Clear Sky Science · en
Restoration of archival film with large areas of structural damage
Why Saving Old Films Still Matters
Many of the movies and newsreels that captured the last century now survive only on fragile film reels. Time, dust, repeated projection, and poor storage have carved scratches and eaten holes into these images, erasing faces, objects, and even entire parts of scenes. Manually fixing such damage frame by frame is painfully slow and expensive. This article introduces a new artificial-intelligence method that can automatically find and repair large, irregular defects in archival film, promising faster and more faithful rescue of moving-image history.
What Makes Film Damage So Tricky
Not all flaws in old film are alike. Some problems—such as grainy noise, general blur, or faded color—affect the whole picture and can be treated with broad clean-up tools. The most devastating problems, however, are structural damages like long vertical scratches or blotchy black and white patches. These destroy image content rather than simply degrading it. Traditional digital methods either rely on hand-crafted rules or treat every frame independently, often confusing moving objects with damage or leaving large holes only partly repaired. Meanwhile, full end-to-end "black box" systems that try to clean and fill everything in one step can miss damaged regions or invent sharp but unrealistic details.
Looking Through Time to Spot Defects
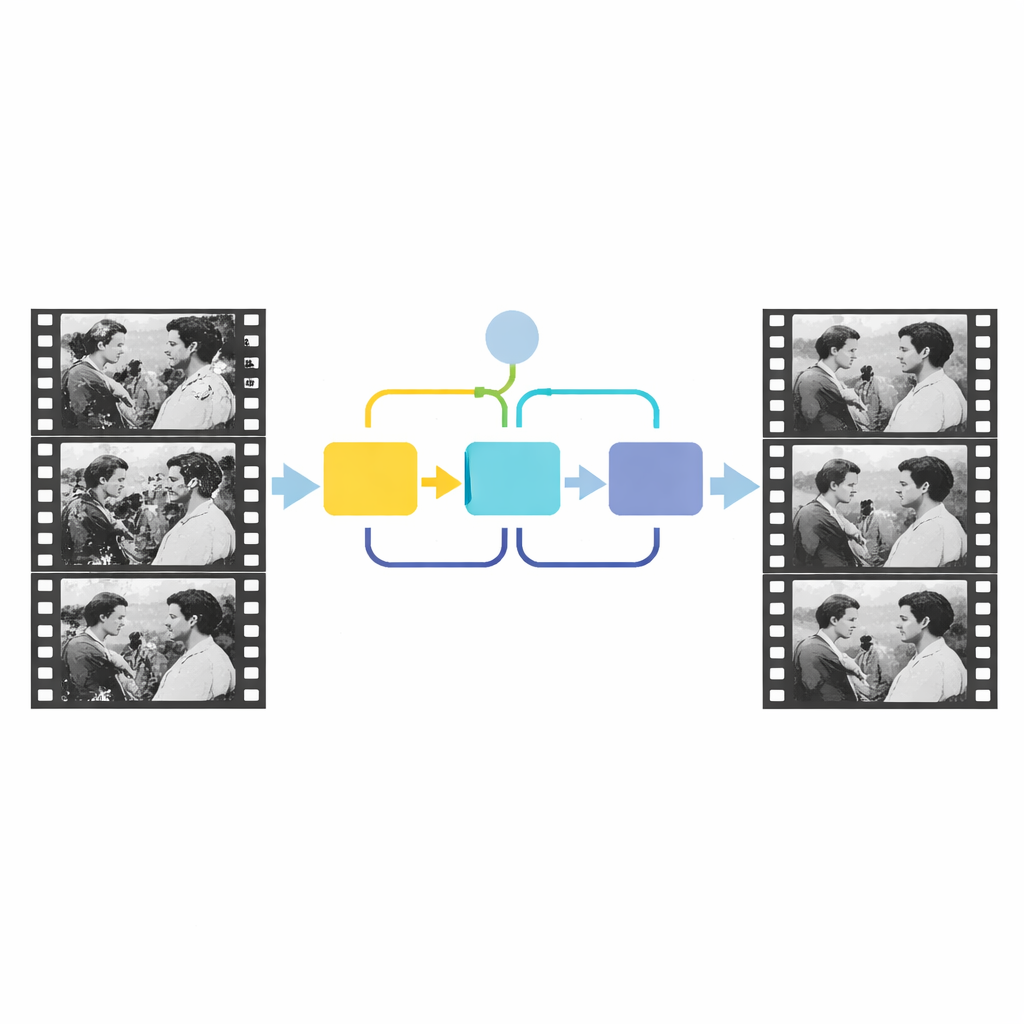
The key insight of the new work is to use time, not just space. Real scene content changes smoothly from frame to frame, while scratches and patches appear at random locations and do not follow the action. The authors model this difference by feeding three neighboring frames into a detection network that mimics how a human observer flips back and forth to spot anomalies. First, a channel attention module compares the overall content of the three frames and highlights regions whose behavior over time does not match the rest of the scene. This stage gives a coarse idea of where damage might be. Then a second module, called a source-reference attention module, zooms in on local details, using information from a relatively clean neighboring frame to refine the edges and shape of the damaged area. Together, these steps yield a precise mask that outlines the structural defects.
Teaching the System With Limited Real Examples
Because truly damaged archival footage with perfect ground-truth labels is scarce and costly to annotate, the team uses a clever training strategy. They first create a large synthetic dataset by overlaying irregular masks—standing in for scratches and patches—onto real film frames. This allows the detector to learn the basic idea of sparse, time-uncorrelated damage. In a second stage, the model is fine-tuned with a small set of real damaged sequences whose labels are not perfectly accurate but still informative. By combining ideal synthetic supervision with imperfect real-world guidance, the system learns to transfer what it knows from clean simulations to messy historical material, while multi-scale feature fusion helps it cope with both small specks and wide missing regions.
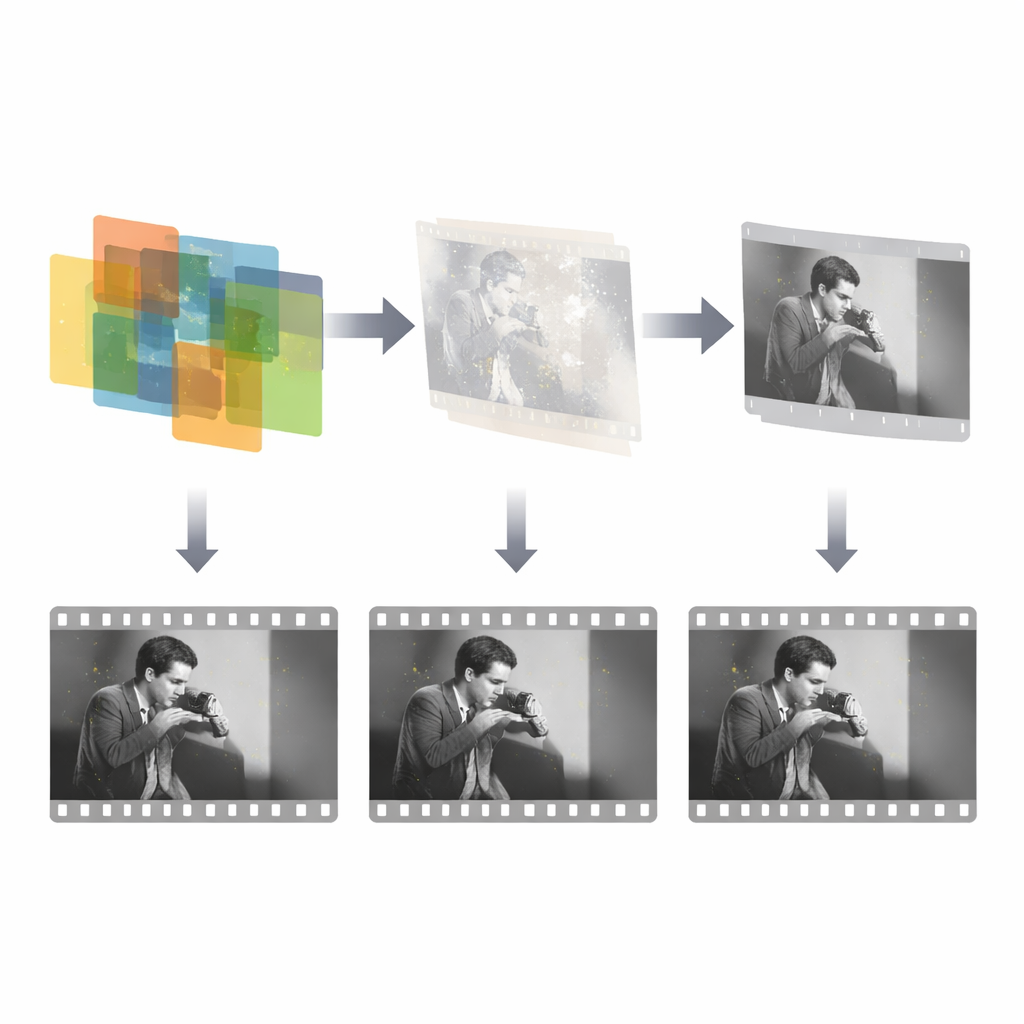
How Broken Images Are Filled Back In
Once the damage mask is known, a separate repair network focuses only on reconstructing the missing content. This network takes three inputs: the damaged frame, the detected mask, and one neighboring reference frame that still contains the intact scene. It then uses a generative adversarial framework to synthesize plausible replacements inside the masked holes, guided by multiple loss terms that encourage accuracy, visual realism, and smooth style. Importantly, the system exploits the fact that damage occupies only a small fraction of each frame and is independent over time, so it can concentrate its effort on those sparse regions rather than trying to relearn the entire image. The design is intentionally simple and efficient: just three frames for detection and a single reference frame for repair, echoing how a human restorer typically checks only a few neighbors when patching a defect.
How Well It Works in Practice
To test their approach, the authors add simulated scratches and blotches to clean archival clips from a public dataset and compare their system with several strong baselines, including classic patch detectors and modern deep-learning restorers for photos and films. Their detector more than doubles the overlap measure (mean intersection over union) relative to these baselines, meaning it finds damaged pixels much more accurately. For reconstruction quality, measured by peak signal-to-noise ratio and structural similarity, their method again clearly outperforms others and shows especially large gains when using its own masks. On real-world archival footage, visual comparisons reveal that competing methods either miss parts of the damage, over-sharpen details into unnatural textures, or fail completely on large missing areas, while the new system can fully remove long scratches and big blotches with smooth, consistent fills—all while processing high-definition sequences in fractions of a second per frame.
What This Means for Our Moving-Image Past
In everyday terms, the study demonstrates that carefully modeling how damage behaves across time makes it possible to automatically restore old films that would otherwise remain scarred or unusable. By first pinpointing where the film is broken and then using nearby frames to rebuild just those regions, the method delivers cleaner results than all-in-one approaches and does so with less computation. Although perfect detection of every scratch is still out of reach, this framework marks a significant step toward affordable, large-scale digital restoration of historical movies, newsreels, and home videos, helping preserve visual memories for future generations.
Citation: Liu, Q., Liu, Y., Wang, L. et al. Restoration of archival film with large areas of structural damage. npj Herit. Sci. 14, 272 (2026). https://doi.org/10.1038/s40494-025-02235-3
Keywords: archival film restoration, scratch and blotch repair, video inpainting, deep learning for heritage, digital preservation