Clear Sky Science · en
Stability and robustness of minimal majority vote interpretable ensembles
Why small voting models matter
When computers help decide who gets a loan, which medical test to run, or how to screen for fraud, people want to understand the reasons behind each decision. One popular idea is to use very small models made of simple yes or no rules that vote on the answer. These models are easy to read, but the study behind this article asks a deeper question: if we insist on the smallest possible rule set, do we end up with explanations that are fragile and change too easily when the data is disturbed?
Simple rule voters in plain language
The paper examines tiny rule-based systems known as majority-vote ensembles. Each rule looks at one yes or no feature, such as whether a value is above a threshold, and casts a vote for one of two outcomes. The final decision comes from the majority of these votes. The authors focus on models that are minimal, meaning they use the fewest rules needed to fit the training data. Such models are highly attractive for explainability, because a human can, in principle, read all the rules and understand how decisions are made.
Many different smallest answers
However, real data often allows more than one smallest model. The team shows that there can be many different minimal rule sets that all fit the same data perfectly, a situation sometimes called a Rashomon effect. To study this, they propose three measurements. First, the multiplicity rate counts how often there is more than one minimal model for a dataset. Second, bootstrap stability checks how similar the selected minimal models are when the data is slightly resampled. Third, feature-flip robustness tests how well a chosen model holds up when individual input bits are randomly flipped, mimicking noisy or shifted data. 
What careful experiments reveal
Using controlled synthetic datasets, the authors plant a known voting model and then try to recover minimal models from small samples. They find that accuracy on clean test data can be high even when stability is poor. With very few training examples, many different minimal models appear, and the rule sets chosen from one resample to the next overlap only modestly. As the number of samples grows, these instabilities shrink: multiplicity falls, bootstrap stability rises, and robustness to feature flips improves. At moderate sample sizes, the recovered minimal model nearly matches the planted one, and collecting even more data yields only small gains.
Real datasets and practical choices
The study then turns to classic machine-learning datasets from areas like cancer diagnosis and banknote authentication. Because perfect fit with tiny rule sets is not always possible, the authors relax the goal to achieve at least a chosen training accuracy and then search for the smallest models meeting that bar. They find that some datasets support highly stable minimal ensembles, while others show clear instability and sensitivity to noise. Tightening the required accuracy makes models less stable and sometimes impossible to find. To address this, the authors test selection rules that still favor small models but then choose, among all minimal ones, those that appear most often in bootstrap resamples or that are most robust to feature flips. These strategies slightly trade off raw accuracy for more reproducible and dependable explanations. 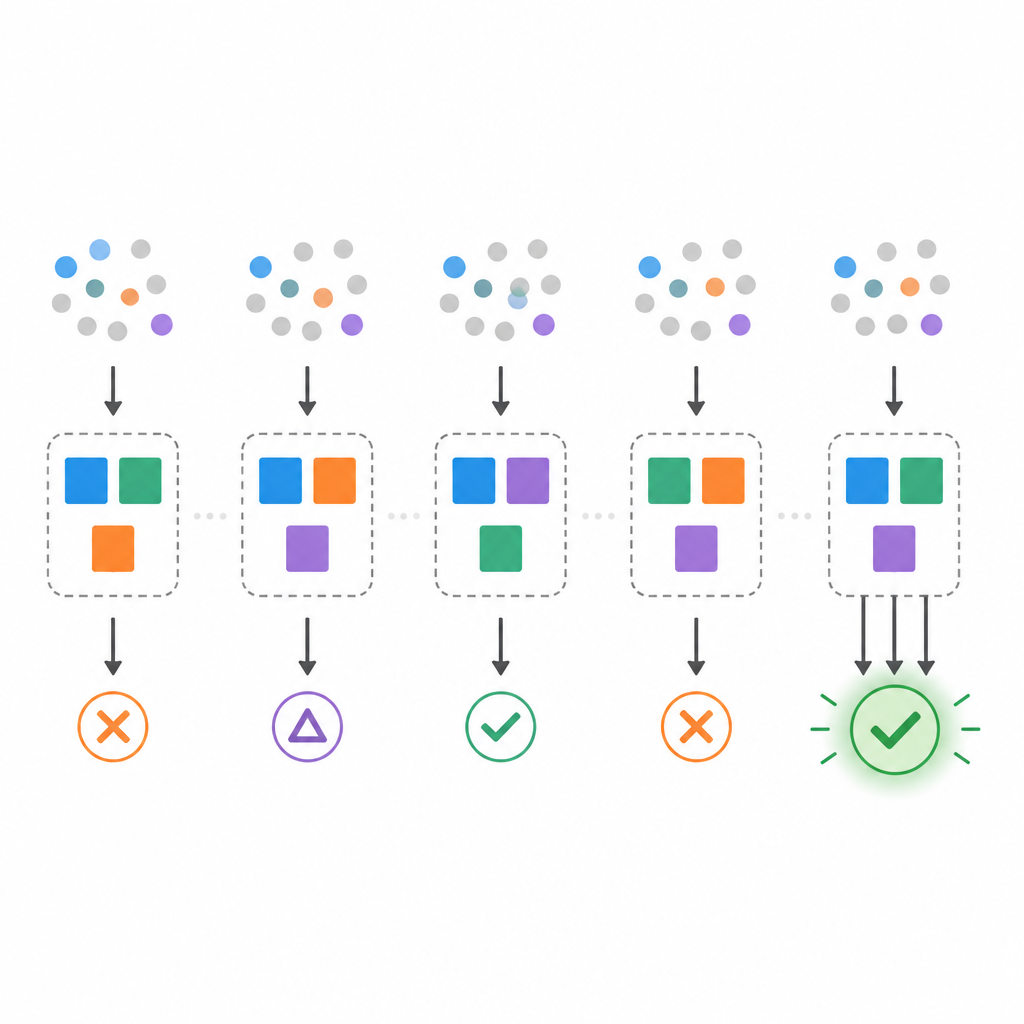
Why this matters for high-stakes decisions
For people who rely on transparent models in sensitive domains, the central message is that "smallest" does not always mean "safest." Two equally tiny rule sets can tell different stories about why a decision was made and can react differently to small changes in inputs. The authors show that it is practical to measure how stable and robust such models are and that reporting these measures alongside model size can warn users when explanations are brittle. In short, when building simple voting models for high-stakes decisions, one should first aim for compactness but then deliberately favor the versions that behave consistently across resampled or slightly perturbed data.
Citation: Li, Q., Huang, Z. & Pan, M. Stability and robustness of minimal majority vote interpretable ensembles. Sci Rep 16, 14877 (2026). https://doi.org/10.1038/s41598-026-45289-4
Keywords: interpretable models, majority vote, model stability, robustness, Rashomon effect