Clear Sky Science · it
Restauro di pellicole d’archivio con ampie aree di danno strutturale
Perché salvare i film d’epoca conta ancora
Molti dei film e dei cinegiornali che hanno documentato il secolo scorso sopravvivono ormai solo su fragili bobine di pellicola. Il tempo, la polvere, la proiezione ripetuta e la conservazione inadeguata hanno inciso graffi e aperto buchi in queste immagini, cancellando volti, oggetti e persino intere parti delle scene. Riparare manualmente tali danni fotogramma per fotogramma è estremamente lento e costoso. Questo articolo presenta un nuovo metodo basato sull’intelligenza artificiale che è in grado di individuare e riparare automaticamente difetti grandi e irregolari nelle pellicole d’archivio, promettendo un recupero delle immagini in movimento più rapido e fedele alla realtà.
Cosa rende i danni della pellicola così complessi
Non tutti i difetti delle pellicole d’epoca sono uguali. Alcuni problemi — come il rumore granuloso, la sfocatura generale o i colori sbiaditi — riguardano l’intera immagine e possono essere trattati con strumenti di pulizia ampi. I problemi più devastanti, però, sono i danni strutturali come lunghi graffi verticali o macchie bianco-nerastre. Questi distruggono il contenuto dell’immagine invece di degradarlo semplicemente. I metodi digitali tradizionali si basano o su regole fatte a mano o trattano ogni fotogramma in modo indipendente, spesso scambiando oggetti in movimento per danni o lasciando grandi buchi solo parzialmente riparati. Allo stesso tempo, sistemi end-to-end "scatola nera" che tentano di pulire e riempire tutto in un unico passaggio possono non rilevare le aree danneggiate o inventare dettagli nitidi ma irrealistici.
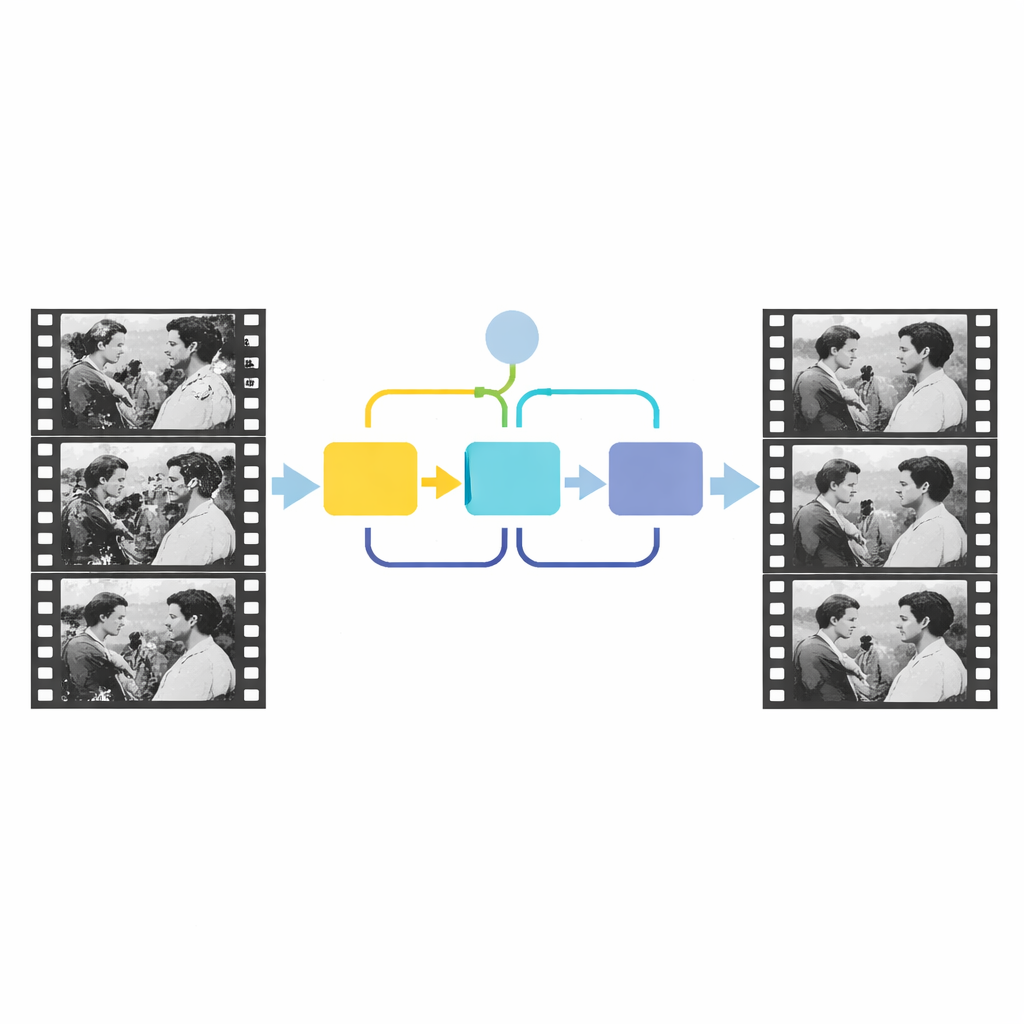
Guardare attraverso il tempo per individuare i difetti
L’intuizione chiave del nuovo lavoro è usare il tempo, non solo lo spazio. Il contenuto reale di una scena cambia in modo fluido da un fotogramma al successivo, mentre graffi e macchie compaiono in posizioni casuali e non seguono l’azione. Gli autori modellano questa differenza alimentando una rete di rilevamento con tre fotogrammi adiacenti, imitando il modo in cui un osservatore umano sfoglia avanti e indietro per individuare anomalie. Per prima cosa, un modulo di attenzione sui canali confronta il contenuto complessivo dei tre fotogrammi e mette in evidenza le regioni il cui comportamento temporale non corrisponde al resto della scena. Questa fase fornisce un’idea grossolana di dove potrebbe esserci danno. Poi un secondo modulo, chiamato modulo di attenzione sorgente-riferimento, si concentra sui dettagli locali, usando informazioni da un fotogramma di riferimento relativamente pulito per affinare i contorni e la forma dell’area danneggiata. Insieme, questi passaggi producono una maschera precisa che delimita i difetti strutturali.
Addestrare il sistema con pochi esempi reali
Poiché le pellicole d’archivio davvero danneggiate con etichette di verità a terra perfette sono scarse e costose da annotare, il team adotta una strategia di addestramento intelligente. Prima creano un ampio dataset sintetico sovrapponendo maschere irregolari — a simulare graffi e macchie — su fotogrammi reali. Questo permette al rilevatore di apprendere l’idea di danni sparsi e non correlati nel tempo. In una seconda fase, il modello viene rifinito con un piccolo insieme di sequenze danneggiate reali le cui etichette non sono perfettamente accurate ma comunque informative. Combinando una supervisione sintetica ideale con una guida imperfetta del mondo reale, il sistema impara a trasferire quanto appreso dalle simulazioni pulite al materiale storico più caotico, mentre la fusione di caratteristiche a più scale lo aiuta a gestire sia punteggiature minute sia ampie regioni mancanti.
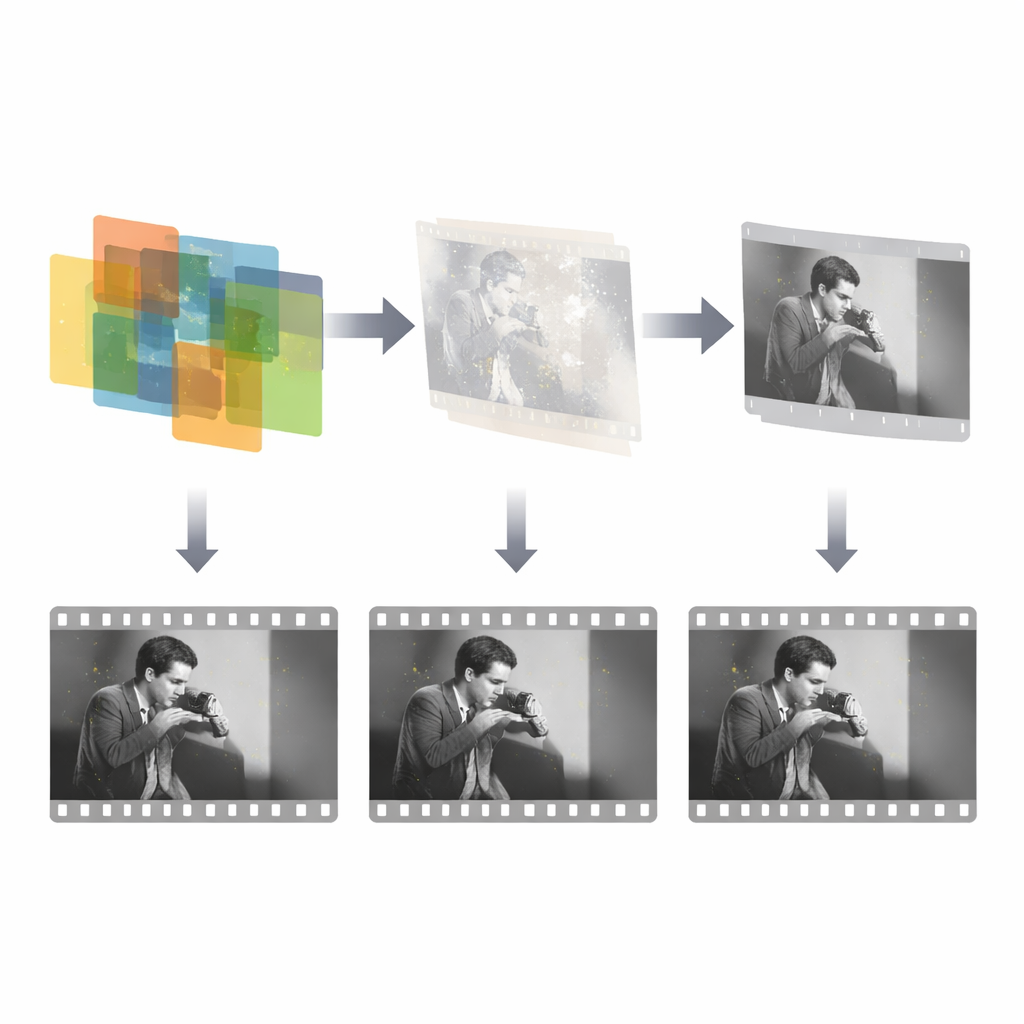
Come le immagini danneggiate vengono ricostruite
Una volta nota la maschera del danno, una rete di riparazione separata si concentra esclusivamente sulla ricostruzione del contenuto mancante. Questa rete prende tre input: il fotogramma danneggiato, la maschera rilevata e un fotogramma di riferimento vicino che contiene ancora la scena intatta. Usa quindi un framework generativo avversario per sintetizzare sostituzioni plausibili all’interno dei fori mascherati, guidata da più termini di perdita che favoriscono accuratezza, realismo visivo e coerenza stilistica. È importante che il sistema sfrutti il fatto che il danno occupa solo una piccola frazione di ogni fotogramma ed è indipendente nel tempo, quindi può concentrare lo sforzo su quelle regioni sparse invece di tentare di rieducare l’intera immagine. Il progetto è intenzionalmente semplice ed efficiente: solo tre fotogrammi per il rilevamento e un singolo fotogramma di riferimento per la riparazione, richiamando il modo in cui un restauratore umano controlla tipicamente uno o pochi vicini quando ripara un difetto.
Quanto funziona bene nella pratica
Per testare il loro approccio, gli autori aggiungono graffi e macchie simulati a clip d’archivio pulite tratte da un dataset pubblico e confrontano il loro sistema con diverse solide baseline, inclusi classici rilevatori di patch e restauratori moderni basati su deep learning per foto e film. Il loro rilevatore più che raddoppia la misura di sovrapposizione (media dell’intersezione su unione) rispetto a queste baseline, il che significa che trova i pixel danneggiati con molta maggiore accuratezza. Per la qualità della ricostruzione, misurata tramite rapporto segnale/rumore di picco e similarità strutturale, il loro metodo supera nuovamente gli altri e mostra guadagni particolarmente grandi quando utilizza le proprie maschere. Su pellicole d’archivio reali, i confronti visivi rivelano che i metodi concorrenti o tralasciamo parti del danno, o iper-definiscono dettagli in texture innaturali, o falliscono completamente su aree ampie mancanti, mentre il nuovo sistema può rimuovere completamente lunghi graffi e grandi macchie con riempimenti uniformi e coerenti — il tutto processando sequenze ad alta definizione in frazioni di secondo per fotogramma.
Cosa significa per il nostro passato in movimento
In termini concreti, lo studio dimostra che modellare accuratamente come il danno si comporta nel tempo rende possibile restaurare automaticamente vecchi film che altrimenti resterebbero segnati o inutilizzabili. Individuando prima dove la pellicola è spezzata e poi usando fotogrammi vicini per ricostruire solo quelle regioni, il metodo offre risultati più puliti rispetto agli approcci tutto-in-uno e lo fa con meno calcolo. Sebbene la rilevazione perfetta di ogni graffio sia ancora fuori portata, questo quadro rappresenta un passo significativo verso un restauro digitale su larga scala, accessibile e conveniente di film storici, cinegiornali e video domestici, aiutando a preservare ricordi visivi per le generazioni future.
Citazione: Liu, Q., Liu, Y., Wang, L. et al. Restoration of archival film with large areas of structural damage. npj Herit. Sci. 14, 272 (2026). https://doi.org/10.1038/s40494-025-02235-3
Parole chiave: restauro di pellicole d'archivio, riparazione di graffi e macchie, inpainting video, deep learning per il patrimonio, conservazione digitale