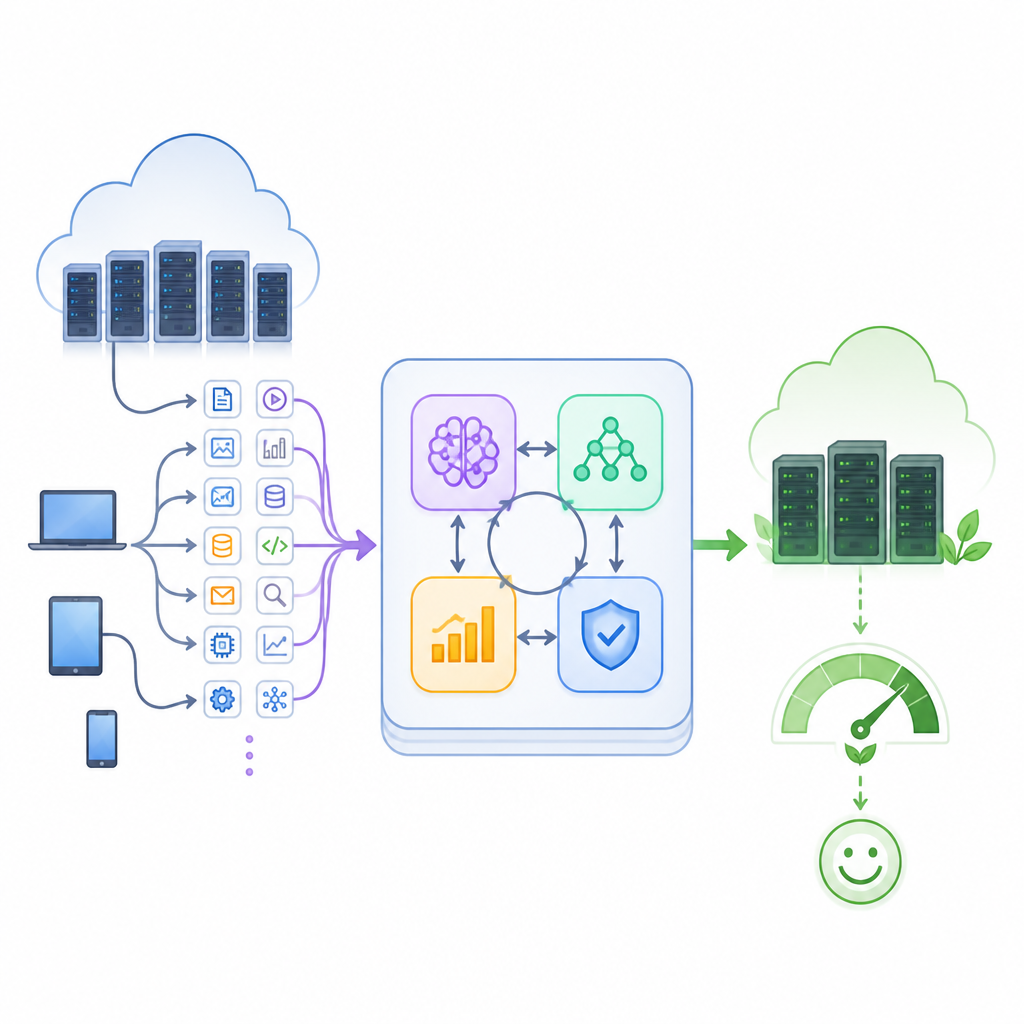
Por qué las nubes actuales sufren bajo presión
Las nubes modernas alojan una mezcla de trabajos, desde clics web cortos hasta largas ejecuciones de procesamiento de datos, todos llegando en momentos impredecibles. Los planificadores tradicionales siguen reglas sencillas como atender las tareas por orden de llegada o elegir siempre el servidor más rápido. Estos métodos son fáciles de ejecutar pero son ciegos a picos repentinos, cambios en los hábitos de los usuarios y diferencias entre máquinas. El resultado es familiar: algunos servidores permanecen inactivos mientras otros se sobrecargan, los trabajos terminan tarde, se desperdicia energía y se incumplen los acuerdos sobre tiempo de respuesta y disponibilidad.
Reunir cuatro tipos de inteligencia
Los autores proponen un marco híbrido que entrelaza cuatro herramientas de IA en un único bucle de control. Un módulo de pronóstico, basado en un tipo de red neuronal recurrente llamada LSTM, estudia la actividad pasada para predecir la carga a corto plazo. Un autoencoder vigila cuánto puede reconstruir los patrones normales y lanza una señal cuando el comportamiento parece anómalo, como un pico de tráfico o un nodo que falla. Un agente de aprendizaje por refuerzo aprende entonces, por ensayo y error, qué asignaciones tarea‑a‑máquina conducen a un servicio rápido y fiable. Junto a él, un algoritmo genético explora muchas alternativas de planificación, evolucionando mejores soluciones a lo largo de generaciones y ayudando al aprendiz a evitar quedarse atascado en malas decisiones.
Cómo el bucle mantiene el equilibrio en la nube
Estos cuatro componentes cooperan en un bucle de retroalimentación cerrado. Primero, las descripciones de las tareas entrantes y las mediciones en vivo del uso de los servidores se depuran y se empaquetan en un estado compacto del centro de datos. El predictor estima cuánto trabajo está por llegar, mientras que el detector de anomalías señala cualquier tensión inusual. El planificador híbrido combina esta información para asignar tareas a máquinas virtuales y decidir qué servidores deben estar activos, en reposo o apagados. A medida que los trabajos se ejecutan, el sistema mide tiempos de finalización, plazos incumplidos, consumo energético y capacidad ociosa. Esos resultados se convierten en recompensas y penalizaciones que entrenan al agente de aprendizaje y reconfiguran la búsqueda genética, de modo que todo el sistema mejora de forma continua conforme cambian las condiciones.
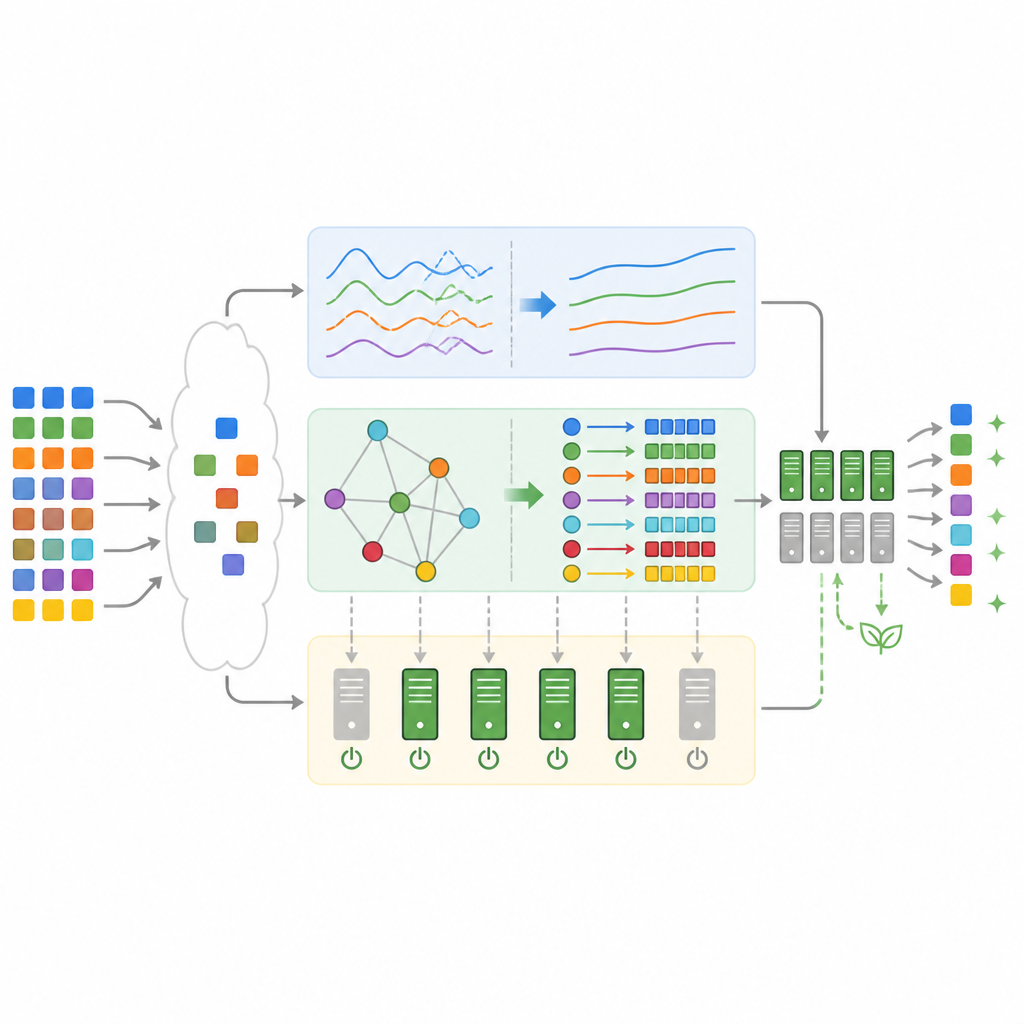
Qué muestran las pruebas con cargas de trabajo realistas
Para comprobar si este diseño funciona en la práctica, el equipo lo implementó en simulación usando trazas reales de los clusters de producción de Google y un popular benchmark de comercio electrónico. En comparación con métodos estándar como First‑Come‑First‑Serve, Min‑Min y aprendizaje profundo Q‑learning por sí solo, el marco híbrido completó las cargas de trabajo más rápidamente, incumplió muchas menos fechas límite y consumió menos electricidad. En promedio, el tiempo total de finalización se redujo hasta en aproximadamente un tercio, el uso de CPU aumentó hasta cerca del noventa por ciento y la energía para aprovisionamiento estático cayó más del cuarenta por ciento. Las violaciones de nivel de servicio se redujeron a poco más del cuatro por ciento, una mejora de aproximadamente dos tercios respecto a un planificador de aprendizaje profundo por refuerzo sin los componentes adicionales.
Fiable, escalable y listo para crecer
Pruebas estadísticas y numerosas ejecuciones repetidas mostraron que estas ganancias no fueron casuales: el proceso de aprendizaje se estabilizó en unos pocos cientos de ciclos de entrenamiento y las decisiones de planificación se mantuvieron consistentes al aumentar el número de tareas de cientos a mil. Todo el proceso de toma de decisiones añadía solo una fracción de segundo de demora, pequeña en comparación con el tiempo que tardan en ejecutarse los trabajos típicos en la nube. Los autores señalan que aún existen límites —como el coste de entrenar los modelos profundos y la falta de garantías formales de peor caso—, pero los resultados sugieren que acoplar estrechamente predicción, conciencia de anomalías y optimización adaptativa puede hacer que los grandes centros de datos sean tanto más verdes como más fiables para los usuarios cotidianos.
Qué significa esto para los usuarios de la nube y el planeta
Para el público general, el mensaje es simple: un software más inteligente puede ayudar a la nube a hacer más con menos. Al aprender cómo fluyen las cargas de trabajo, detectar problemas pronto y afinar continuamente cómo se colocan las tareas, este sistema híbrido mantiene los servicios receptivos mientras apaga las máquinas innecesarias. Esto se traduce en menos ralentizaciones cuando la demanda se dispara, menos promesas incumplidas a los clientes y facturas y emisiones más bajas para los proveedores. A medida que los servicios digitales siguen expandiéndose, tales planificadores inteligentes podrían convertirse en un componente clave de una computación más limpia y sostenible.
Cita: Narsimhulu, B., Kumar, T.S. A hybrid RL–GA–LSTM–AE framework for energy-aware and SLA-driven task scheduling in cloud computing environments. Sci Rep 16, 14961 (2026). https://doi.org/10.1038/s41598-026-43108-4
Palabras clave: computación en la nube, planificación de tareas, eficiencia energética, aprendizaje por refuerzo, predicción de cargas