Clear Sky Science · es
Estabilidad y robustez de ensamblajes interpretables mínimos de voto mayoritario
Por qué importan los modelos de votación pequeños
Cuando los ordenadores ayudan a decidir quién obtiene un préstamo, qué prueba médica realizar o cómo detectar fraudes, la gente quiere entender las razones detrás de cada decisión. Una idea popular es usar modelos muy pequeños formados por reglas simples de sí o no que votan por la respuesta. Estos modelos son fáciles de leer, pero el estudio detrás de este artículo plantea una pregunta más profunda: si insistimos en el conjunto de reglas más pequeño posible, ¿terminamos con explicaciones frágiles que cambian demasiado ante pequeñas alteraciones de los datos?
Votantes simples de reglas en lenguaje claro
El artículo examina sistemas diminutos basados en reglas conocidos como ensamblajes de voto mayoritario. Cada regla observa una característica binaria, por ejemplo si un valor supera un umbral, y emite un voto por uno de dos resultados. La decisión final se toma por mayoría de votos. Los autores se centran en modelos que son mínimos, es decir, que usan el menor número de reglas necesario para ajustar los datos de entrenamiento. Tales modelos son muy atractivos para la explicabilidad, porque un humano puede, en principio, leer todas las reglas y entender cómo se toman las decisiones.
Muchas respuestas mínimas diferentes
Sin embargo, los datos reales con frecuencia permiten más de un modelo mínimo. El equipo demuestra que puede haber muchos conjuntos mínimos de reglas diferentes que encajan perfectamente los mismos datos, una situación a veces llamada efecto Rashomon. Para estudiarlo, proponen tres medidas. Primero, la tasa de multiplicidad cuenta con qué frecuencia existe más de un modelo mínimo para un conjunto de datos. Segundo, la estabilidad por bootstrap verifica cuánto se parecen los modelos mínimos seleccionados cuando los datos se re-muestrean ligeramente. Tercero, la robustez frente a cambios de características evalúa qué tan bien se mantiene un modelo elegido cuando bits de entrada individuales se invierten aleatoriamente, imitando datos ruidosos o con desplazamiento. 
Lo que revelan experimentos cuidadosos
Usando conjuntos de datos sintéticos controlados, los autores plantan un modelo de votación conocido y luego intentan recuperar modelos mínimos a partir de pequeñas muestras. Encuentran que la precisión en datos de prueba limpios puede ser alta incluso cuando la estabilidad es pobre. Con muy pocos ejemplos de entrenamiento, aparecen muchos modelos mínimos diferentes, y los conjuntos de reglas elegidos de un re-muestreo a otro se solapan solo modestamente. A medida que aumenta el número de muestras, estas inestabilidades disminuyen: la multiplicidad cae, la estabilidad por bootstrap sube y la robustez frente a cambios de características mejora. En tamaños de muestra moderados, el modelo mínimo recuperado se aproxima mucho al modelo plantado, y recoger aún más datos aporta solo ganancias pequeñas.
Datos reales y decisiones prácticas
El estudio pasa luego a conjuntos de datos clásicos de aprendizaje automático de ámbitos como el diagnóstico del cáncer y la autenticación de billetes. Debido a que el ajuste perfecto con conjuntos de reglas diminutos no siempre es posible, los autores relajan el objetivo para alcanzar al menos una precisión de entrenamiento elegida y luego buscan los modelos más pequeños que cumplan ese umbral. Encuentran que algunos conjuntos de datos admiten ensamblajes mínimos altamente estables, mientras que otros muestran inestabilidad clara y sensibilidad al ruido. Endurecer la precisión requerida hace que los modelos sean menos estables y, en ocasiones, imposibles de encontrar. Para abordar esto, los autores prueban reglas de selección que siguen favoreciendo modelos pequeños pero que, entre todos los mínimos, eligen aquellos que aparecen con mayor frecuencia en re-muestreos bootstrap o que son más robustos a cambios de características. Estas estrategias sacrifican ligeramente la precisión cruda a cambio de explicaciones más reproducibles y fiables. 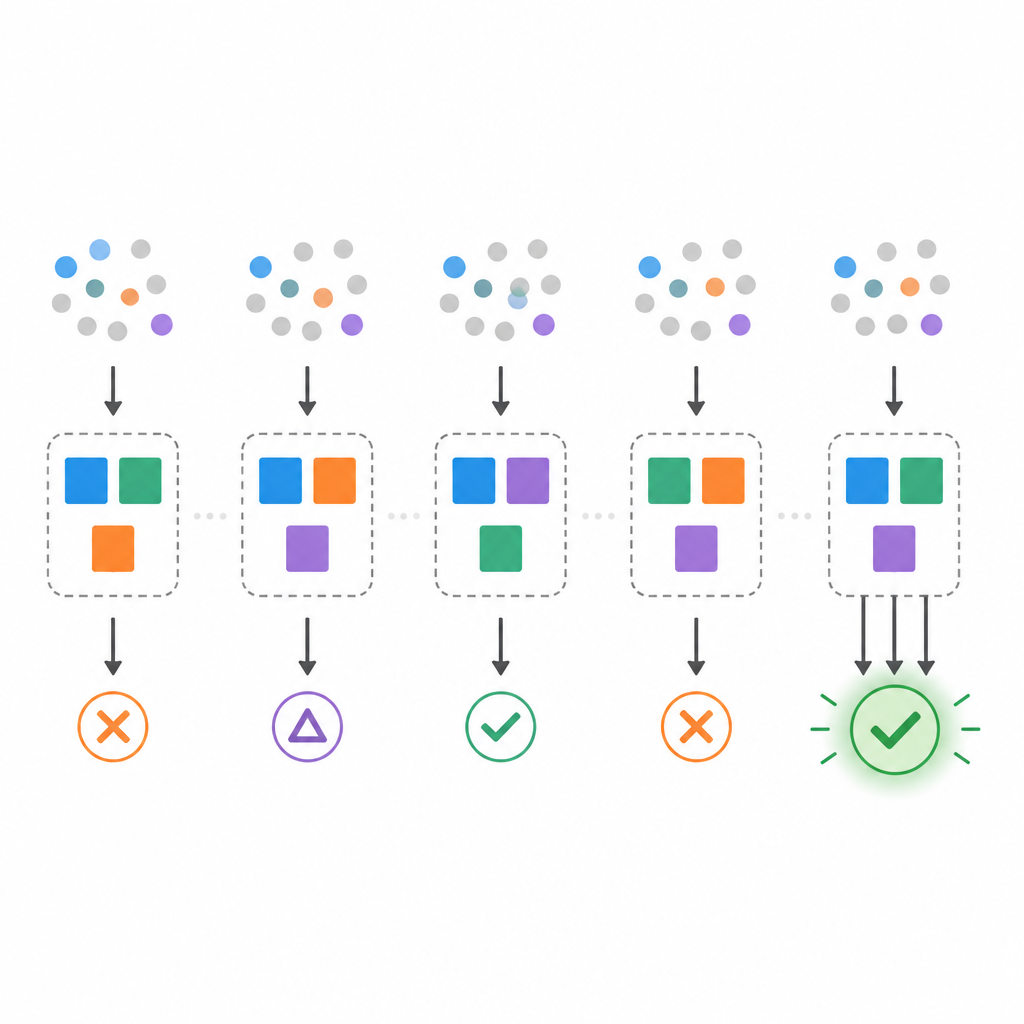
Por qué esto importa en decisiones de alto riesgo
Para quienes dependen de modelos transparentes en dominios sensibles, el mensaje central es que «el más pequeño» no siempre significa «el más seguro». Dos conjuntos de reglas igualmente diminutos pueden contar historias diferentes sobre por qué se tomó una decisión y pueden reaccionar de modo distinto ante pequeños cambios en las entradas. Los autores muestran que es práctico medir cuán estables y robustos son tales modelos y que informar estas medidas junto al tamaño del modelo puede advertir a los usuarios cuando las explicaciones son frágiles. En resumen, al construir modelos de votación simples para decisiones de alto riesgo, primero se debe apuntar a la compacidad, pero luego favorecer deliberadamente las versiones que se comporten de forma consistente ante re-muestreos o ligeras perturbaciones de los datos.
Cita: Li, Q., Huang, Z. & Pan, M. Stability and robustness of minimal majority vote interpretable ensembles. Sci Rep 16, 14877 (2026). https://doi.org/10.1038/s41598-026-45289-4
Palabras clave: modelos interpretables, voto mayoritario, estabilidad del modelo, robustez, efecto Rashomon