Clear Sky Science · es
Restauración de filmaciones de archivo con grandes zonas de daño estructural
Por qué sigue importando salvar las películas antiguas
Muchas de las películas y noticiarios que documentaron el siglo pasado sobreviven hoy únicamente en frágiles carretes de película. El tiempo, el polvo, la proyección repetida y el almacenamiento deficiente han marcado arañazos y abierto agujeros en esas imágenes, borrando rostros, objetos e incluso partes enteras de las escenas. Reparar manualmente ese daño fotograma a fotograma es extremadamente lento y costoso. Este artículo presenta un nuevo método basado en inteligencia artificial que puede localizar y reparar automáticamente defectos grandes e irregulares en filmaciones de archivo, prometiendo una recuperación más rápida y fiel de la historia en movimiento.
Qué hace que el daño en la película sea tan complicado
No todos los defectos en una filmación antigua son iguales. Algunos problemas —como el ruido granulado, el desenfoque general o los colores desvaídos— afectan toda la imagen y pueden tratarse con herramientas de limpieza amplias. Sin embargo, los problemas más devastadores son los daños estructurales, como largos arañazos verticales o parches manchados en blanco y negro. Estos destruyen contenido de la imagen en lugar de simplemente degradarlo. Los métodos digitales tradicionales dependen de reglas hechas a mano o tratan cada fotograma de forma independiente, con frecuencia confundiendo objetos en movimiento con daño o dejando grandes huecos solo parcialmente reparados. Mientras tanto, los sistemas de caja negra que intentan limpiar y rellenar todo en un solo paso pueden pasar por alto regiones dañadas o inventar detalles nítidos pero poco realistas.
Mirar a través del tiempo para detectar defectos
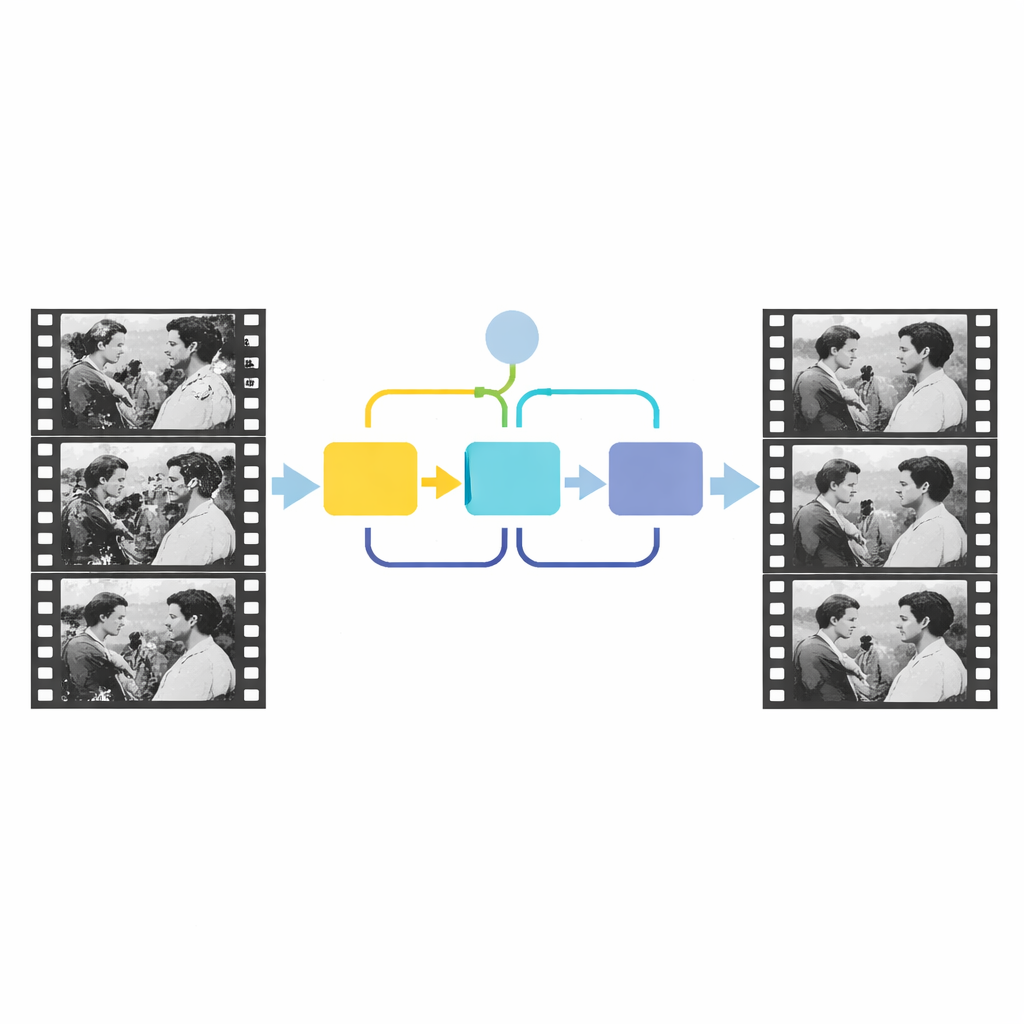
La idea clave del nuevo trabajo es usar el tiempo, no solo el espacio. El contenido real de la escena cambia suavemente de un fotograma a otro, mientras que los arañazos y parches aparecen en ubicaciones aleatorias y no siguen la acción. Los autores modelan esta diferencia alimentando tres fotogramas contiguos a una red de detección que imita cómo un observador humano hojea hacia delante y atrás para localizar anomalías. Primero, un módulo de atención por canales compara el contenido general de los tres fotogramas y resalta regiones cuyo comportamiento temporal no coincide con el resto de la escena. Esta etapa ofrece una idea aproximada de dónde podría estar el daño. Luego, un segundo módulo, llamado módulo de atención fuente-referencia, se concentra en los detalles locales, utilizando información de un fotograma vecino relativamente limpio para afinar los bordes y la forma del área dañada. Juntos, estos pasos producen una máscara precisa que delimita los defectos estructurales.
Enseñar al sistema con pocos ejemplos reales
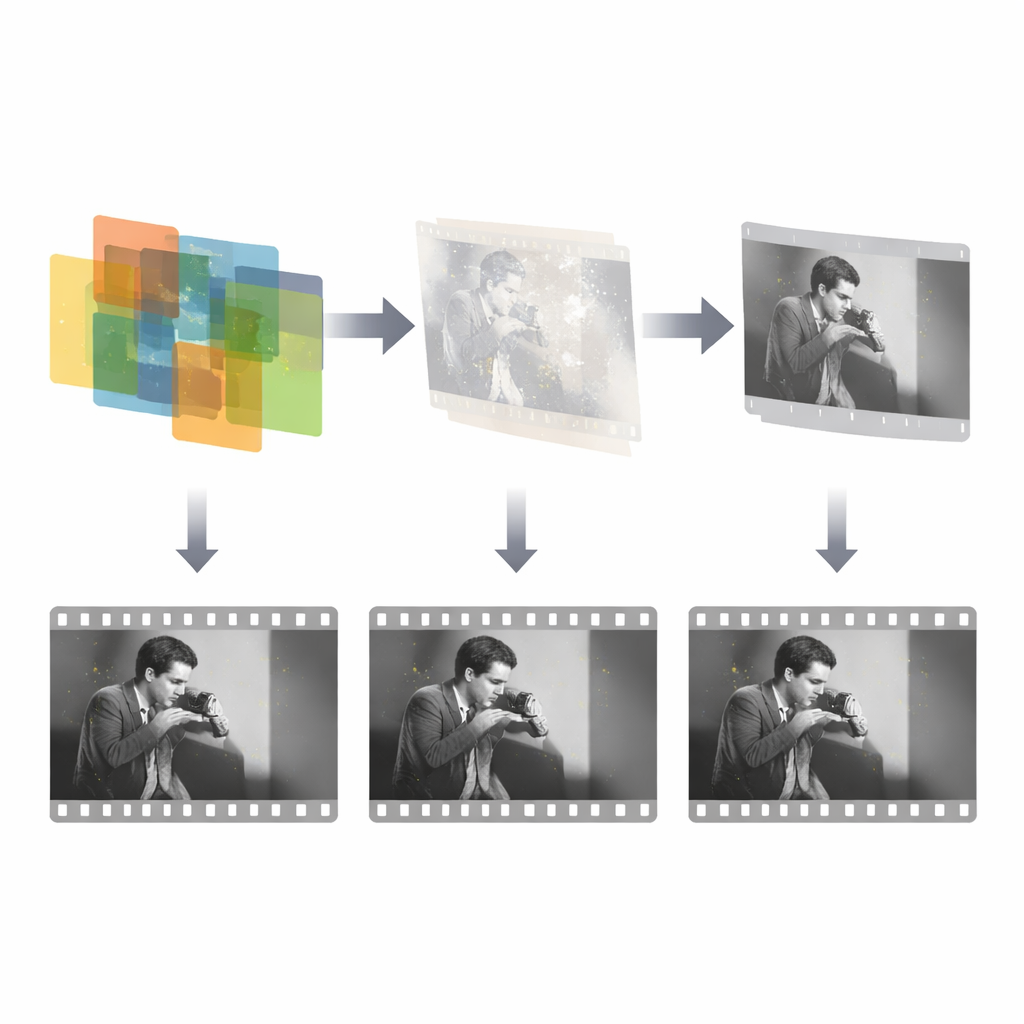
Debido a que las filmaciones de archivo verdaderamente dañadas con etiquetas de referencia perfectas son escasas y costosas de anotar, el equipo emplea una estrategia de entrenamiento ingeniosa. Primero crean un gran conjunto de datos sintéticos superponiendo máscaras irregulares —que representan arañazos y parches— sobre fotogramas reales. Esto permite que el detector aprenda la idea básica de daños dispersos y no correlacionados en el tiempo. En una segunda fase, el modelo se afina con un pequeño conjunto de secuencias reales dañadas cuyas etiquetas no son perfectamente precisas pero sí informativas. Al combinar una supervisión sintética ideal con guía del mundo real imperfecta, el sistema aprende a transferir lo aprendido en simulaciones limpias a material histórico desordenado, mientras que la fusión de características multiescala le ayuda a manejar desde pequeñas motas hasta amplias regiones faltantes.
Cómo se rellenan nuevamente las imágenes rotas
Una vez conocida la máscara de daño, una red de reparación separada se centra únicamente en reconstruir el contenido faltante. Esta red toma tres entradas: el fotograma dañado, la máscara detectada y un fotograma de referencia vecino que todavía contiene la escena intacta. Luego emplea un marco generativo adversarial para sintetizar reemplazos plausibles dentro de los huecos enmascarados, guiada por múltiples términos de pérdida que fomentan la precisión, el realismo visual y la coherencia de estilo. Es importante destacar que el sistema explota el hecho de que el daño ocupa solo una pequeña fracción de cada fotograma y es independiente en el tiempo, por lo que puede concentrar su esfuerzo en esas regiones dispersas en lugar de intentar reaprender toda la imagen. El diseño es intencionalmente simple y eficiente: solo tres fotogramas para la detección y un único fotograma de referencia para la reparación, siguiendo el modo en que un restaurador humano suele consultar solo unos pocos vecinos al parchear un defecto.
Qué tan bien funciona en la práctica
Para evaluar su enfoque, los autores añaden arañazos y manchas simuladas a clips de archivo limpios de un conjunto de datos público y comparan su sistema con varias líneas base fuertes, incluyendo detectores de parches clásicos y restauradores modernos de aprendizaje profundo para fotos y películas. Su detector más que duplica la medida de solapamiento (mean intersection over union) respecto a estas líneas base, lo que significa que encuentra píxeles dañados con mucha más precisión. Para la calidad de reconstrucción, medida por la relación señal-ruido pico y la similitud estructural, su método vuelve a superar claramente a los demás y muestra ganancias especialmente grandes cuando usa sus propias máscaras. En metraje de archivo real, las comparaciones visuales revelan que los métodos competidores o bien dejan partes del daño sin cubrir, o sobreenfocan detalles creando texturas no naturales, o fallan por completo en grandes áreas faltantes, mientras que el nuevo sistema puede eliminar por completo largos arañazos y grandes manchas con rellenos suaves y coherentes —todo ello procesando secuencias en alta definición en fracciones de segundo por fotograma.
Qué significa esto para nuestro pasado en movimiento
En términos cotidianos, el estudio demuestra que modelar cuidadosamente cómo se comporta el daño a través del tiempo hace posible restaurar automáticamente películas antiguas que de otro modo quedarían marcadas o inservibles. Al localizar primero dónde está rota la película y luego usar fotogramas cercanos para reconstruir solo esas regiones, el método ofrece resultados más limpios que los enfoques todo en uno y lo hace con menos cálculo. Aunque la detección perfecta de cada arañazo aún está fuera de alcance, este marco supone un paso significativo hacia la restauración digital asequible y a gran escala de películas históricas, noticiarios y vídeos domésticos, ayudando a preservar recuerdos visuales para generaciones futuras.
Cita: Liu, Q., Liu, Y., Wang, L. et al. Restoration of archival film with large areas of structural damage. npj Herit. Sci. 14, 272 (2026). https://doi.org/10.1038/s40494-025-02235-3
Palabras clave: restauración de filmaciones de archivo, reparación de arañazos y manchas, inpaint de vídeo, aprendizaje profundo para el patrimonio, preservación digital