Clear Sky Science · es
GPT-4o para la determinación automatizada de exámenes de seguimiento basada en informes radiológicos de la práctica clínica
Por qué importan escáneres de seguimiento más inteligentes
Cuando un paciente se somete a una tomografía computarizada (TC) o una resonancia magnética (RM), la historia no termina con las imágenes. Los radiólogos deben también decidir si y cuándo son necesarias exploraciones de seguimiento para monitorizar tumores, evaluar focos sospechosos o confirmar que un tratamiento está funcionando. Estas decisiones pueden marcar la diferencia entre detectar la enfermedad a tiempo y exponer a los pacientes a radiación, costes y ansiedad innecesarios. Este estudio planteó una pregunta oportuna: ¿puede un sistema moderno de inteligencia artificial, GPT-4o, ayudar a estandarizar estas decisiones de seguimiento para que los pacientes reciban una atención coherente y basada en guías?
El problema de los mensajes contradictorios
Las sociedades profesionales publican recomendaciones detalladas sobre cuándo y cómo repetir imágenes para muchos cánceres y hallazgos incidentales. Sin embargo, en la práctica cotidiana, los radiólogos a menudo discrepan sobre el seguimiento. Algunos son rápidos en solicitar nuevas exploraciones; otros son más cautelosos. Investigaciones previas han mostrado que la probabilidad de recomendar imágenes adicionales puede variar casi siete veces entre radiólogos que revisan casos similares. Muchos planes propuestos no coinciden completamente con las guías publicadas, lo que lleva a que algunos pacientes se sometan a más exploraciones de las necesarias, mientras que otros pueden perder controles oportunos. Este panorama desigual motiva herramientas que puedan orientar la práctica hacia decisiones más coherentes y basadas en la evidencia.
Cómo se diseñó el estudio
Los investigadores evaluaron GPT-4o, un modelo de lenguaje grande diseñado para comprender y generar texto, en 100 casos reales de radiología procedentes de dos hospitales alemanes. Todos los casos involucraban adultos sometidos a TC o RM por preguntas relacionadas con el cáncer en cuatro regiones clave: cabeza y cuello, hígado, pulmón y páncreas. Para cada caso, el modelo recibió el informe completo por escrito, incluida la historia clínica, los hallazgos en la exploración y la conclusión del radiólogo. A GPT-4o se le pidió una tarea: con base en esta información, proponer el método exacto de imagen de seguimiento (por ejemplo, TC o RM) y el momento de la próxima exploración. Un residente de radiología y un radiólogo experimentado con certificación respondieron la misma pregunta para cada caso.
Medir la calidad frente a las guías
Para evaluar estas recomendaciones, dos radiólogos sénior, que no sabían de quién procedían las sugerencias, compararon todas las respuestas con las principales guías internacionales de sociedades de cáncer y radiología. Valoraron cada propuesta en cuatro aspectos: si se cubrían todos los hallazgos relevantes que requerían seguimiento, si la técnica de imagen elegida era apropiada, cuán exacto era el tiempo sugerido y una puntuación global de calidad en una escala de cinco puntos. En esencia, los expertos preguntaban: ¿este plan mantiene seguro al paciente, sigue las pautas y evita exploraciones innecesarias?
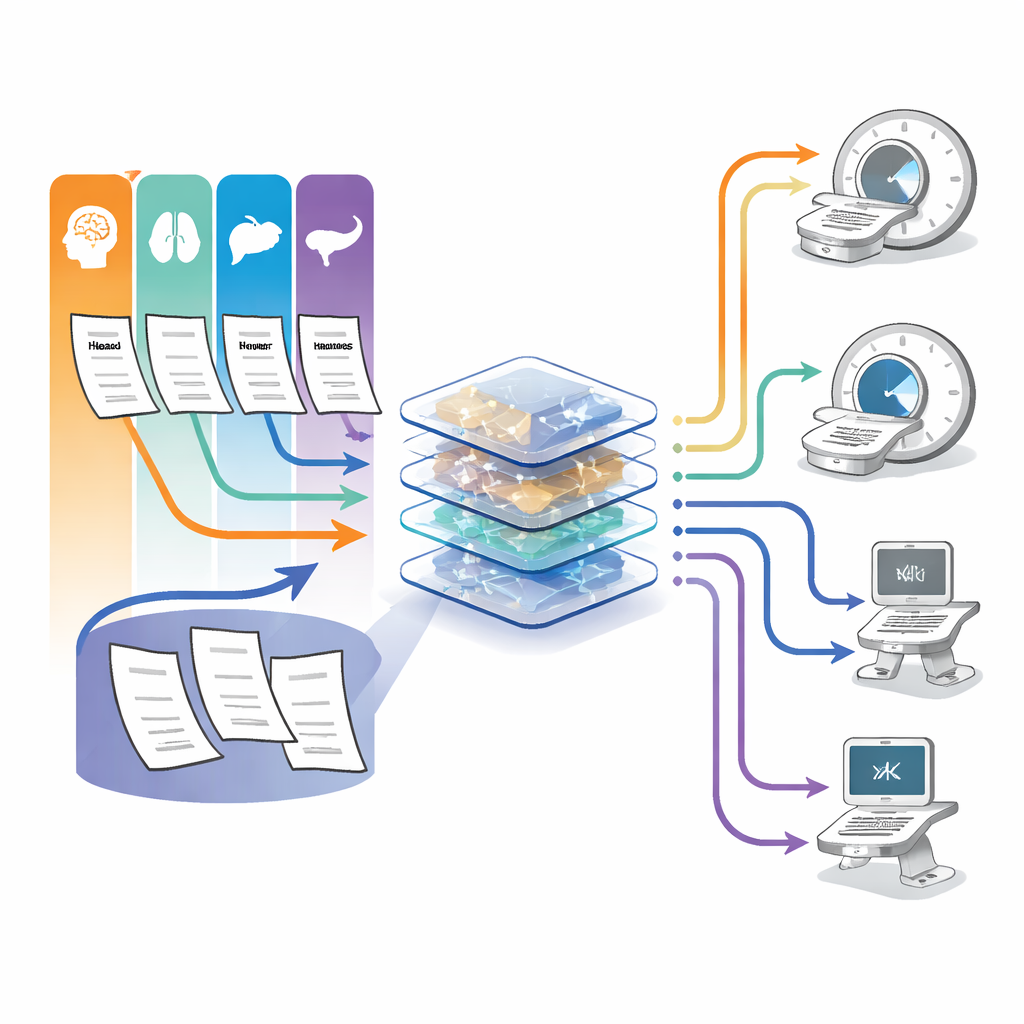
Cómo se comparó la IA con los humanos
En los 100 casos, la calidad global de seguimiento de GPT-4o igualó a la del radiólogo experimentado y superó a la del residente. La puntuación mediana global del modelo fue 4 de 5, esencialmente igual que la del experto y significativamente mejor que la del residente. GPT-4o acertó el momento total o parcialmente en el 96% de los casos, superando al residente (75%) y superando ligeramente al experto (90%). También produjo el menor número de errores de temporización potencialmente dañinos. El modelo abordó todos los hallazgos que requerían seguimiento en el 92% de los casos, similar al residente y claramente mejor que el experto en esta medida específica. Para la elección del tipo correcto de exploración, GPT-4o se desempeñó casi a la par con ambos lectores humanos. Sus puntos fuertes fueron las imágenes de pulmón, hígado y páncreas, donde las vías de guía están especialmente bien estandarizadas; el rendimiento fue algo menor, para todos los evaluadores, en la región más compleja de cabeza y cuello.
Qué podría significar esto para la atención futura
El estudio sugiere que GPT-4o puede actuar como un asistente fiable para decisiones de imagen de seguimiento, funcionando aproximadamente al nivel de un radiólogo experimentado y mejor que un residente en muchos aspectos. Utilizado como herramienta de apoyo a la decisión más que como sustituto, un sistema así podría ayudar a reducir exploraciones innecesarias, acortar retrasos en seguimientos esenciales y aliviar la carga de trabajo en departamentos de radiología saturados, todo mientras mantiene la práctica más alineada con guías establecidas. Sin embargo, los autores subrayan que los expertos humanos deben seguir a cargo: el modelo todavía puede interpretar mal informes, sus procesos internos son opacos y el estudio incluyó solo 100 casos relacionados con cáncer de dos centros. Se necesitarán ensayos prospectivos más amplios y despliegues seguros y alojados localmente antes de que tales herramientas puedan integrarse con seguridad en los flujos de trabajo clínicos diarios.
Cita: Kaya, K., Müller, L., Persigehl, T. et al. GPT-4o for Automated Determination of Follow-up Examinations Based on Radiology Reports from Clinical Routine. Sci Rep 16, 12587 (2026). https://doi.org/10.1038/s41598-026-40317-9
Palabras clave: seguimiento radiológico, modelos de lenguaje grande, soporte a la decisión médica, imágenes oncológicas, GPT-4o