Clear Sky Science · de
Stabilität und Robustheit minimaler Mehrheitsabstimmungs‑ensembles mit Interpretierbarkeit
Warum kleine Abstimmungsmodelle wichtig sind
Wenn Computer mitentscheiden, wer einen Kredit erhält, welcher medizinische Test durchgeführt wird oder wie Betrug erkannt wird, wollen Menschen die Gründe für jede Entscheidung verstehen. Eine verbreitete Idee ist die Verwendung sehr kleiner Modelle aus einfachen Ja‑/Nein‑Regeln, die über die Antwort abstimmen. Diese Modelle sind leicht lesbar; die hier vorgestellte Studie stellt jedoch eine tiefere Frage: Wenn wir auf die kleinste mögliche Regelmenge bestehen, führen wir dann zu Erklärungen, die brüchig sind und sich bei kleinen Störungen der Daten zu leicht ändern?
Einfache Regel‑Wähler in klarer Sprache
Das Papier untersucht winzige regelbasierte Systeme, die als Mehrheits‑Abstimmungsensembles bekannt sind. Jede Regel prüft ein Ja‑/Nein‑Merkmal, etwa ob ein Wert über einem Schwellenwert liegt, und gibt eine Stimme für eines von zwei Ergebnissen ab. Die finale Entscheidung ergibt sich aus der Mehrheit dieser Stimmen. Die Autoren konzentrieren sich auf Modelle, die minimal sind, also die geringste Anzahl an Regeln verwenden, um die Trainingsdaten zu erklären. Solche Modelle sind für Erklärbarkeit besonders attraktiv, weil ein Mensch im Prinzip alle Regeln lesen und nachvollziehen kann, wie Entscheidungen getroffen werden.
Viele verschiedene kleinste Antworten
In realen Daten existieren jedoch häufig mehr als ein kleinstes Modell. Das Team zeigt, dass es viele verschiedene minimale Regelmengen geben kann, die alle dieselben Daten perfekt erklären — eine Situation, die man manchmal als Rashomon‑Effekt bezeichnet. Um das zu untersuchen, schlagen sie drei Messgrößen vor. Erstens erfasst die Multiplikitätsrate, wie oft es für einen Datensatz mehr als ein minimales Modell gibt. Zweitens prüft die Bootstrap‑Stabilität, wie ähnlich die ausgewählten minimalen Modelle sind, wenn die Daten leicht neu gezogen werden. Drittens testet die Feature‑Flip‑Robustheit, wie gut ein gewähltes Modell hält, wenn einzelne Eingabebits zufällig gekippt werden, um verrauschte oder verschobene Daten zu simulieren. 
Was sorgfältige Experimente zeigen
Anhand kontrollierter synthetischer Datensätze setzen die Autoren ein bekanntes Abstimmungsmodell ein und versuchen dann, minimale Modelle aus kleinen Stichproben wiederzuerlangen. Sie finden, dass die Genauigkeit auf sauberen Testdaten hoch sein kann, selbst wenn die Stabilität gering ist. Bei sehr wenigen Trainingsbeispielen treten viele verschiedene minimale Modelle auf, und die Regelmengen, die aus einer Resample‑Stichprobe zur nächsten gewählt werden, überschneiden sich nur mäßig. Mit wachsender Stichprobengröße nehmen diese Instabilitäten ab: Die Multiplikität sinkt, die Bootstrap‑Stabilität steigt und die Robustheit gegen Feature‑Flips verbessert sich. Bei moderaten Stichprobengrößen stimmt das rekonstruierte minimale Modell nahezu mit dem eingesetzten überein, und das Sammeln noch mehr Daten bringt nur geringe Verbesserungen.
Echte Datensätze und praktische Entscheidungen
Die Studie wendet sich dann klassischen Machine‑Learning‑Datensätzen aus Bereichen wie Krebsdiagnose und Geldschein‑Authentifizierung zu. Da ein perfektes Fit mit winzigen Regelmengen nicht immer möglich ist, lockern die Autoren das Ziel: Es soll mindestens eine vorgegebene Trainingsgenauigkeit erreicht werden, und unter diesen Voraussetzungen suchen sie nach den kleinsten Modellen. Sie finden, dass manche Datensätze sehr stabile minimale Ensembles zulassen, während andere deutliche Instabilität und Empfindlichkeit gegenüber Rauschen zeigen. Das Anziehen der geforderten Genauigkeit macht Modelle weniger stabil und in manchen Fällen unmöglich zu finden. Um dem zu begegnen, testen die Autoren Selektionsregeln, die zwar kleine Modelle bevorzugen, aber unter allen minimalen diejenigen auswählen, die in Bootstrap‑Resamples am häufigsten erscheinen oder die am robustesten gegenüber Feature‑Flips sind. Diese Strategien tauschen etwas rohe Genauigkeit gegen besser reproduzierbare und verlässlichere Erklärungen ein. 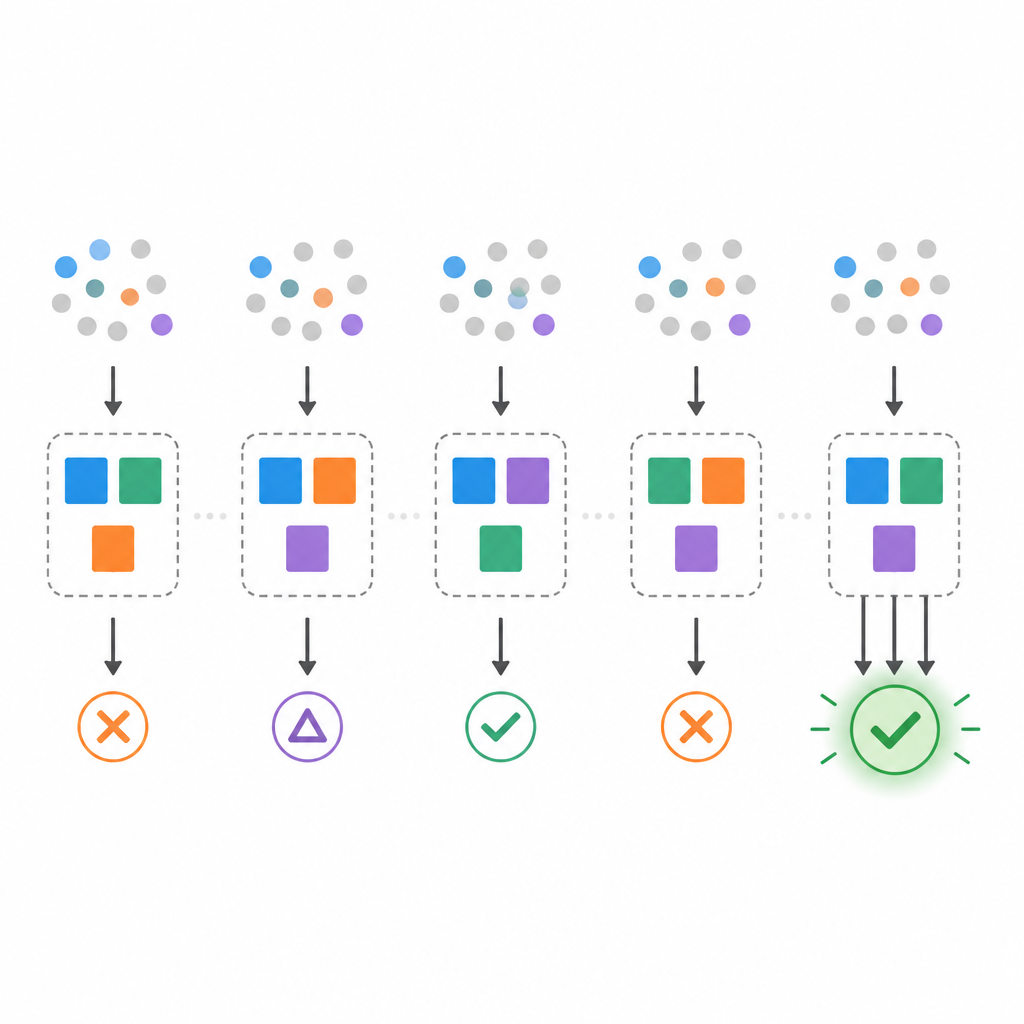
Warum das für Entscheidungen mit hohem Einsatz wichtig ist
Für Menschen, die in sensiblen Bereichen auf transparente Modelle angewiesen sind, lautet die zentrale Botschaft: „am kleinsten“ heißt nicht immer „am sichersten“. Zwei gleichermaßen winzige Regelmengen können unterschiedliche Geschichten darüber erzählen, warum eine Entscheidung getroffen wurde, und unterschiedlich auf kleine Eingabeänderungen reagieren. Die Autoren zeigen, dass es praktikabel ist, zu messen, wie stabil und robust solche Modelle sind, und dass das Berichtigen dieser Maße neben der Modellgröße Nutzer warnen kann, wenn Erklärungen brüchig sind. Kurz gesagt: Beim Aufbau einfacher Abstimmungsmodelle für Entscheidungen mit hohem Einsatz sollte man zwar Kompaktheit anstreben, dann aber bewusst die Versionen bevorzugen, die sich über Resamples oder leicht gestörte Daten hinweg konsistent verhalten.
Zitation: Li, Q., Huang, Z. & Pan, M. Stability and robustness of minimal majority vote interpretable ensembles. Sci Rep 16, 14877 (2026). https://doi.org/10.1038/s41598-026-45289-4
Schlüsselwörter: interpretierbare Modelle, Mehrheitsabstimmung, Modellstabilität, Robustheit, Rashomon‑Effekt