Clear Sky Science · fr
Restauration de films d’archives présentant de larges zones de détérioration structurelle
Pourquoi il est encore important de sauver les vieux films
Beauxoup des films et des actualités qui ont marqué le siècle dernier ne subsistent aujourd’hui que sur des bobines de film fragiles. Le temps, la poussière, les projections répétées et un mauvais stockage ont creusé des rayures et percé des trous dans ces images, effaçant des visages, des objets et même des parties entières de scènes. Corriger manuellement ces dégâts image par image est extrêmement lent et coûteux. Cet article présente une nouvelle méthode d’intelligence artificielle capable de détecter et de réparer automatiquement de larges défauts irréguliers dans les films d’archives, promettant une restauration de l’histoire de l’image en mouvement plus rapide et plus fidèle.
Ce qui rend les dommages sur film si difficiles
Toutes les altérations des vieux films ne se ressemblent pas. Certains problèmes — comme le bruit granuleux, le flou général ou la décoloration — affectent l’ensemble de l’image et peuvent être traités par des outils de nettoyage généraux. Les problèmes les plus dévastateurs sont toutefois des détériorations structurelles, comme de longues rayures verticales ou des taches noires et blanches. Celles-ci détruisent le contenu de l’image plutôt que de le dégrader simplement. Les méthodes numériques traditionnelles reposent soit sur des règles conçues à la main, soit traitent chaque image indépendamment, confondant souvent des objets en mouvement avec des défauts ou ne réparant que partiellement de larges zones manquantes. De leur côté, les systèmes « boîte noire » tout-en-un qui tentent de nettoyer et de combler tout en une seule étape peuvent passer à côté des régions endommagées ou inventer des détails nets mais irréalistes.
Regarder à travers le temps pour repérer les défauts
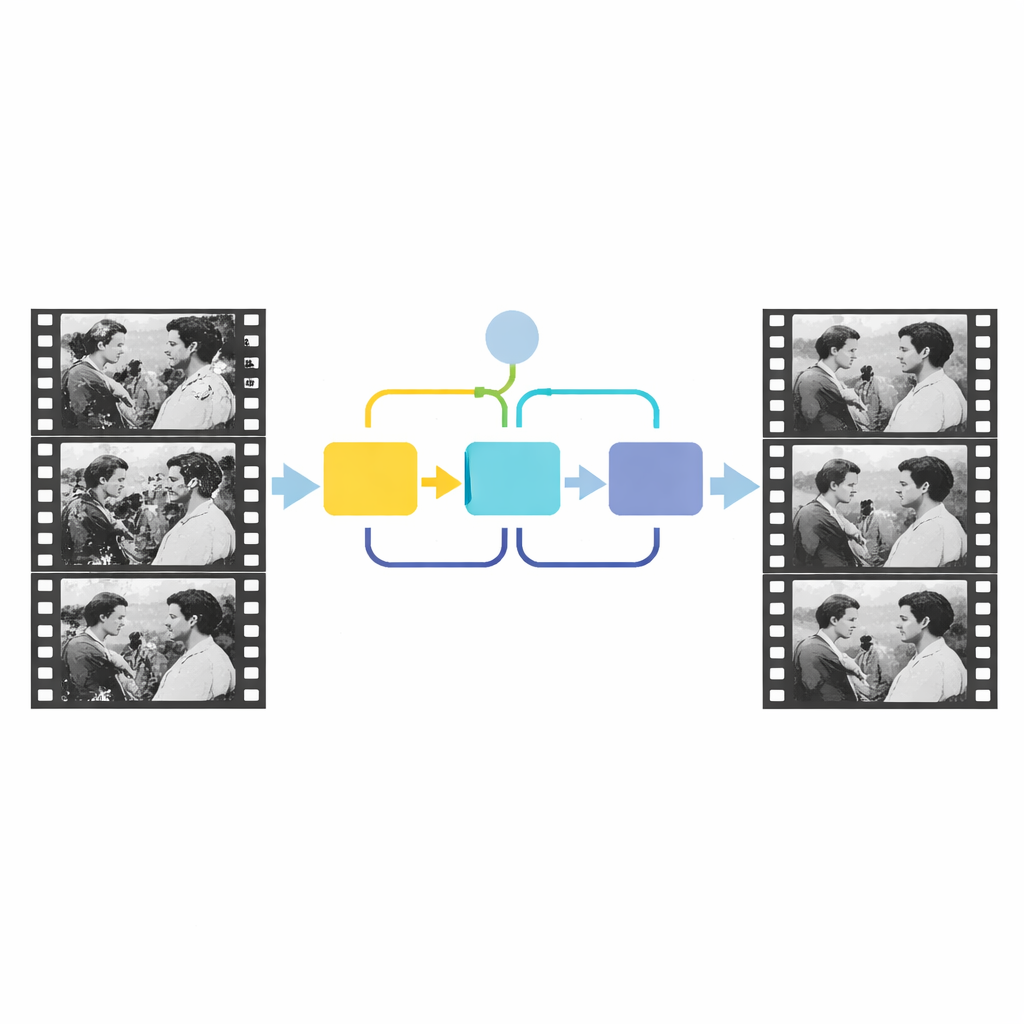
L’idée clé du travail présenté est d’exploiter le temps, pas seulement l’espace. Le contenu réel d’une scène évolue en douceur d’une image à l’autre, tandis que les rayures et taches apparaissent à des endroits aléatoires et ne suivent pas l’action. Les auteurs modélisent cette différence en alimentant un réseau de détection avec trois images voisines, imitant la façon dont un observateur humain feuillette en avant et en arrière pour repérer des anomalies. D’abord, un module d’attention par canal compare le contenu global des trois images et met en évidence les régions dont le comportement temporel ne correspond pas au reste de la scène. Cette étape donne une idée grossière des zones potentiellement endommagées. Ensuite, un second module, appelé module d’attention source-référence, se concentre sur les détails locaux, en utilisant l’information d’une image voisine relativement propre pour affiner les bords et la forme de la zone abîmée. Ensemble, ces étapes produisent un masque précis délimitant les défauts structurels.
Apprendre au système avec un nombre limité d’exemples réels
Parce que les séquences d’archives réellement endommagées avec des annotations de vérité-terrain parfaites sont rares et coûteuses à étiqueter, l’équipe utilise une stratégie d’entraînement ingénieuse. Ils créent d’abord un grand jeu de données synthétiques en superposant des masques irréguliers — représentant rayures et taches — sur de vraies images de film. Cela permet au détecteur d’apprendre le principe de dégâts clairsemés et non corrélés dans le temps. Dans une seconde phase, le modèle est affiné avec un petit ensemble de séquences endommagées réelles dont les étiquettes ne sont pas parfaitement exactes mais restent informatives. En combinant une supervision synthétique idéale avec un guidage réel imparfait, le système apprend à transférer ce qu’il a acquis sur des simulations propres vers du matériau historique désordonné, tandis que la fusion de caractéristiques multi-échelle l’aide à gérer à la fois les petites poussières et les larges régions manquantes.
Comment les images abîmées sont comblées
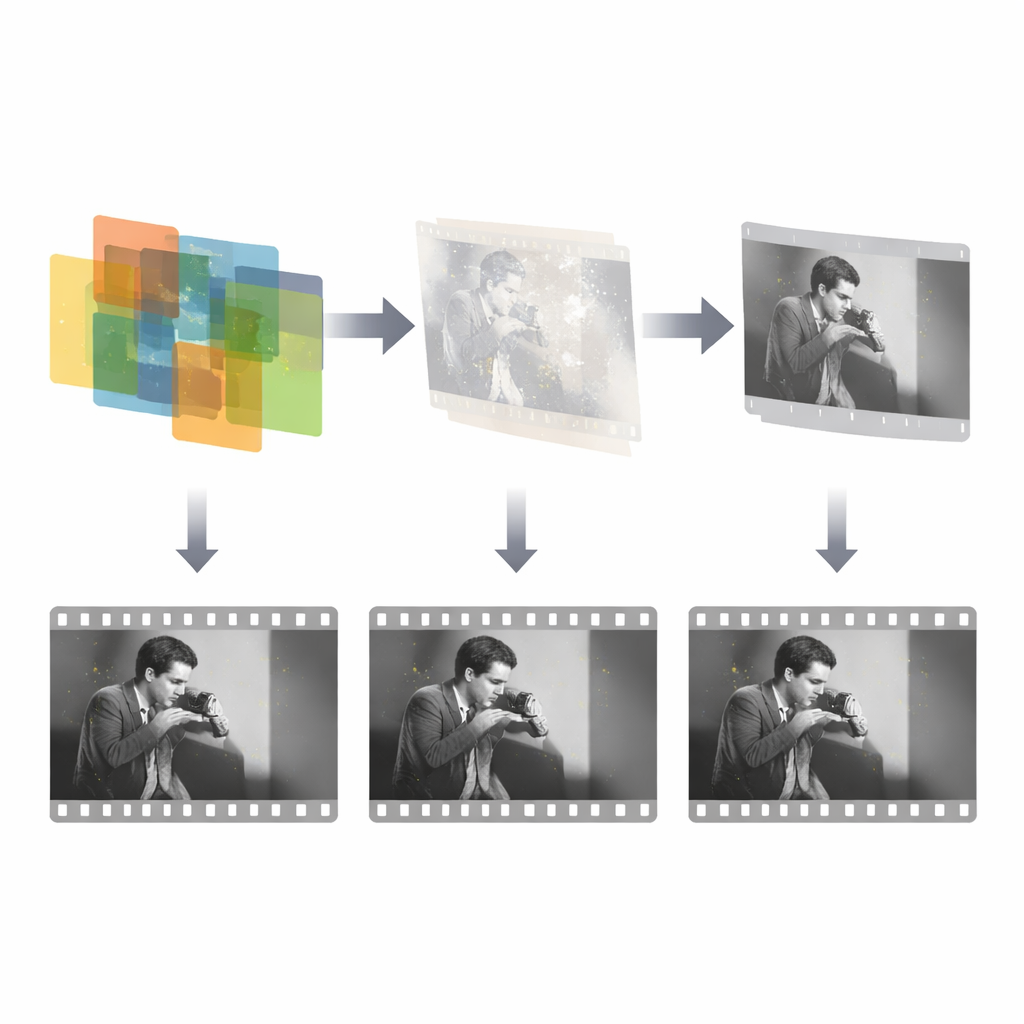
Une fois le masque des dégâts connu, un réseau de réparation séparé se concentre uniquement sur la reconstruction du contenu manquant. Ce réseau prend trois entrées : l’image endommagée, le masque détecté et une image de référence voisine qui contient encore la scène intacte. Il utilise ensuite un cadre génératif antagoniste pour synthétiser des remplacements plausibles à l’intérieur des trous masqués, guidé par plusieurs termes de perte qui encouragent la précision, le réalisme visuel et l’homogénéité stylistique. De manière importante, le système exploite le fait que les dégâts n’occupent qu’une petite fraction de chaque image et sont indépendants dans le temps, ce qui lui permet de concentrer ses efforts sur ces régions clairsemées plutôt que de réapprendre l’intégralité de l’image. La conception est volontairement simple et efficace : juste trois images pour la détection et une image de référence unique pour la réparation, rappelant la façon dont un restaurateur humain vérifie habituellement seulement quelques voisins pour colmater un défaut.
Quel est le niveau de performance en pratique
Pour évaluer leur approche, les auteurs ajoutent des rayures et taches simulées à des clips d’archives propres issus d’un jeu de données public et comparent leur système à plusieurs solides méthodes de référence, y compris des détecteurs de patchs classiques et des restaurateurs modernes basés sur l’apprentissage profond pour photos et films. Leur détecteur double plus que la mesure de recouvrement (intersection sur union moyenne) par rapport à ces références, ce qui signifie qu’il localise les pixels endommagés beaucoup plus précisément. Pour la qualité de reconstruction, mesurée par le rapport signal sur bruit de crête et la similarité structurelle, leur méthode surpasse à nouveau clairement les autres et montre des gains particulièrement importants lorsqu’elle utilise ses propres masques. Sur des séquences d’archives réelles, les comparaisons visuelles révèlent que les méthodes concurrentes manquent soit des parties des dégâts, soit surgissent des détails trop nets aux textures irréalistes, ou échouent complètement sur de larges zones manquantes, tandis que le nouveau système peut supprimer entièrement de longues rayures et de grosses taches avec des remplissages lisses et cohérents — tout en traitant des séquences haute définition en une fraction de seconde par image.
Ce que cela signifie pour notre passé en images animées
Concrètement, l’étude montre que modéliser soigneusement le comportement des dégâts dans le temps rend possible la restauration automatique de vieux films qui, autrement, resteraient marqués ou inutilisables. En identifiant d’abord où le film est rompu puis en utilisant des images voisines pour reconstruire uniquement ces régions, la méthode fournit des résultats plus propres que les approches tout-en-un tout en demandant moins de calcul. Bien que la détection parfaite de chaque rayure soit encore hors de portée, ce cadre représente une avancée significative vers une restauration numérique accessible et à grande échelle des films historiques, actualités et vidéos familiales, contribuant à préserver les souvenirs visuels pour les générations futures.
Citation: Liu, Q., Liu, Y., Wang, L. et al. Restoration of archival film with large areas of structural damage. npj Herit. Sci. 14, 272 (2026). https://doi.org/10.1038/s40494-025-02235-3
Mots-clés: restauration de films d’archives, réparation de rayures et taches, inpainting vidéo, apprentissage profond pour le patrimoine, préservation numérique