Clear Sky Science · fr
Stabilité et robustesse des ensembles interprétables de vote majoritaire minimaux
Pourquoi les petits modèles de vote comptent
Lorsque des ordinateurs aident à décider qui obtient un prêt, quel test médical réaliser ou comment détecter une fraude, les gens veulent comprendre les raisons de chaque décision. Une idée répandue consiste à utiliser des modèles très simples composés de règles oui/non qui votent pour la réponse. Ces modèles sont faciles à lire, mais l’étude à l’origine de cet article pose une question plus profonde : si l’on exige l’ensemble de règles le plus petit possible, obtient-on des explications fragiles qui changent trop facilement lorsque les données sont perturbées ?
Des votants par règles simples en termes clairs
L’article examine de petits systèmes basés sur des règles, appelés ensembles de vote majoritaire. Chaque règle regarde une caractéristique binaire, par exemple si une valeur dépasse un seuil, et émet un vote pour l’un des deux résultats. La décision finale est issue de la majorité des votes. Les auteurs se concentrent sur des modèles minimaux, c’est‑à‑dire qui utilisent le moins de règles nécessaire pour ajuster les données d’entraînement. Ces modèles sont très attractifs pour l’explicabilité, car un humain peut, en principe, lire toutes les règles et comprendre comment les décisions sont prises.
De nombreuses réponses minimales différentes
Cependant, les données réelles permettent souvent plus d’un modèle minimal. L’équipe montre qu’il peut exister de nombreux ensembles de règles minimaux différents qui s’ajustent parfaitement aux mêmes données, une situation parfois appelée effet Rashomon. Pour étudier cela, ils proposent trois mesures. D’abord, le taux de multiplicité compte la fréquence à laquelle il existe plus d’un modèle minimal pour un jeu de données. Ensuite, la stabilité par bootstrap vérifie la similitude des modèles minimaux sélectionnés lorsque les données sont légèrement rééchantillonnées. Enfin, la robustesse aux inversions de caractéristiques teste la tenue du modèle choisi lorsque des bits d’entrée individuels sont aléatoirement inversés, mimant des données bruitées ou décalées. 
Ce que révèlent des expériences soignées
En utilisant des jeux de données synthétiques contrôlés, les auteurs implantent un modèle de vote connu puis tentent de retrouver des modèles minimaux à partir d’échantillons réduits. Ils constatent que la précision sur des données de test propres peut être élevée même lorsque la stabilité est faible. Avec très peu d’exemples d’entraînement, de nombreux modèles minimaux différents apparaissent, et les ensembles de règles choisis d’un rééchantillonnage à l’autre ne se recoupent que modérément. À mesure que le nombre d’échantillons augmente, ces instabilités diminuent : la multiplicité baisse, la stabilité par bootstrap augmente et la robustesse aux inversions de caractéristiques s’améliore. Pour des tailles d’échantillon modérées, le modèle minimal retrouvé correspond presque au modèle implanté, et collecter encore plus de données n’apporte que de faibles gains.
Jeux de données réels et choix pratiques
L’étude se tourne ensuite vers des jeux de données classiques en apprentissage automatique, issus de domaines comme le diagnostic du cancer ou l’authentification de billets. Parce qu’un ajustement parfait avec de très petits ensembles de règles n’est pas toujours possible, les auteurs relâchent l’objectif pour atteindre au moins une précision d’entraînement choisie, puis recherchent les plus petits modèles satisfaisant ce seuil. Ils trouvent que certains jeux de données supportent des ensembles minimaux très stables, tandis que d’autres montrent une instabilité marquée et une sensibilité au bruit. Renforcer la précision requise rend les modèles moins stables et parfois impossibles à trouver. Pour y remédier, les auteurs testent des règles de sélection qui favorisent toujours les modèles petits mais choisissent, parmi tous les minimaux, ceux qui apparaissent le plus souvent dans les rééchantillonnages bootstrap ou qui sont les plus robustes aux inversions de caractéristiques. Ces stratégies sacrifient légèrement la précision brute au profit d’explications plus reproductibles et fiables. 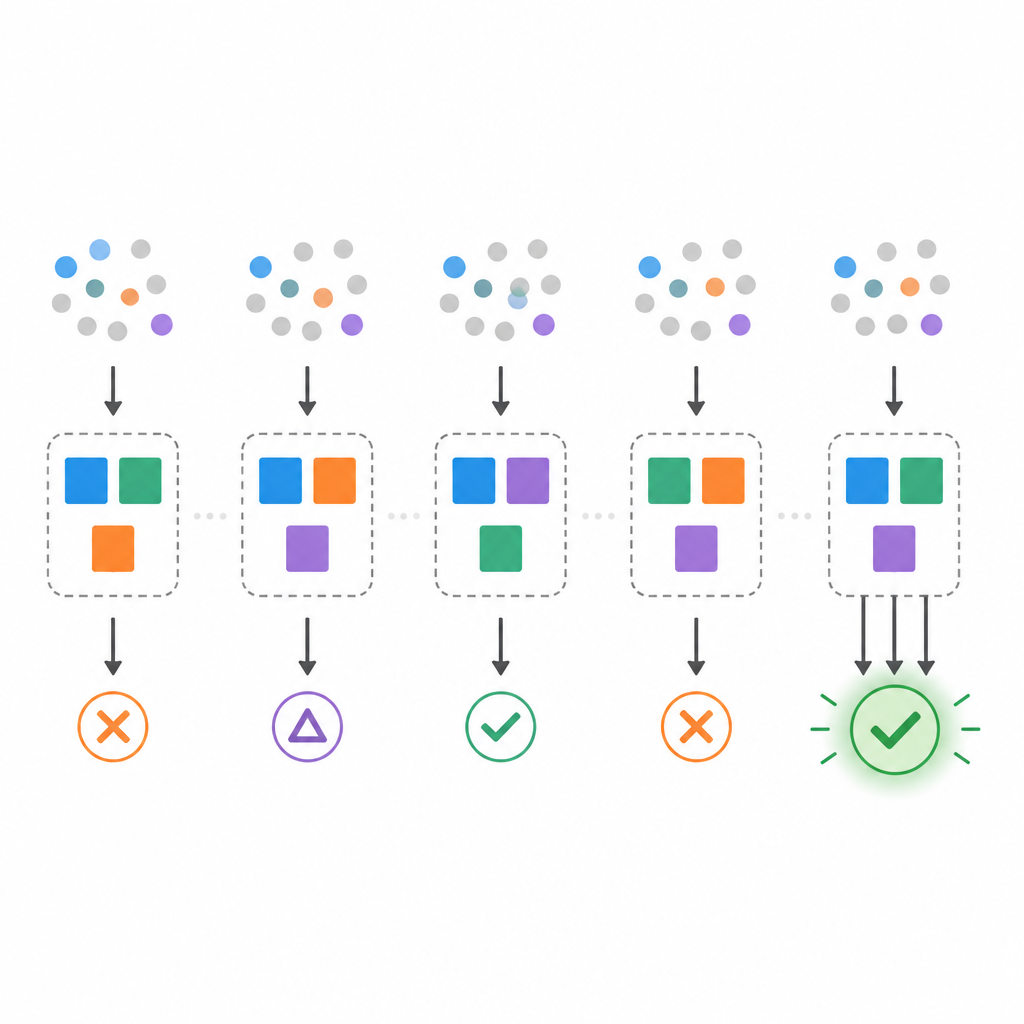
Pourquoi cela compte pour les décisions à fort enjeu
Pour les personnes s’appuyant sur des modèles transparents dans des domaines sensibles, le message central est que « le plus petit » n’est pas toujours « le plus sûr ». Deux ensembles de règles tout aussi minuscules peuvent raconter des histoires différentes sur la raison d’une décision et réagir différemment à de petites variations des entrées. Les auteurs montrent qu’il est pratique de mesurer la stabilité et la robustesse de tels modèles et que rapporter ces mesures en plus de la taille du modèle peut alerter les utilisateurs lorsque les explications sont fragiles. En bref, lors de la construction de modèles de vote simples pour des décisions à fort enjeu, on doit d’abord viser la compacité puis privilégier délibérément les versions qui se comportent de manière cohérente sur des données rééchantillonnées ou légèrement perturbées.
Citation: Li, Q., Huang, Z. & Pan, M. Stability and robustness of minimal majority vote interpretable ensembles. Sci Rep 16, 14877 (2026). https://doi.org/10.1038/s41598-026-45289-4
Mots-clés: modèles interprétables, vote majoritaire, stabilité du modèle, robustesse, effet Rashomon