Clear Sky Science · de
Restaurierung von Archivfilm mit großflächigen strukturellen Schäden
Warum es weiterhin wichtig ist, alte Filme zu retten
Viele der Filme und Wochenschauen, die das vergangene Jahrhundert festhielten, existieren heute nur noch auf zerbrechlichen Filmrollen. Zeit, Staub, wiederholte Projektion und schlechte Lagerung haben Kratzer geritzt und Löcher in diese Bilder gefressen, wodurch Gesichter, Objekte und sogar ganze Szenenabschnitte ausgelöscht werden. Solche Schäden manuell Bild für Bild zu beheben, ist quälend langsam und teuer. Dieser Artikel stellt eine neue Methode der künstlichen Intelligenz vor, die automatisch große, unregelmäßige Schäden in Archivfilm erkennen und reparieren kann und damit schnellere und treuere Rettung bewegter Bildgeschichte verspricht.
Was Filmschäden so kompliziert macht
Nicht alle Mängel in altem Film sind gleich. Manche Probleme – etwa körniges Rauschen, allgemeine Unschärfe oder verblasste Farben – betreffen das ganze Bild und lassen sich mit breit angelegten Bereinigungswerkzeugen behandeln. Die verheerendsten Probleme sind jedoch strukturelle Schäden wie lange vertikale Kratzer oder fleckige Schwarzweißflächen. Diese zerstören Bildinhalte, anstatt sie nur zu degradieren. Traditionelle digitale Methoden verlassen sich entweder auf handgefertigte Regeln oder behandeln jedes Frame unabhängig, wodurch bewegte Objekte fälschlich als Schaden erkannt werden oder große Lücken nur teilweise repariert bleiben. Vollständig end-to-end „Black-Box“-Systeme, die versuchen, alles in einem Schritt zu säubern und zu füllen, können hingegen beschädigte Regionen übersehen oder scharfe, aber unrealistische Details erfinden.
Durch die Zeit blicken, um Defekte zu erkennen
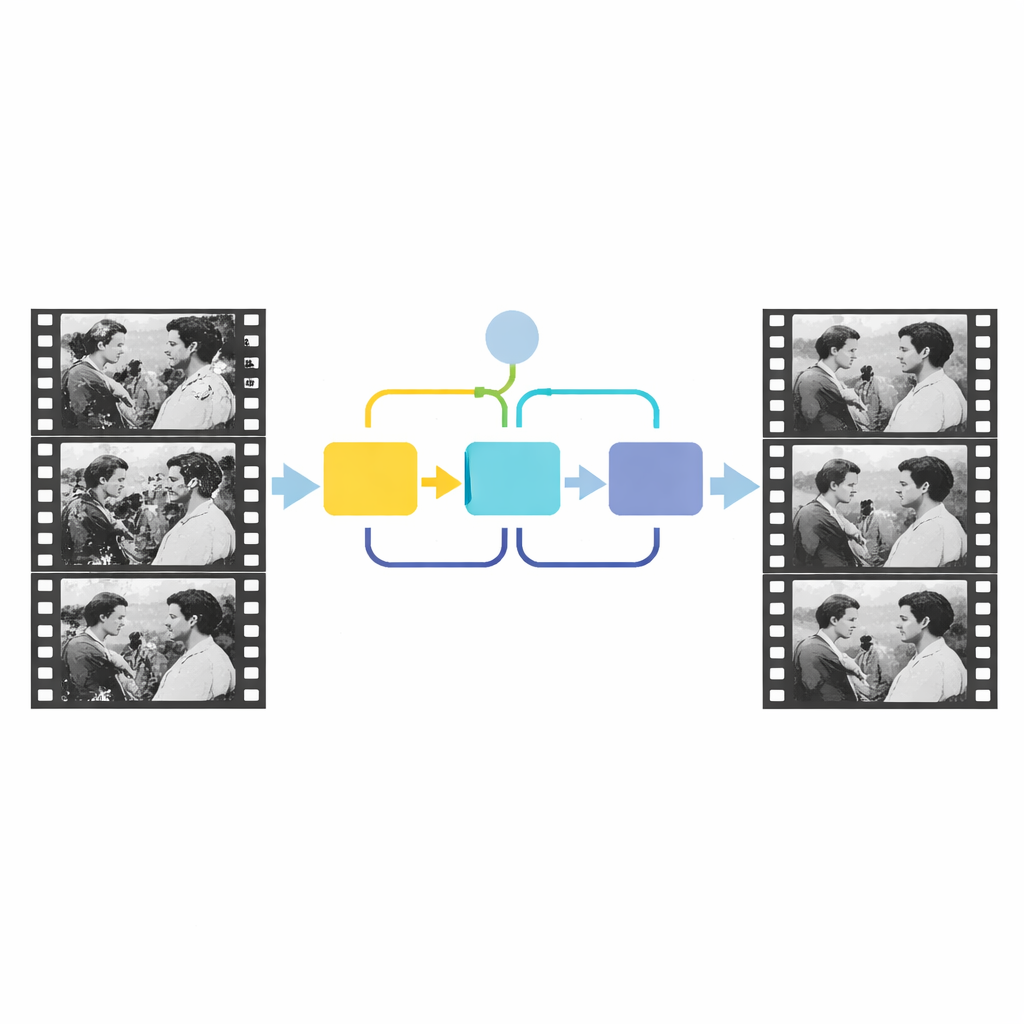
Die zentrale Erkenntnis der neuen Arbeit ist, Zeit statt nur Raum zu nutzen. Szeneninhalte verändern sich über aufeinanderfolgende Frames hinweg glatt, während Kratzer und Flecken an zufälligen Stellen auftreten und nicht der Aktion folgen. Die Autoren modellieren diesen Unterschied, indem sie drei benachbarte Frames in ein Erkennungsnetz einspeisen, das nachahmt, wie ein menschlicher Betrachter beim Vor- und Zurückblättern Anomalien entdeckt. Zuerst vergleicht ein Channel-Attention-Modul den Gesamtinhalt der drei Frames und hebt Bereiche hervor, deren zeitliches Verhalten nicht zum Rest der Szene passt. Diese Stufe liefert eine grobe Vorstellung davon, wo Schäden liegen könnten. Ein zweites Modul, genannt Source-Reference-Attention-Modul, zoomt dann auf lokale Details, nutzt Informationen aus einem relativ sauberen Nachbarframe, um Kanten und Form der beschädigten Fläche zu verfeinern. Zusammen ergeben diese Schritte eine präzise Maske, die die strukturellen Defekte umreißt.
Das System mit wenigen realen Beispielen lehren
Da wirklich beschädigtes Archivmaterial mit perfekten Ground-Truth-Labels selten und teuer zu annotieren ist, verwendet das Team eine clevere Trainingsstrategie. Zunächst erzeugen sie einen großen synthetischen Datensatz, indem sie unregelmäßige Masken – stellvertretend für Kratzer und Flecken – über reale Filmframes legen. Dadurch lernt der Detektor die grundlegende Idee von spärlichen, zeitlich unkorrelierten Schäden. In einer zweiten Phase wird das Modell mit einer kleinen Menge realer beschädigter Sequenzen feinjustiert, deren Labels nicht perfekt genau, aber dennoch informativ sind. Durch die Kombination idealer synthetischer Supervision mit unvollkommenem Real-World-Guidance lernt das System, Wissen aus sauberen Simulationen auf unordentliches historisches Material zu übertragen, während die Fusion von Merkmalen auf mehreren Skalen ihm hilft, sowohl mit kleinen Sprenkeln als auch mit weitläufig fehlenden Bereichen zurechtzukommen.
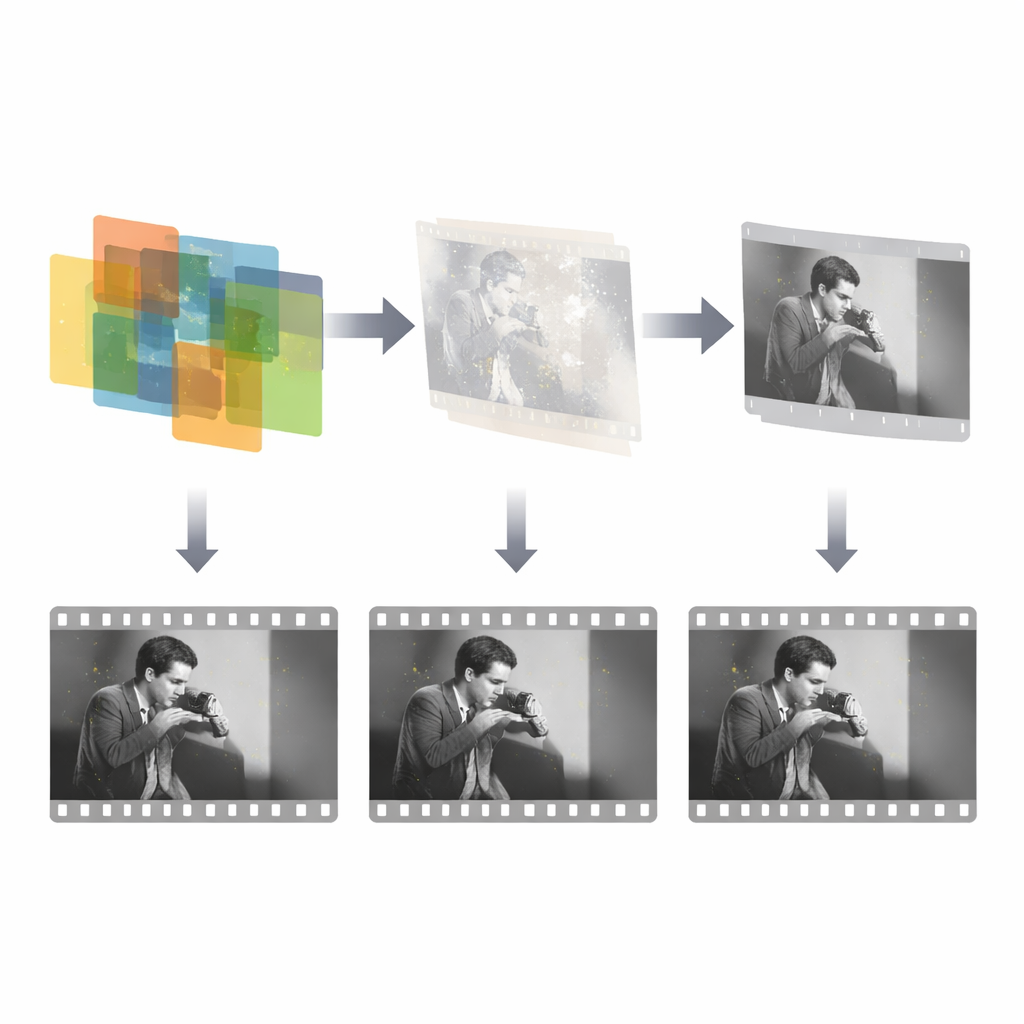
Wie beschädigte Bilder wieder aufgefüllt werden
Sobald die Schadensmaske bekannt ist, konzentriert sich ein separates Reparaturnetz ausschließlich auf die Rekonstruktion des fehlenden Inhalts. Dieses Netz erhält drei Eingaben: das beschädigte Frame, die erkannte Maske und einen benachbarten Referenzframe, der die intakte Szene noch enthält. Anschließend nutzt es ein generatives adversariales Framework, um plausible Ersatzinhalte innerhalb der maskierten Löcher zu synthetisieren, geleitet von mehreren Verlusttermen, die Genauigkeit, visuelle Glaubwürdigkeit und stilistische Glätte fördern. Wichtig ist, dass das System ausnutzt, dass Schäden nur einen kleinen Bruchteil jedes Frames einnehmen und zeitlich unabhängig sind, sodass es seine Anstrengung auf diese spärlichen Regionen konzentrieren kann, statt das gesamte Bild neu zu erlernen. Das Design ist bewusst einfach und effizient: nur drei Frames zur Detektion und ein einzelner Referenzframe zur Reparatur, was an die Vorgehensweise eines menschlichen Restaurators erinnert, der beim Ausbessern eines Defekts typischerweise nur wenige Nachbarn prüft.
Wie gut es in der Praxis funktioniert
Um ihren Ansatz zu testen, fügen die Autoren simulierte Kratzer und Flecken zu sauberen Archivclips aus einem öffentlichen Datensatz hinzu und vergleichen ihr System mit mehreren starken Baselines, darunter klassische Patch-Detektoren und moderne Deep-Learning-Restauratoren für Fotos und Filme. Ihr Detektor verdoppelt mehr als die Überlappungsmetrik (mean intersection over union) im Vergleich zu diesen Baselines, was bedeutet, dass er beschädigte Pixel viel genauer findet. Für die Rekonstruktionsqualität, gemessen an Peak Signal-to-Noise Ratio und struktureller Ähnlichkeit, übertrifft ihre Methode erneut klar die anderen und zeigt besonders große Zugewinne, wenn ihre eigenen Masken verwendet werden. Bei realem Archivmaterial zeigen visuelle Vergleiche, dass konkurrierende Methoden entweder Teile des Schadens übersehen, Details zu stark schärfen und in unnatürliche Texturen verwandeln oder bei großen fehlenden Bereichen komplett versagen, während das neue System lange Kratzer und große Flecken vollständig mit glatten, konsistenten Füllungen entfernen kann — und das bei der Verarbeitung hochauflösender Sequenzen in Bruchteilen einer Sekunde pro Frame.
Was das für unsere bewegte Bildvergangenheit bedeutet
Anschaulich zeigt die Studie, dass ein sorgfältiges Modellieren des zeitlichen Verhaltens von Schäden die automatische Restaurierung alter Filme möglich macht, die sonst vernarbt oder unbrauchbar blieben. Indem zunächst genau lokalisiert wird, wo der Film gebrochen ist, und dann nahegelegene Frames genutzt werden, um genau diese Regionen wiederaufzubauen, liefert die Methode sauberere Ergebnisse als All-in-one-Ansätze und das bei geringerem Rechenaufwand. Obwohl die perfekte Detektion jedes Kratzers weiterhin außer Reichweite ist, markiert dieses Rahmenwerk einen bedeutenden Schritt hin zu erschwinglicher, großangelegter digitaler Restaurierung historischer Filme, Wochenschauen und Heimvideos und hilft, visuelle Erinnerungen für künftige Generationen zu bewahren.
Zitation: Liu, Q., Liu, Y., Wang, L. et al. Restoration of archival film with large areas of structural damage. npj Herit. Sci. 14, 272 (2026). https://doi.org/10.1038/s40494-025-02235-3
Schlüsselwörter: Restaurierung von Archivfilm, Kratzer- und Fleckenreparatur, Video-Inpainting, Tiefenlernen für Kulturerbe, Digitale Bewahrung