Clear Sky Science · it
Un framework ibrido RL–GA–LSTM–AE per la schedulazione dei task sensibile all’energia e guidata dagli SLA negli ambienti di cloud computing
Cloud più intelligenti per la vita digitale di tutti i giorni
Ogni volta che guardi un film in streaming, fai il backup delle foto o acquisti online, computer remoti nel “cloud” lavorano dietro le quinte. Mantenere quei giganteschi data center veloci, affidabili ed efficienti dal punto di vista energetico è una sfida crescente man mano che il nostro appetito digitale aumenta. Questo articolo presenta un nuovo sistema di schedulazione intelligente che aiuta i fornitori cloud a gestire milioni di task riducendo il consumo di energia e rispettando le promesse ai clienti su velocità e disponibilità.
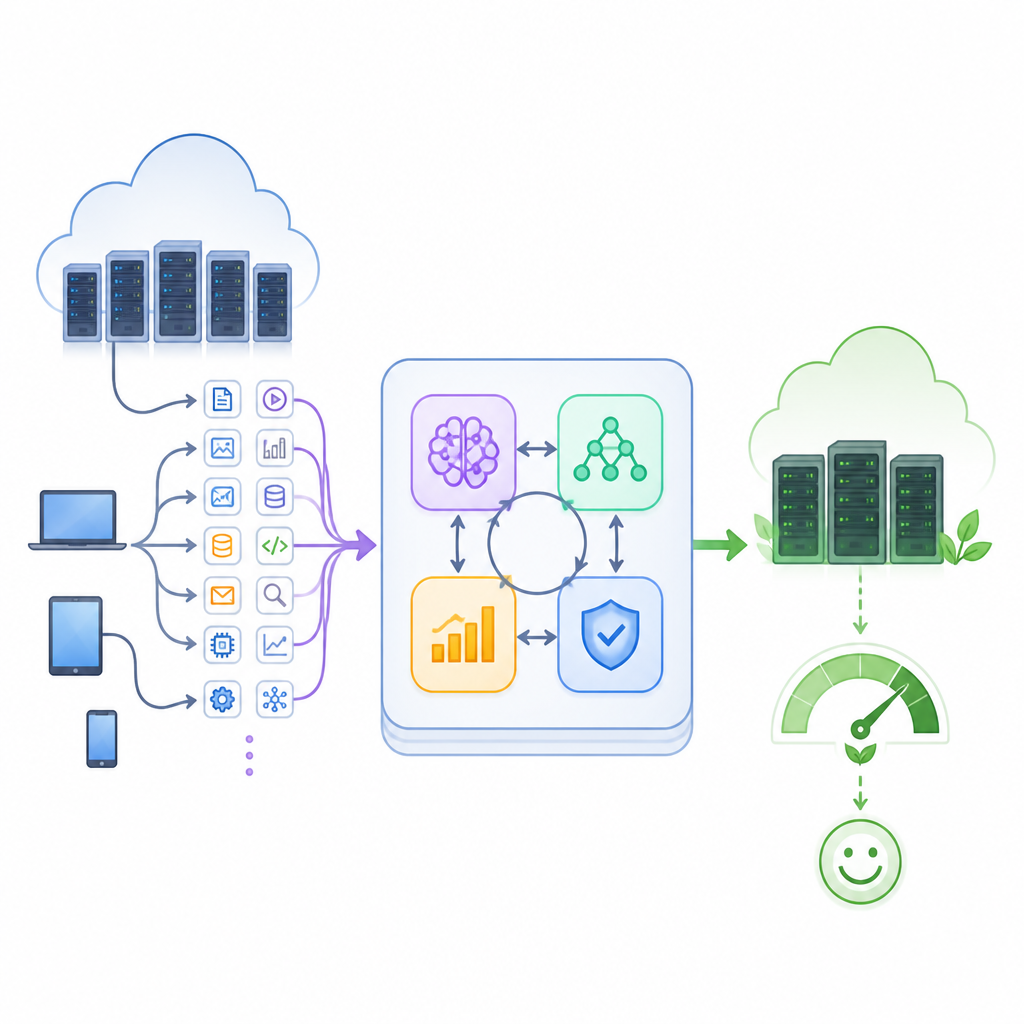
Perché il cloud odierno fatica sotto pressione
I cloud moderni ospitano una mescolanza di lavori, da brevi clic web a lunghe esecuzioni di analisi dati, tutti in arrivo in orari imprevedibili. I scheduler tradizionali seguono regole semplici come servire i task nell’ordine di arrivo o scegliere sempre il server più veloce. Questi metodi sono semplici da eseguire ma ciechi davanti a improvvisi picchi, a cambiamenti nelle abitudini degli utenti e alle differenze tra le macchine. Il risultato è familiare: alcuni server restano inattivi mentre altri si sovraccaricano, i lavori finiscono in ritardo, l’energia viene sprecata e gli accordi su tempi di risposta e disponibilità vengono violati.
Unire quattro tipi di intelligenza
Gli autori propongono un framework ibrido che intreccia quattro strumenti di AI in un unico ciclo di controllo. Un modulo di previsione basato su un tipo di rete ricorrente chiamata LSTM studia l’attività passata per prevedere il carico a breve termine. Un autoencoder monitora quanto bene riesce a ricostruire i pattern normali e lancia un avviso quando il comportamento appare anomalo, ad esempio per un picco di traffico o un nodo guasto. Un agente di apprendimento per rinforzo impara, tramite tentativi ed errori, quali scelte task‑macchina portano a un servizio rapido e affidabile. Parallelamente, un algoritmo genetico esplora molteplici schedule alternative, facendo evolvere soluzioni migliori nel corso delle generazioni e aiutando l’agente a evitare di restare bloccato in abitudini subottimali.
Come il ciclo mantiene l’equilibrio nel cloud
Questi quattro componenti cooperano in un anello di feedback chiuso. Innanzitutto, le descrizioni dei task in arrivo e le misure in tempo reale dell’utilizzo dei server vengono pulite e compresse in uno stato compatto del data center. Il predittore stima quanto lavoro arriverà, mentre il rilevatore di anomalie segnala eventuali tensioni insolite. Lo scheduler ibrido combina queste informazioni per mappare i task sulle macchine virtuali e decidere quali server debbano essere attivi, in standby o spenti. Durante l’esecuzione dei lavori, il sistema misura i tempi di completamento, le scadenze mancate, il consumo energetico e la capacità inattiva. Questi risultati diventano ricompense e penalità che addestrano ulteriormente l’agente di apprendimento e rimodellano la ricerca genetica, così l’intero sistema migliora costantemente al variare delle condizioni.
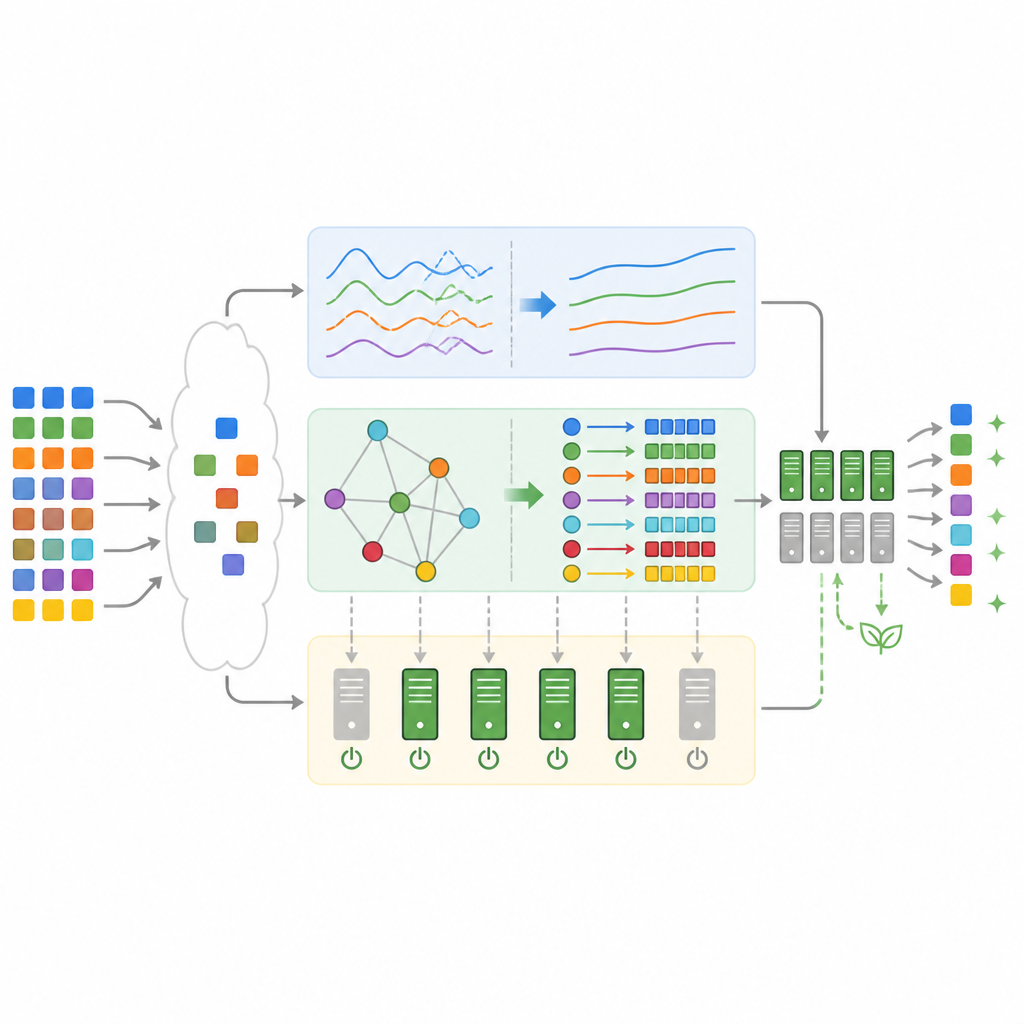
Cosa mostrano i test su carichi realistici
Per verificare se questo progetto funziona in pratica, il team lo ha implementato in simulazione usando tracce reali dai cluster di produzione di Google e un popolare benchmark per e‑commerce. Rispetto a metodi standard come First‑Come‑First‑Serve, Min‑Min e al solo deep Q‑learning, il framework ibrido ha completato i carichi di lavoro più rapidamente, ha mancato molte meno scadenze e ha usato meno elettricità. In media, il tempo totale di completamento è diminuito fino a circa un terzo, l’utilizzo della CPU è salito vicino al novanta percento e l’energia per il provisioning statico è scesa di oltre il quaranta percento. Le violazioni del livello di servizio sono scese a poco più del quattro percento, un miglioramento di circa due terzi rispetto a uno scheduler di deep reinforcement learning privo dei componenti aggiuntivi.
Affidabile, scalabile e pronto a crescere
Test statistici e molte esecuzioni ripetute hanno mostrato che questi guadagni non erano casuali: il processo di apprendimento si è stabilizzato in poche centinaia di cicli di addestramento e le decisioni di schedulazione sono rimaste coerenti all’aumentare dei task da alcune centinaia fino a mille. L’intero processo decisionale ha aggiunto solo una frazione di secondo di ritardo, poca cosa rispetto al tempo necessario per eseguire tipici lavori cloud. Gli autori notano che permangono limiti—come il costo dell’addestramento dei modelli profondi e la mancanza di garanzie formali sul caso peggiore—ma i risultati suggeriscono che accoppiare strettamente previsione, rilevamento delle anomalie e ottimizzazione adattativa può rendere i grandi data center sia più ecologici sia più affidabili per gli utenti quotidiani.
Cosa significa per gli utenti cloud e per il pianeta
Per il pubblico generale, il messaggio è semplice: software più intelligente può aiutare il cloud a fare di più con meno. Imparando come i carichi di lavoro fluttuano, individuando i problemi precocemente e adattando continuamente il posizionamento dei task, questo sistema ibrido mantiene i servizi reattivi mentre spegne le macchine non necessarie. Ciò significa meno rallentamenti durante i picchi di domanda, meno promesse mancate ai clienti e bollette energetiche ed emissioni inferiori per i fornitori. Con l’espansione continua dei servizi digitali, scheduler intelligenti di questo tipo potrebbero diventare un elemento chiave per un computing più pulito e sostenibile.
Citazione: Narsimhulu, B., Kumar, T.S. A hybrid RL–GA–LSTM–AE framework for energy-aware and SLA-driven task scheduling in cloud computing environments. Sci Rep 16, 14961 (2026). https://doi.org/10.1038/s41598-026-43108-4
Parole chiave: cloud computing, schedulazione dei task, efficienza energetica, apprendimento per rinforzo, predizione del carico di lavoro