Clear Sky Science · de
Ein hybrides RL–GA–LSTM–AE‑Framework für energie‑bewusstes und SLA‑getriebenes Task‑Scheduling in Cloud‑Computing‑Umgebungen
Intelligentere Clouds für den digitalen Alltag
Jedes Mal, wenn Sie einen Film streamen, Fotos sichern oder online einkaufen, arbeiten entfernte Computer in der „Cloud“ im Hintergrund. Diese riesigen Rechenzentren schnell, verlässlich und energieeffizient zu halten, wird angesichts unseres wachsenden digitalen Bedarfs zunehmend anspruchsvoller. Dieses Paper stellt ein neues intelligentes Planungsystem vor, das Cloud‑Anbietern hilft, Millionen von Aufgaben zu koordinieren, dabei den Stromverbrauch zu senken und die zugesagten Leistungs‑ und Verfügbarkeitsanforderungen einzuhalten.
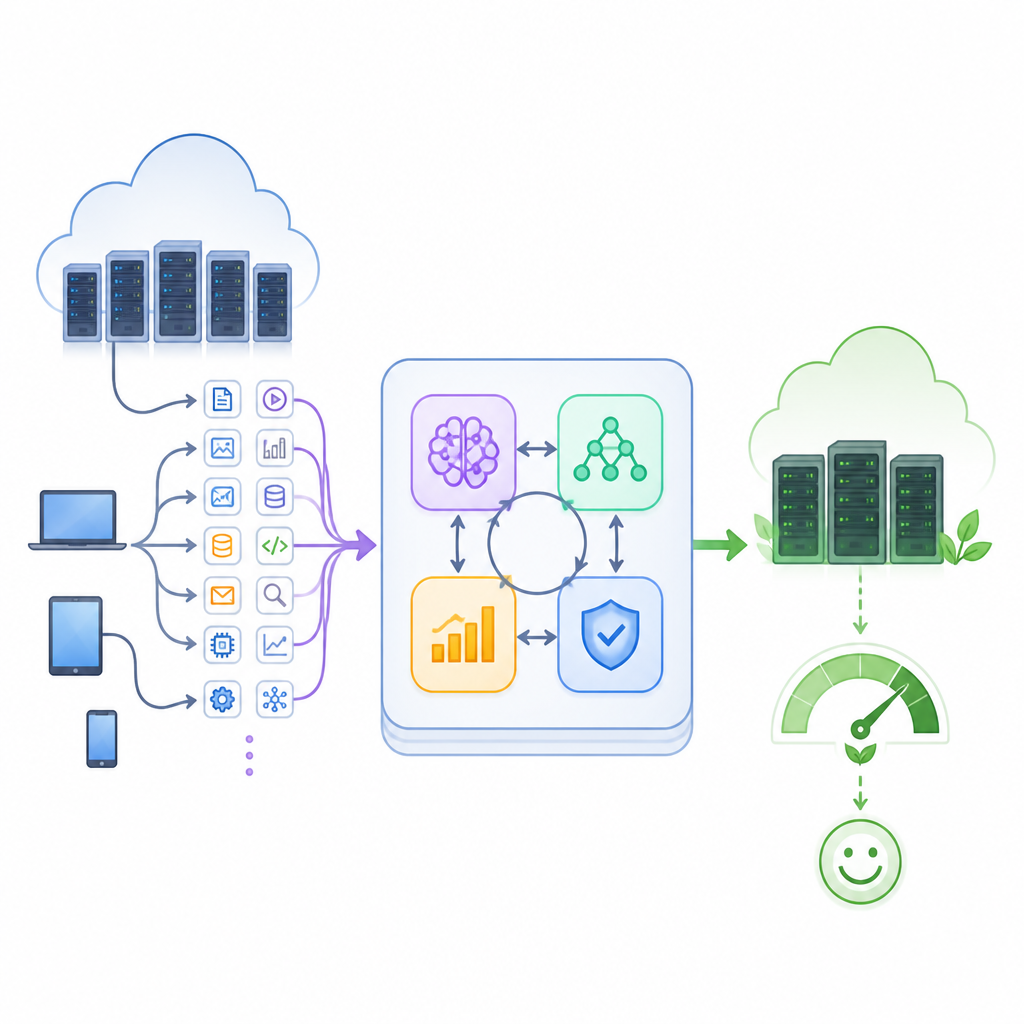
Warum heutige Clouds bei Lastspitzen Probleme bekommen
Moderne Clouds betreiben eine Mischung aus Jobs, von kurzen Web‑Anfragen bis zu langen Datenverarbeitungsaufgaben, die zu unvorhersehbaren Zeiten eintreffen. Traditionelle Scheduler folgen einfachen Regeln, etwa Aufgaben nach Ankunftsreihenfolge zu bearbeiten oder stets den schnellsten Server zu wählen. Diese Methoden sind leicht zu betreiben, aber blind gegenüber plötzlichen Spitzen, veränderten Nutzergewohnheiten und Unterschieden zwischen Maschinen. Das Ergebnis ist bekannt: Einige Server bleiben untätig, während andere überlastet sind, Jobs werden verspätet beendet, Energie wird verschwendet und Vereinbarungen über Antwortzeiten und Verfügbarkeit werden verletzt.
Vier Arten von Intelligenz vereinen
Die Autoren schlagen ein hybrides Framework vor, das vier KI‑Werkzeuge in einer Steuerungsschleife verwebt. Ein Prognosemodul auf Basis eines rekurrenten neuronalen Netzes vom Typ LSTM analysiert vergangene Aktivität, um die nahe Zukunft vorherzusagen. Ein Autoencoder überwacht, wie gut er normale Muster rekonstruieren kann, und schlägt Alarm, wenn das Verhalten ungewöhnlich aussieht, etwa bei einem Verkehrssprung oder einem ausfallenden Knoten. Ein Agent für verstärkendes Lernen lernt durch Versuch und Irrtum, welche Zuordnungen von Aufgaben zu Maschinen zu schneller und zuverlässiger Bedienung führen. Parallel dazu erkundet ein genetischer Algorithmus viele alternative Zeitpläne, entwickelt über Generationen bessere Lösungen und hilft dem Lernenden, nicht in schlechte Gewohnheiten zu verfallen.
Wie die Schleife die Cloud im Gleichgewicht hält
Diese vier Komponenten arbeiten in einer geschlossenen Rückkopplungsschleife zusammen. Zunächst werden eintreffende Aufgabenbeschreibungen und Live‑Messdaten zur Serverauslastung bereinigt und zu einem kompakten Zustand des Rechenzentrums verdichtet. Der Prädiktor schätzt, wie viel Arbeit kommt, während der Anomalie‑Detektor auf ungewöhnliche Belastungen hinweist. Der hybride Scheduler kombiniert diese Erkenntnisse, um Aufgaben auf virtuelle Maschinen zuzuordnen und zu entscheiden, welche Server aktiv, im Ruhezustand oder abgeschaltet sein sollten. Während Jobs laufen, misst das System Abschlusszeiten, verpasste Deadlines, Leistungsaufnahme und Leerlaufkapazität. Diese Ergebnisse werden zu Belohnungen und Strafen, die den Lernagenten weitertrainieren und die genetische Suche beeinflussen, sodass sich das gesamte System stetig verbessert, während sich die Bedingungen ändern.
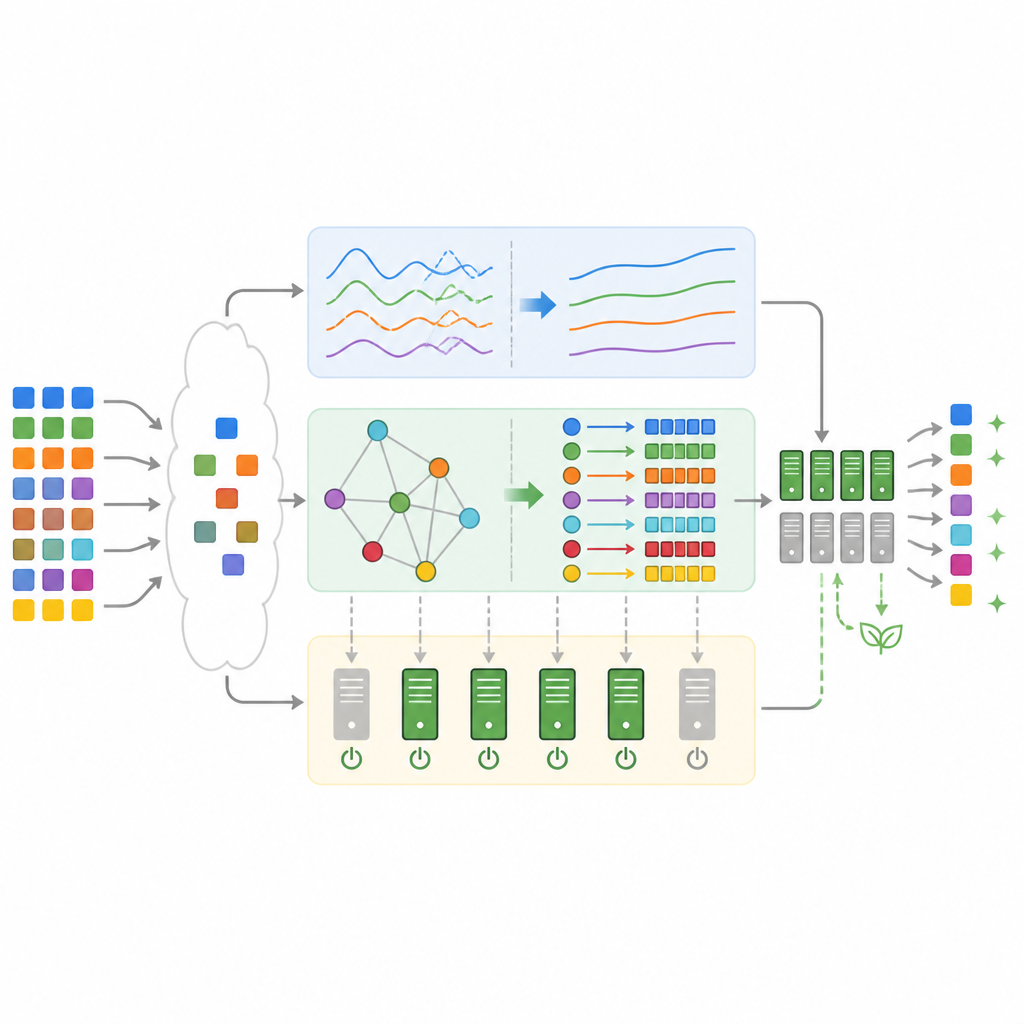
Was die Tests unter realistischen Workloads zeigen
Um zu prüfen, ob dieses Design in der Praxis funktioniert, implementierte das Team es in einer Simulation mit echten Traces aus Googles Produktionsclustern und einem verbreiteten E‑Commerce‑Benchmark. Im Vergleich zu Standardmethoden wie First‑Come‑First‑Serve, Min‑Min und reinem Deep Q‑Learning absolvierte das hybride Framework Workloads schneller, verfehlte deutlich weniger Deadlines und verbrauchte weniger Strom. Im Mittel sank die Gesamtabschlusszeit um bis zu etwa ein Drittel, die CPU‑Auslastung stieg auf nahe neunzig Prozent und die Energie für statische Vorhaltung fiel um mehr als vierzig Prozent. Service‑Level‑Verstöße gingen auf etwas über vier Prozent zurück, eine Verbesserung um rund zwei Drittel gegenüber einem Deep‑Reinforcement‑Learning‑Scheduler ohne die zusätzlichen Komponenten.
Zuverlässig, skalierbar und bereit zu wachsen
Statistische Tests und viele Wiederholungen zeigten, dass diese Gewinne keine Zufälle waren: Der Lernprozess stabilisierte sich innerhalb weniger hundert Trainingszyklen, und die Planungsentscheidungen blieben konsistent, als die Zahl der Aufgaben von wenigen Hundert auf tausend wuchs. Der gesamte Entscheidungsprozess fügte nur einen Bruchteil einer Sekunde Verzögerung hinzu, was im Vergleich zur Laufzeit typischer Cloud‑Jobs unbedeutend ist. Die Autoren weisen darauf hin, dass es weiterhin Grenzen gibt – etwa die Kosten für das Training der tiefen Modelle und das Fehlen formaler Worst‑Case‑Garantie – doch die Ergebnisse deuten darauf hin, dass eine enge Verzahnung von Vorhersage, Anomalieerkennung und adaptiver Optimierung große Rechenzentren sowohl grüner als auch verlässlicher für Alltagsnutzer machen kann.
Was das für Cloud‑Nutzer und den Planeten bedeutet
Für Laien ist die Botschaft einfach: Intelligente Software kann der Cloud helfen, mehr mit weniger zu leisten. Indem sie lernt, wie Workloads fluktuieren, Probleme frühzeitig erkennt und kontinuierlich die Platzierung von Aufgaben anpasst, hält dieses hybride System Dienste reaktionsschnell und schaltet nicht benötigte Maschinen aus. Das bedeutet weniger Ausfälle bei Lastspitzen, weniger gebrochene Zusagen an Kunden und niedrigere Stromrechnungen sowie Emissionen für Anbieter. Mit der fortschreitenden Ausweitung digitaler Dienste könnten solche intelligenten Scheduler zu einem wichtigen Baustein saubererer, nachhaltigerer IT‑Infrastruktur werden.
Zitation: Narsimhulu, B., Kumar, T.S. A hybrid RL–GA–LSTM–AE framework for energy-aware and SLA-driven task scheduling in cloud computing environments. Sci Rep 16, 14961 (2026). https://doi.org/10.1038/s41598-026-43108-4
Schlüsselwörter: Cloud‑Computing, Aufgabenplanung, Energieeffizienz, Verstärkendes Lernen, Workload‑Vorhersage