Clear Sky Science · nl
Restauratie van archieffilm met grote gebieden van structurele schade
Waarom het behoud van oude films nog steeds belangrijk is
Veel van de films en nieuwsreelbeelden die de vorige eeuw vastlegden, bestaan nu alleen nog op kwetsbare filmrollen. Tijd, stof, herhaald afspelen en slechte opslag hebben krassen en gaten in deze beelden gesleten, waardoor gezichten, objecten en zelfs hele delen van scènes zijn verdwenen. Dergelijke schade handmatig frame voor frame herstellen is uiterst traag en kostbaar. Dit artikel introduceert een nieuwe methode met kunstmatige intelligentie die automatisch grote, onregelmatige defecten in archieffilm kan detecteren en repareren, wat sneller en trouwere redding van de bewegende-beeldgeschiedenis belooft.
Wat film schade zo lastig maakt
Niet alle gebreken in oude film zijn hetzelfde. Sommige problemen—zoals korrelig ruis, algemene onscherpte of vervaagde kleuren—tasten het hele beeld aan en zijn te behandelen met brede opschoningsmiddelen. De meest verwoestende problemen zijn echter structurele schade zoals lange verticale krassen of vlekkerige zwart-witplekken. Deze vernietigen beeldinhoud in plaats van die alleen te degraderen. Traditionele digitale methoden vertrouwen ofwel op handgemaakte regels of behandelen elk frame afzonderlijk, waardoor bewegende objecten vaak verward worden met schade of grote gaten slechts deels worden hersteld. Tegelijkertijd kunnen volledig end-to-end ’black box’-systemen die alles in één stap proberen te reinigen en op te vullen beschadigde gebieden missen of scherpe maar onrealistische details verzinnen.
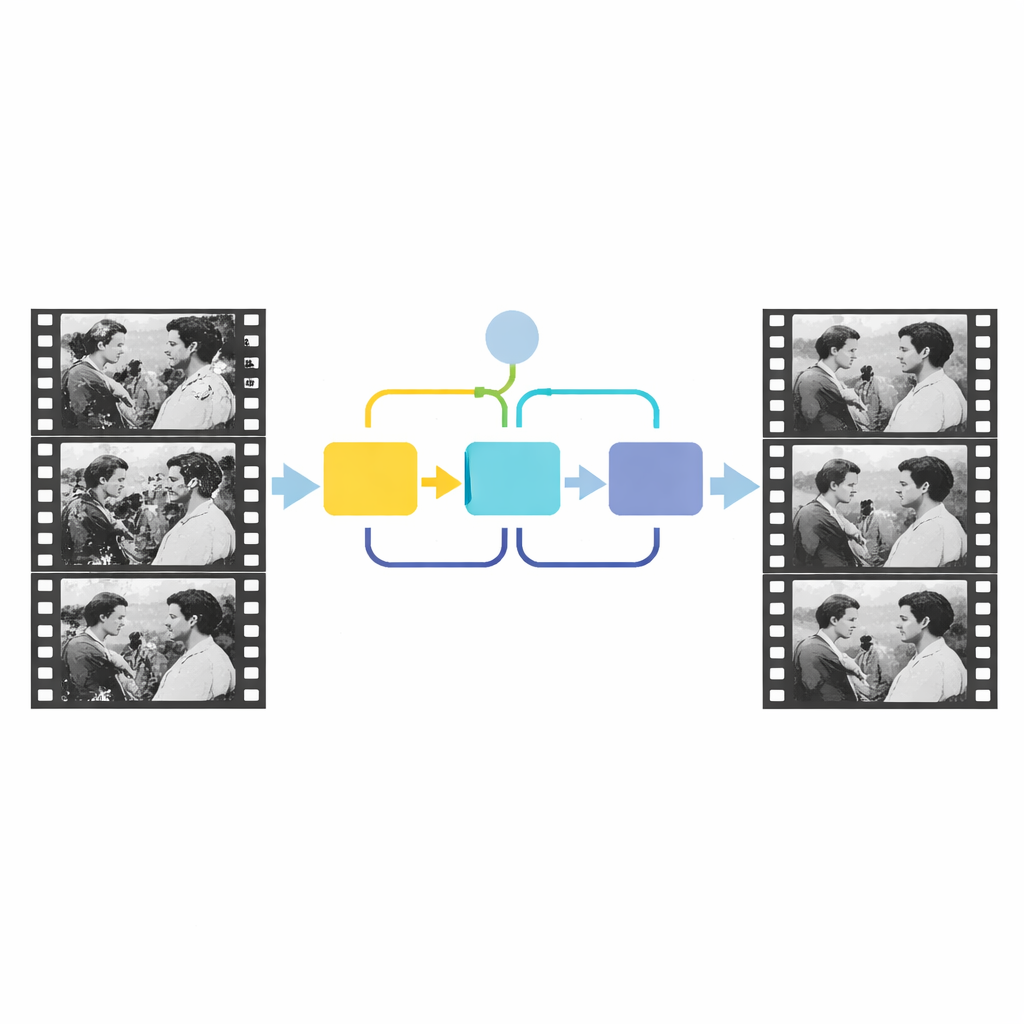
Door de tijd kijken om defecten te vinden
De belangrijkste inzicht van het nieuwe werk is om tijd te gebruiken, niet alleen ruimte. Reële scène-inhoud verandert geleidelijk van frame naar frame, terwijl krassen en vlekken op willekeurige plekken verschijnen en de actie niet volgen. De auteurs modelleren dit verschil door drie naburige frames in te voeren in een detectienetwerk dat nabootst hoe een menselijke waarnemer heen en weer bladert om anomalieën te spotten. Eerst vergelijkt een channel-attentionmodule de algemene inhoud van de drie frames en markeert regio’s waarvan het gedrag in de tijd niet overeenkomt met de rest van de scène. Deze fase geeft een grove indicatie waar schade zou kunnen zitten. Vervolgens zoomt een tweede module, genoemd source-reference-attentionmodule, in op lokale details en gebruikt informatie uit een relatief schoon naburig frame om de randen en vorm van het beschadigde gebied te verfijnen. Samen leveren deze stappen een nauwkeurig masker dat de structurele defecten omlijnt.
Het systeem trainen met beperkte echte voorbeelden
Aangezien echt beschadigd archiefmateriaal met perfecte ground-truth labels schaars is en duur om te annoteren, gebruikt het team een slimme trainingsstrategie. Ze creëren eerst een grote synthetische dataset door onregelmatige maskers—die krassen en vlekken voorstellen—over echte filmframes te leggen. Dit stelt de detector in staat het basale idee van zeldzame, tijdsonafhankelijke schade te leren. In een tweede fase wordt het model verfijnd met een kleine set echt beschadigde sequenties waarvan de labels niet perfect nauwkeurig maar wel informatief zijn. Door ideale synthetische supervisie te combineren met onvolmaakte real-world begeleiding, leert het systeem wat het uit schone simulaties weet over te dragen naar rommelig historisch materiaal, terwijl multi-schaals feature-fusie helpt omgaan met zowel kleine spikkels als brede ontbrekende gebieden.
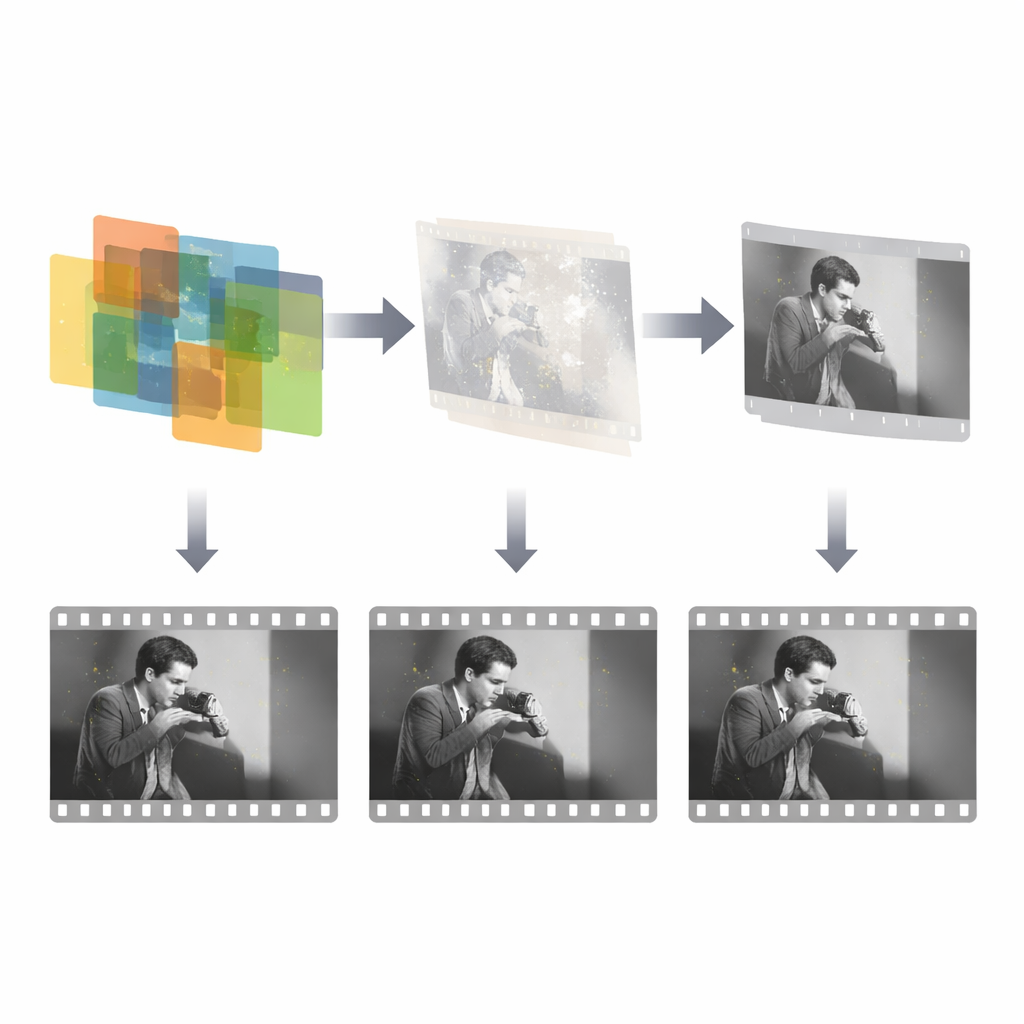
Hoe gebroken beelden weer worden opgevuld
Zodra het schademasker bekend is, richt een apart reparatienetwerk zich uitsluitend op het reconstrueren van de ontbrekende inhoud. Dit netwerk neemt drie inputs: het beschadigde frame, het gedetecteerde masker en één naburig referentiekader dat nog de intacte scène bevat. Het gebruikt vervolgens een generatief adversariaal kader om plausibele vervangingen binnen de gemaskerde gaten te synthetiseren, geleid door meerdere verliesfuncties die nauwkeurigheid, visuele realiteit en een consistente stijl aanmoedigen. Belangrijk is dat het systeem benut dat schade slechts een klein deel van elk frame inneemt en tijdsonafhankelijk is, zodat het zijn inspanning kan concentreren op die sporadische regio’s in plaats van het hele beeld opnieuw te leren. Het ontwerp is opzettelijk eenvoudig en efficiënt: slechts drie frames voor detectie en één referentiekader voor reparatie, wat overeenkomt met hoe een menselijke restaurator meestal maar een paar buren controleert bij het repareren van een defect.
Hoe goed het in de praktijk werkt
Om hun aanpak te testen, voegen de auteurs gesimuleerde krassen en vlekken toe aan schone archiefclips uit een openbare dataset en vergelijken ze hun systeem met meerdere sterke baselines, waaronder klassieke patchdetectoren en moderne deep-learningrestaurateurs voor foto’s en films. Hun detector verdubbelt meer dan de overlapmaat (mean intersection over union) ten opzichte van deze baselines, wat betekent dat hij beschadigde pixels veel nauwkeuriger vindt. Voor reconstructiekwaliteit, gemeten met piek signaal-ruisverhouding en structurele gelijkenis, presteert hun methode opnieuw duidelijk beter dan anderen en laat vooral grote winst zien wanneer gebruik wordt gemaakt van de eigen maskers. Bij echt archiefmateriaal tonen visuele vergelijkingen dat concurrerende methoden ofwel delen van de schade missen, details oververscherpen tot onnatuurlijke texturen, of volledig falen bij grote ontbrekende gebieden, terwijl het nieuwe systeem lange krassen en grote vlekken volledig kan verwijderen met vloeiende, consistente opvullingen—en dat allemaal terwijl het hd-sequenties in fracties van een seconde per frame verwerkt.
Wat dit betekent voor ons bewegende-beeldverleden
In eenvoudige termen laat de studie zien dat het zorgvuldig modelleren van hoe schade zich in de tijd gedraagt het mogelijk maakt automatisch oude films te herstellen die anders beschadigd of onbruikbaar zouden blijven. Door eerst te bepalen waar de film gebroken is en vervolgens naburige frames te gebruiken om alleen die regio’s opnieuw op te bouwen, levert de methode schonere resultaten dan all-in-one-benaderingen en doet dat met minder rekenwerk. Hoewel perfecte detectie van elke kras nog buiten bereik is, betekent dit kader een belangrijke stap richting betaalbare, grootschalige digitale restauratie van historische speelfilms, nieuwsreels en homevideo’s, en helpt het visuele herinneringen voor toekomstige generaties te behouden.
Bronvermelding: Liu, Q., Liu, Y., Wang, L. et al. Restoration of archival film with large areas of structural damage. npj Herit. Sci. 14, 272 (2026). https://doi.org/10.1038/s40494-025-02235-3
Trefwoorden: restauratie van archieffilm, krassen- en vlekreparatie, video-inpainting, deep learning voor erfgoed, digitale bewaring