Clear Sky Science · fr
Reconstruction par super-résolution basée sur les réseaux antagonistes génératifs pour les images de télédétection
Des vues plus nettes de notre planète en mutation
Chaque jour, des satellites capturent d’immenses mosaïques de la Terre qui guident l’aménagement urbain, la réponse aux catastrophes, l’agriculture et la protection de l’environnement. Pourtant, nombre de ces images sont moins nettes qu’on le souhaiterait : les lignes de routes fines s’estompent, les contours des bâtiments deviennent flous et les petits détails disparaissent. Cette étude présente une nouvelle méthode de vision par ordinateur, appelée SDGAN, qui transforme des images satellites grossières en vues plus claires et plus détaillées tout en sollicitant moins de puissance de calcul — rendant des cartes nettes et opportunes plus pratiques pour une utilisation réelle.
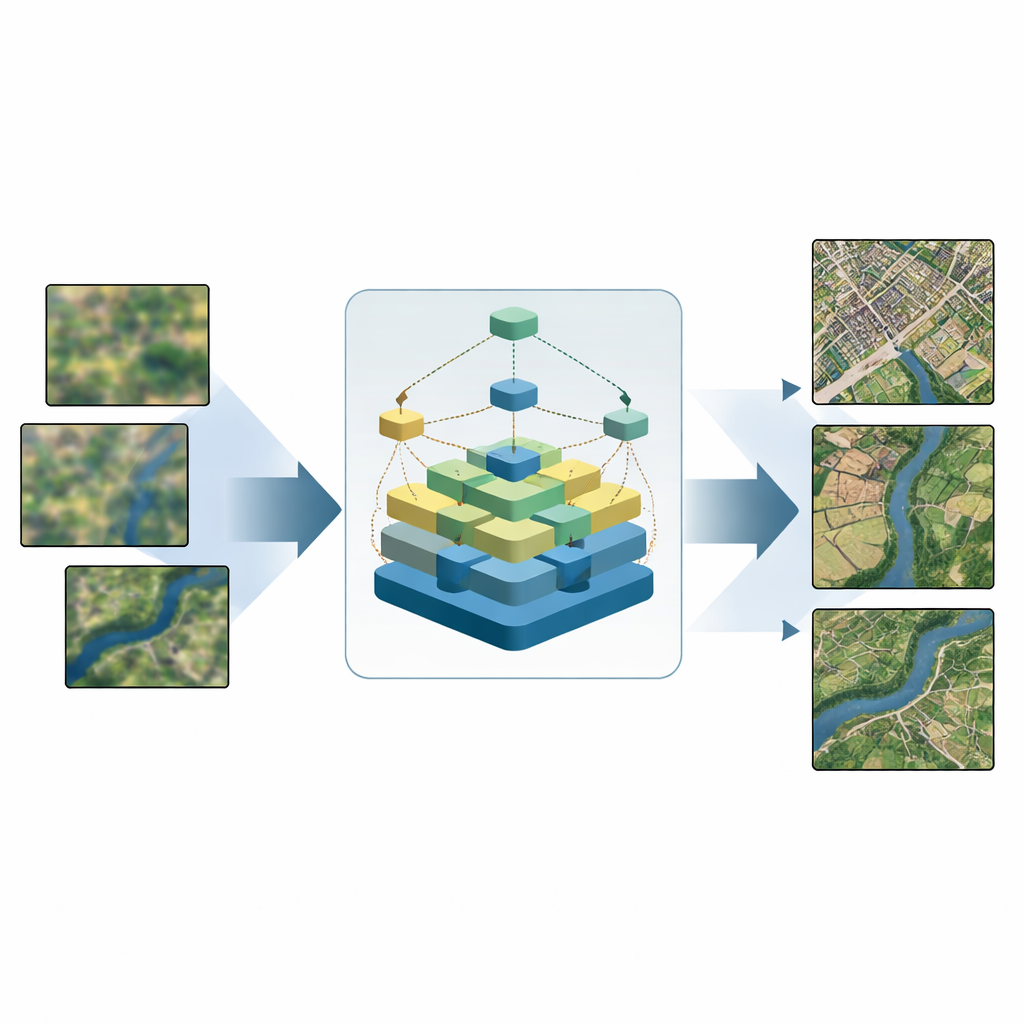
Pourquoi les images satellites deviennent floues
Les satellites modernes orbitent très haut et doivent observer à travers une atmosphère en mouvement, tout en respectant des contraintes strictes de taille, d’énergie et de coût. En conséquence, beaucoup d’images brutes de télédétection présentent une résolution limitée : les petites maisons se fondent en plaques de couleur, les rivières étroites perdent leur forme et les textures des terres agricoles deviennent indistinctes. Les astuces classiques d’amélioration — comme le zoom simple et l’interpolation — permettent d’agrandir les images mais ne peuvent pas inventer des détails convaincants. Des méthodes plus avancées basées sur l’apprentissage aident, mais créent souvent des artefacts étranges, échouent sur des scènes avec des types de surfaces mélangés ou exigent trop de ressources de calcul pour des appareils tels que les drones et les ordinateurs portables de terrain.
Une approche intelligente pour récupérer les détails perdus
Les auteurs s’attaquent à ce problème avec SDGAN, un cadre de « super-résolution » qui apprend à reconstruire les structures fines à partir d’images satellites basse résolution. Au cœur se trouve un nouveau bloc de construction appelé bloc résiduel super-dense. Plutôt que de laisser l’information visuelle traverser directement une pile de couches, cette architecture dispose de nombreuses petites unités de traitement organisées en grille et reliées dans plusieurs directions — y compris en diagonale. Cette toile de connexions permet aux motifs simples des couches initiales et aux motifs plus riches des couches profondes d’interagir plus efficacement. En pratique, cela aide le réseau à restituer des bords et des textures nets, tels que des routes qui se croisent ou des limites de champs irrégulières, tout en maintenant le modèle relativement compact et efficace.
Deux critiques pour garder le réseau honnête
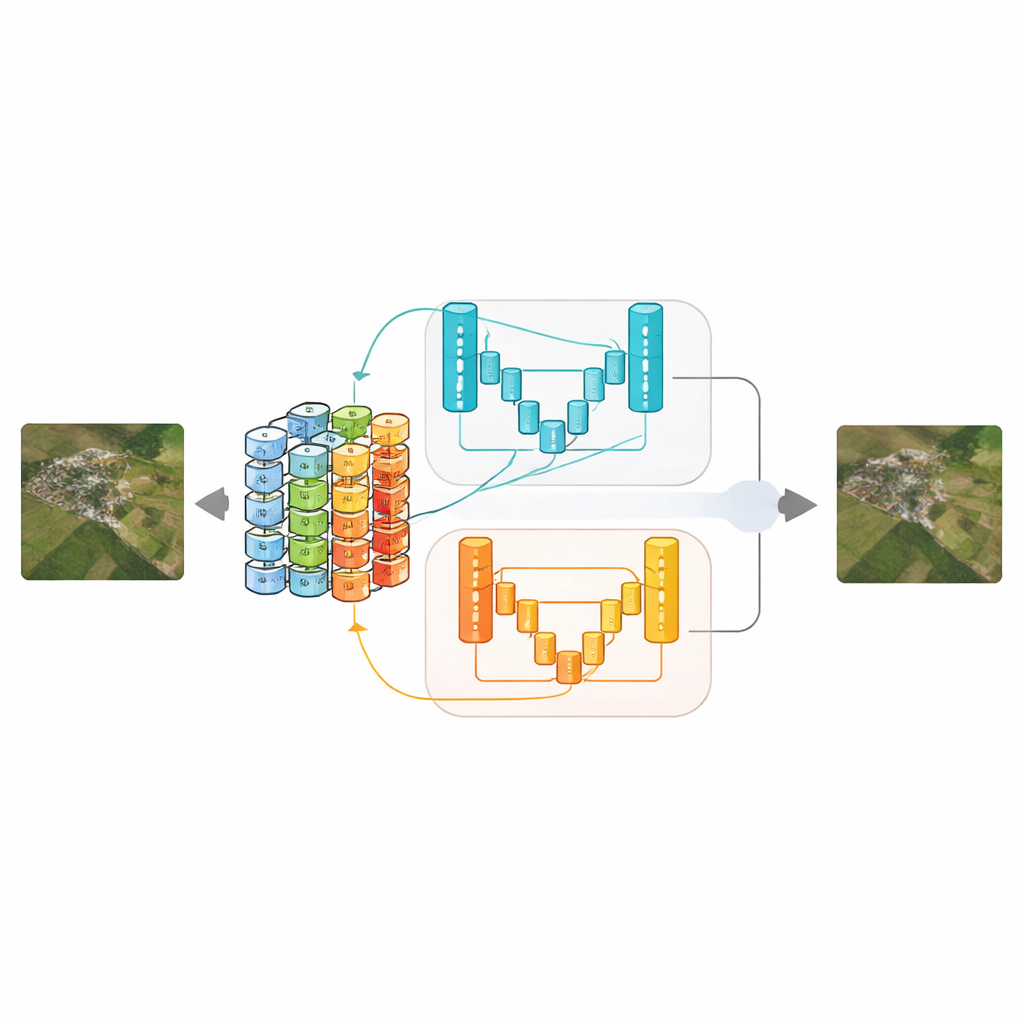
Pour juger si les images affinées semblent réalistes, SDGAN utilise non pas un mais deux réseaux « discriminateurs » basés sur un design en U épuré avec des mécanismes d’attention. Un discriminateur examine des images en taille réelle et se concentre sur les détails infimes, comme les bandes d’une piste d’atterrissage ou les contours des bâtiments. L’autre observe des versions sous-échantillonnées et se focalise sur l’agencement global — les systèmes fluviaux sont-ils continus, les agencements urbains et agricoles paraissent-ils cohérents d’un coup d’œil ? En entraînant le générateur contre ces deux critiques simultanément, le système apprend à produire des images à la fois localement nettes et globalement cohérentes, réduisant les problèmes courants tels que des textures artificielles ou des structures à grande échelle brisées.
Évaluation de la méthode
L’équipe a testé SDGAN sur trois ensembles de télédétection largement utilisés : UCMerced-LandUse, WHU-RS19 et AID, qui couvrent ensemble des dizaines de types de scènes allant des aéroports et des ports aux forêts et zones résidentielles. Ils ont comparé leur méthode avec des réseaux convolutionnels classiques, des approches génératives de pointe comme SRGAN et Real-ESRGAN, ainsi que des modèles spécialisés récents. Sur différents facteurs de zoom, SDGAN a généralement offert la meilleure combinaison de netteté, de similarité structurelle et de naturalité perçue, selon des scores numériques et l’inspection visuelle. Fait important, il y est parvenu tout en réduisant le temps de traitement moyen d’environ 22 % par rapport à une méthode antérieure performante, montrant que plus de clarté ne doit pas forcément s’accompagner d’un coût informatique élevé.
Des images plus nettes, de meilleures décisions
Pour les non-spécialistes, l’idée principale est que SDGAN propose un moyen de rendre l’imagerie satellite à la fois plus claire et plus fiable. En préservant soigneusement les contours, les textures et les motifs à grande échelle, il produit des images plus faciles à interpréter pour les analystes et les systèmes automatisés — qu’il s’agisse de détecter des glissements de terrain, de cartographier l’utilisation des terres ou de suivre les eaux de crue. Parce que la méthode est relativement légère, elle convient également mieux aux appareils à puissance limitée, comme les drones utilisés lors d’enquêtes d’urgence. Les auteurs suggèrent que des travaux futurs pourraient étendre SDGAN pour gérer des dégradations d’image plus sévères, des types de capteurs supplémentaires comme le radar ou les caméras thermiques, et des liens directs avec des tâches en aval, nous rapprochant de vues haute fidélité et presque en temps réel de notre planète dynamique.
Citation: Wang, L., Liu, L., Yu, Q. et al. Generative adversarial network-based super-resolution reconstruction of remote sensing images. Sci Rep 16, 11971 (2026). https://doi.org/10.1038/s41598-026-41832-5
Mots-clés: télédétection, super-résolution d'image, images satellites, apprentissage profond, réseaux antagonistes génératifs