Clear Sky Science · nl
Stabiliteit en robuustheid van minimaal interpreteerbare meerderheidsstemmings-ensembles
Waarom kleine stemmodellen belangrijk zijn
Als computers helpen beslissen wie een lening krijgt, welke medische test uitgevoerd moet worden of hoe fraude gescreend wordt, willen mensen de redenen achter elke beslissing begrijpen. Een populaire aanpak is het gebruik van zeer kleine modellen bestaande uit eenvoudige ja/nee-regels die over het antwoord stemmen. Deze modellen zijn gemakkelijk te lezen, maar de studie achter dit artikel stelt een diepere vraag: als we vasthouden aan de kleinst mogelijke regelsset, krijgen we dan verklaringen die kwetsbaar zijn en te snel veranderen wanneer de gegevens licht worden verstoord?
Eenvoudige regel-stemmers in klare taal
Het artikel onderzoekt kleine op regels gebaseerde systemen die meerderheidsstemmings-ensembles worden genoemd. Elke regel kijkt naar één ja/nee-kenmerk, bijvoorbeeld of een waarde boven een drempel ligt, en brengt een stem uit voor een van twee uitkomsten. De uiteindelijke beslissing komt voort uit de meerderheid van deze stemmen. De auteurs richten zich op modellen die minimaal zijn, wat betekent dat ze het minste aantal regels gebruiken dat nodig is om de trainingsdata te verklaren. Zulke modellen zijn zeer aantrekkelijk voor uitlegbaarheid, omdat een mens in principe alle regels kan lezen en kan begrijpen hoe beslissingen worden genomen.
Verschillende kleinste antwoorden
In de praktijk laten gegevens echter vaak meer dan één kleinste model toe. Het team toont aan dat er veel verschillende minimale regelssets kunnen bestaan die allemaal even goed bij dezelfde data passen, een situatie die soms het Rashomon-effect wordt genoemd. Om dit te bestuderen stellen ze drie metingen voor. Ten eerste telt het multipliciteitstarief hoe vaak er meer dan één minimaal model voor een dataset bestaat. Ten tweede controleert bootstrap-stabiliteit hoe gelijk de geselecteerde minimale modellen zijn wanneer de data licht wordt herbemonsterd. Ten derde test feature-flip-robuustheid hoe goed een gekozen model standhoudt wanneer individuele invoerbits willekeurig worden omgedraaid, wat ruis of verschoven data nabootst. 
Wat zorgvuldige experimenten onthullen
Met gecontroleerde synthetische datasets planten de auteurs een bekend stemmodel en proberen vervolgens minimale modellen te reconstrueren uit kleine steekproeven. Ze vinden dat de nauwkeurigheid op schone testdata hoog kan zijn, zelfs wanneer de stabiliteit slecht is. Bij zeer weinig trainingsvoorbeelden verschijnen veel verschillende minimale modellen, en overlappen de regelssets die uit de ene herbemonstering gekozen worden met die uit de volgende slechts beperkt. Naarmate het aantal voorbeelden toeneemt, nemen deze instabiliteiten af: de multipliciteit daalt, de bootstrap-stabiliteit stijgt en de robuustheid tegen feature-flips verbetert. Bij matige steekproefgroottes komt het teruggevonden minimale model bijna overeen met het geplante model, en het verzamelen van nog meer data levert slechts kleine verbeteringen op.
Reële datasets en praktische keuzes
De studie onderzoekt vervolgens klassieke machine-learning-datasets uit domeinen zoals kankerdiagnostiek en bankbiljetauthenticatie. Omdat perfecte pasvorm met zeer kleine regelssets niet altijd mogelijk is, versoepelen de auteurs het doel door minstens een gekozen trainingsnauwkeurigheid te behalen en vervolgens naar de kleinste modellen te zoeken die aan die eis voldoen. Ze vinden dat sommige datasets zeer stabiele minimale ensembles ondersteunen, terwijl andere duidelijke instabiliteit en gevoeligheid voor ruis vertonen. Het aanscherpen van de vereiste nauwkeurigheid maakt modellen minder stabiel en soms onmogelijk te vinden. Om dit aan te pakken testen de auteurs selectieregels die nog steeds kleine modellen bevoordelen maar, onder alle minimale modellen, die kiezen die het vaakst in bootstrap-hermonsteringen voorkomen of die het meest robuust zijn tegen feature-flips. Deze strategieën ruilen iets van ruwe nauwkeurigheid in voor meer reproduceerbare en betrouwbare verklaringen. 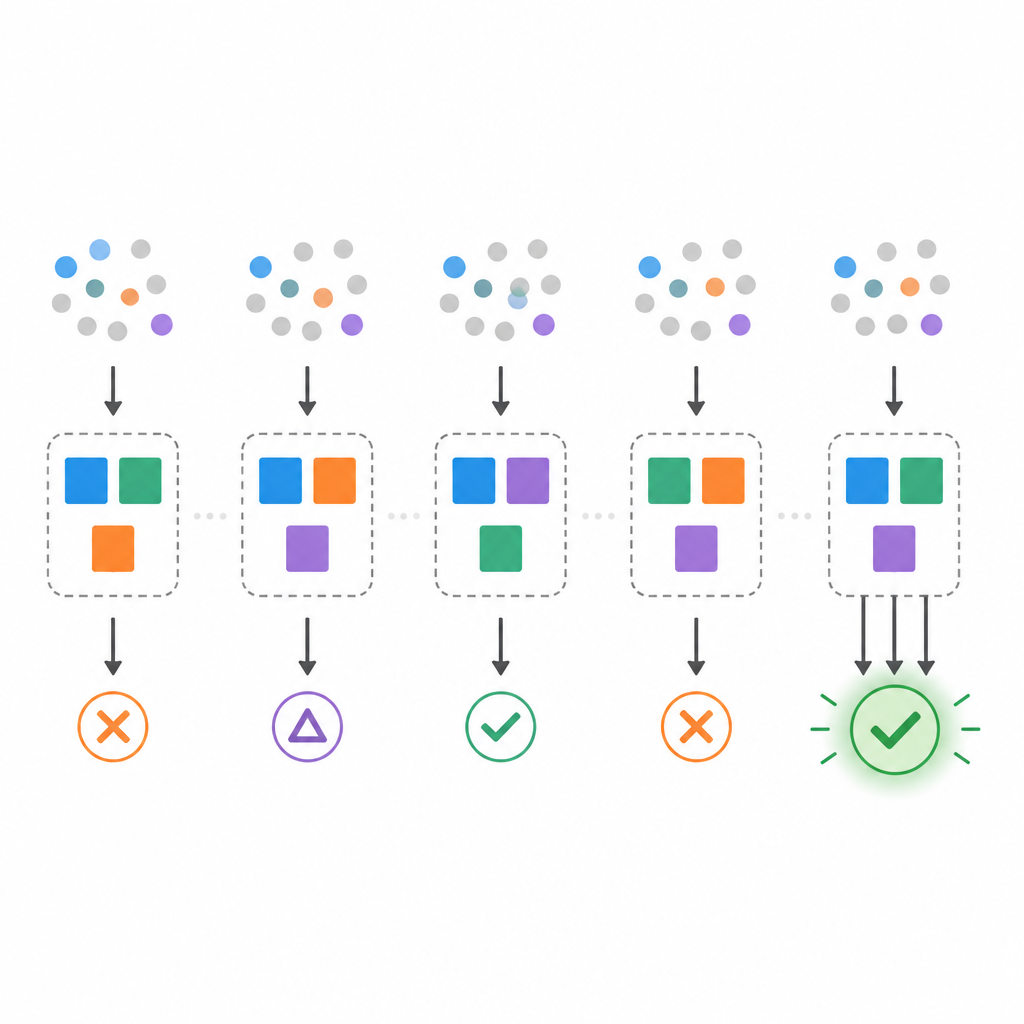
Waarom dit ertoe doet bij beslissingen met hoge inzet
Voor mensen die op transparante modellen vertrouwen in gevoelige domeinen is de kernboodschap dat "kleinste" niet altijd hetzelfde is als "veiligste." Twee even kleine regelssets kunnen verschillende verklaringen geven voor waarom een beslissing is genomen en kunnen anders reageren op kleine veranderingen in de invoer. De auteurs tonen aan dat het praktisch is om te meten hoe stabiel en robuust zulke modellen zijn en dat het rapporteren van deze maten naast modelgrootte gebruikers kan waarschuwen wanneer verklaringen broos zijn. Kortom: bij het bouwen van eenvoudige stemmodellen voor beslissingen met hoge inzet moet men eerst streven naar compactheid en vervolgens bewust de versies bevoordelen die consistent gedrag vertonen over herbemonsterde of licht verstoorde data.
Bronvermelding: Li, Q., Huang, Z. & Pan, M. Stability and robustness of minimal majority vote interpretable ensembles. Sci Rep 16, 14877 (2026). https://doi.org/10.1038/s41598-026-45289-4
Trefwoorden: interpreteerbare modellen, meerderheidsstem, modelstabiliteit, robuustheid, Rashomon-effect