Clear Sky Science · it
Stabilità e robustezza degli ensemble interpretabili a voto di maggioranza minimo
Perché i piccoli modelli di voto contano
Quando i computer aiutano a decidere chi ottiene un prestito, quale esame medico eseguire o come identificare frodi, le persone vogliono capire le ragioni dietro ogni decisione. Un’idea popolare è usare modelli molto piccoli composti da semplici regole sì/no che votano sulla risposta. Questi modelli sono facili da leggere, ma lo studio all’origine di questo articolo pone una domanda più profonda: se insistiamo sul set di regole più piccolo possibile, otteniamo spiegazioni fragili che cambiano troppo facilmente quando i dati vengono alterati?
Semplici votanti a regole in parole semplici
Il lavoro esamina piccoli sistemi basati su regole noti come ensemble a voto di maggioranza. Ogni regola osserva una caratteristica sì/no, per esempio se un valore supera una soglia, e vota per uno dei due esiti. La decisione finale deriva dalla maggioranza dei voti. Gli autori si concentrano su modelli che sono minimi, cioè che usano il minor numero di regole necessario per adattarsi ai dati di addestramento. Tali modelli sono molto attrattivi per l’esplicabilità, perché un essere umano può, in principio, leggere tutte le regole e comprendere come vengono prese le decisioni.
Molte risposte diverse più piccole
Tuttavia, i dati reali spesso permettono più di un modello minimo. Il team mostra che possono esistere molti insiemi minimi di regole diversi che si adattano perfettamente agli stessi dati, una situazione talvolta chiamata effetto Rashomon. Per studiare questo fenomeno propongono tre misure. Primo, il tasso di molteplicità conta quanto spesso esiste più di un modello minimo per un dataset. Secondo, la stabilità bootstrap verifica quanto siano simili i modelli minimi selezionati quando i dati sono leggermente risamplati. Terzo, la robustezza ai flip di feature testa quanto bene un modello scelto resiste quando singoli bit di input vengono casualmente invertiti, imitandone il rumore o lo spostamento. 
Cosa rivelano esperimenti accurati
Usando dataset sintetici controllati, gli autori impiantano un modello di voto noto e poi cercano di recuperare modelli minimi da campioni piccoli. Riscontrano che l’accuratezza su dati di test puliti può essere elevata anche quando la stabilità è scarsa. Con pochissimi esempi di addestramento emergono molti modelli minimi diversi, e gli insiemi di regole scelti da un risample all’altro si sovrappongono solo in misura modesta. All’aumentare del numero di campioni, queste instabilità diminuiscono: la molteplicità cala, la stabilità bootstrap aumenta e migliora la robustezza ai flip delle feature. A dimensioni campionarie moderate, il modello minimo recuperato corrisponde quasi a quello impiantato, e raccogliere ancora più dati porta solo a guadagni limitati.
Dataset reali e scelte pratiche
Lo studio passa poi a dataset classici di machine learning provenienti da ambiti come la diagnosi del cancro e l’autenticazione di banconote. Poiché l’adattamento perfetto con insiemi di regole molto piccoli non è sempre possibile, gli autori rilassano l’obiettivo per raggiungere almeno una certa accuratezza di addestramento scelta e quindi cercano i modelli più piccoli che soddisfano quel requisito. Scoprono che alcuni dataset supportano ensemble minimi altamente stabili, mentre altri mostrano chiara instabilità e sensibilità al rumore. Restringere l’accuratezza richiesta rende i modelli meno stabili e talvolta impossibili da trovare. Per affrontare questo problema, gli autori testano regole di selezione che continuano a favorire modelli piccoli ma che, tra tutti i minimi, scelgono quelli che compaiono più spesso nei risample bootstrap o che sono più robusti ai flip di feature. Queste strategie scambiano leggermente parte dell’accuratezza grezza in favore di spiegazioni più riproducibili e affidabili. 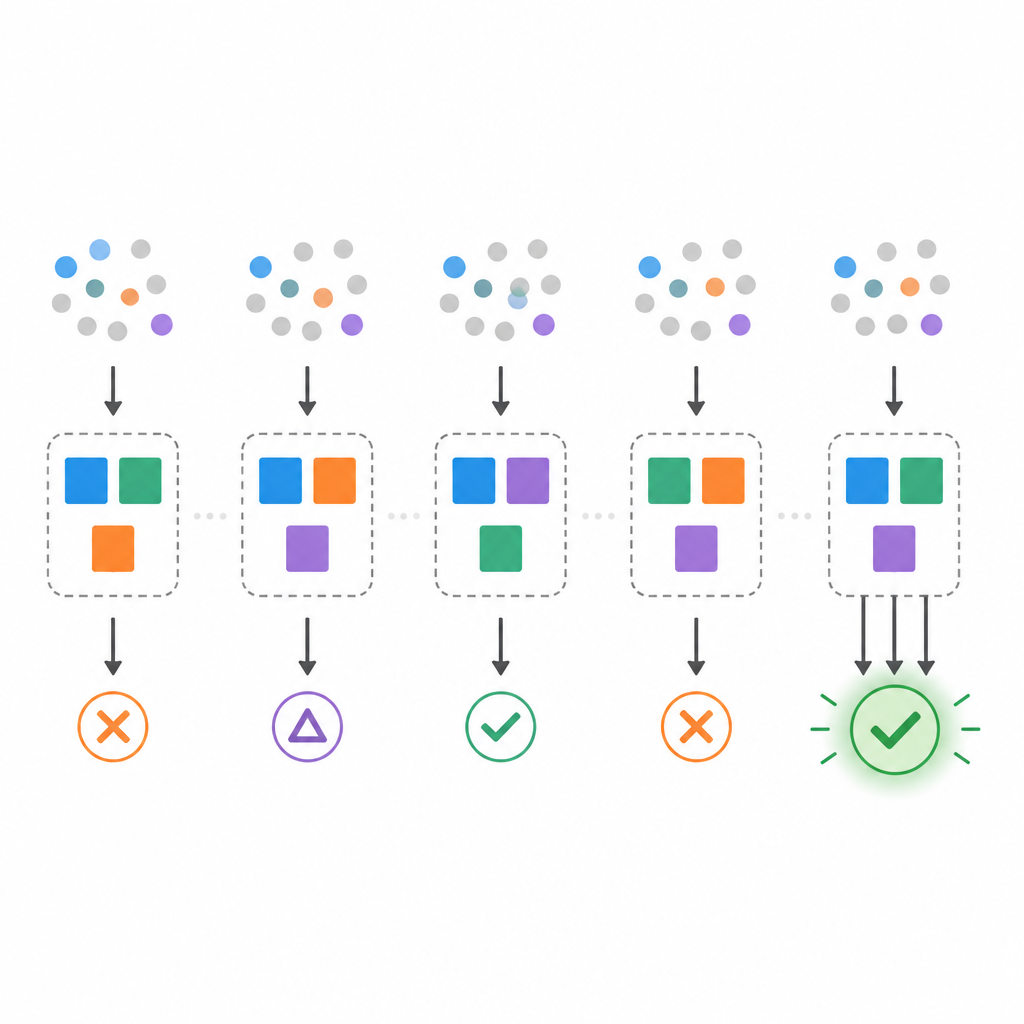
Perché questo conta nelle decisioni ad alta posta in gioco
Per chi fa affidamento su modelli trasparenti in ambiti sensibili, il messaggio centrale è che «più piccolo» non significa sempre «più sicuro». Due set di regole ugualmente minuti possono raccontare storie diverse sul motivo di una decisione e reagire in modo differente a piccoli cambiamenti negli input. Gli autori dimostrano che è pratico misurare quanto questi modelli siano stabili e robusti e che riportare queste misure insieme alla dimensione del modello può avvisare gli utenti quando le spiegazioni sono fragili. In sintesi, nella costruzione di semplici modelli di voto per decisioni ad alta posta in gioco, si dovrebbe puntare prima alla compattezza ma poi favorire deliberatamente le versioni che si comportano in modo coerente attraverso risample o piccole perturbazioni dei dati.
Citazione: Li, Q., Huang, Z. & Pan, M. Stability and robustness of minimal majority vote interpretable ensembles. Sci Rep 16, 14877 (2026). https://doi.org/10.1038/s41598-026-45289-4
Parole chiave: modelli interpretabili, voto di maggioranza, stabilità del modello, robustezza, effetto Rashomon