Clear Sky Science · zh
用于痴呆风险预测的机器学习模型:来自悉尼记忆与衰老研究的证据
这对健康老龄化为何重要
痴呆是晚年人群最令人担忧的疾病之一,但许多人直到记忆和思维问题已经进展时才被确诊。本研究提出了一个令人期待的问题:利用临床已收集的信息——例如年龄、简单的认知测试、血糖和心脏健康指标——我们能否提前最多十年识别出更可能发展为痴呆的人?如果可行,医生就能把监测和预防资源优先投入到最需要的人群。
深入了解一项长期老龄化研究
研究者利用了悉尼记忆与衰老研究的数据,该研究追踪了逾一千名入组时年龄在70岁及以上且无痴呆的澳大利亚人。大约十年间,部分参与者随后发展为痴呆,而另一些则未发生。基线时,每位参与者完成了详尽的认知与记忆测试、情绪问卷,以及包括血液检查和心血管健康测量在内的体检。通过观察基线特征在随后发展痴呆者中的常见性,研究团队得以训练计算机模型识别高风险特征组合。
教计算机识别未来风险
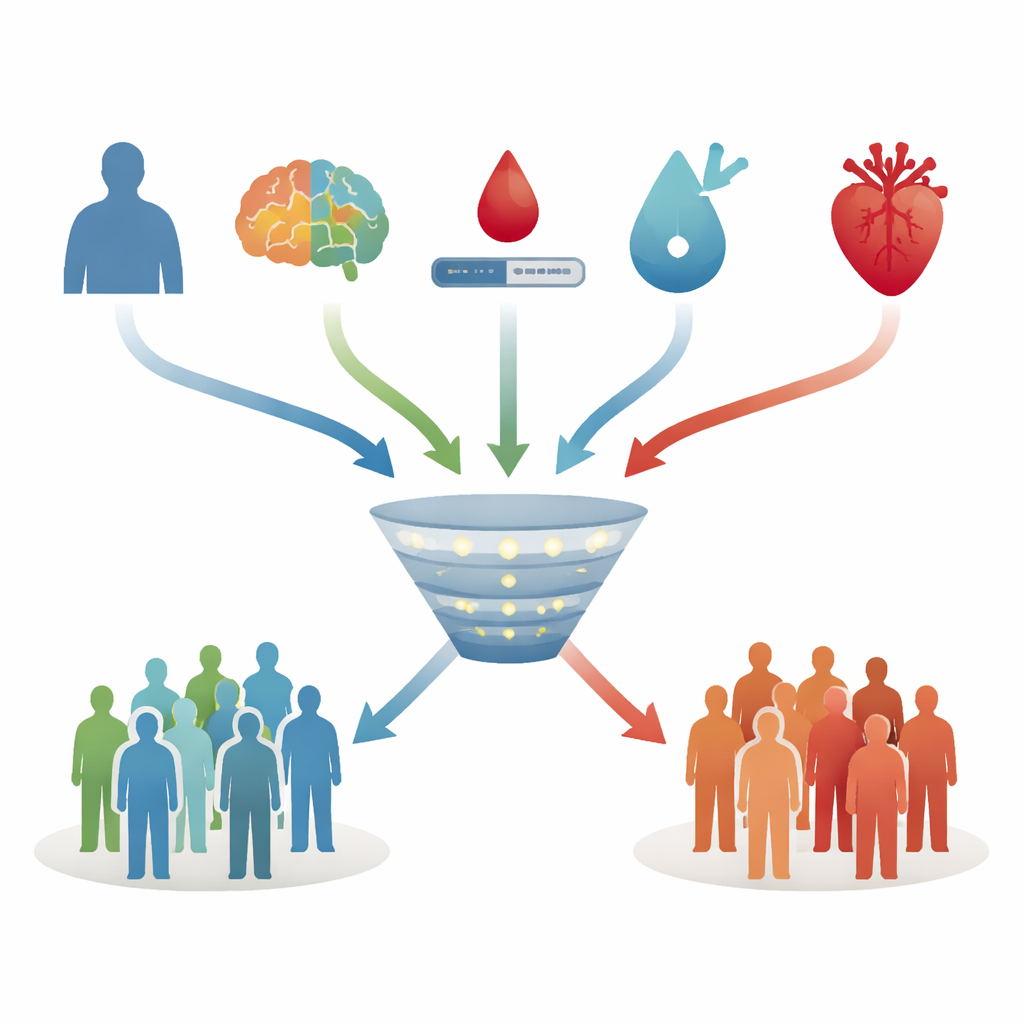
为构建这些预测工具,作者比较了几种常见的机器学习方法。所有模型试图回答相同的问题:在已知某人基线信息的情况下,假设该人在十年后仍然在世并接受评估,他们发生痴呆的可能性有多大?算法在约70%的参与者数据上训练,然后在剩余约30%作为未见过的测试集上验证。输入变量包括年龄、受教育年限、情绪症状、详细的认知评分、腰臀比、一个标准的心脏病风险评分,以及血液指标如胆固醇、甘油三酯、尿酸、肾功能、炎症标志物和空腹葡萄糖。一个称为APOE ε4的遗传风险标志随后作为可选项被检验。
四项简单指标承担大部分信息
在各种方法中,一种简化的方法——LASSO回归表现最佳。尽管初始候选变量众多,该模型最终只保留了四个预测因子:年龄、整体认知表现、空腹血糖和一个综合的心血管风险评分。年龄较大、血糖较高和心血管状况较差都会推高预测风险,而认知表现更好则把风险向下拉。在留出的测试组中,这个四因素模型能够在大约四分之三的时间里,把未来发生痴呆的个体正确排在未发生者之上,这一水平被认为对临床风险工具是可接受的。它在捕捉真正的未来病例与避免过多误报之间也提供了良好的平衡。
哪些因素提升有限以及工具的使用方式
令人意外的是,在已纳入年龄、认知表现、血糖和心脏风险的情况下,将APOE ε4遗传状态加入到最佳模型并未提升其准确性,反而在某些度量上略有下降。这表明,至少在这组老年人中,常规临床信息比遗传检测或实验性血液标志物更能说明主要风险。作者提供了一个可以在电子表格中实现的简单公式,将这四个数值转化为估计的十年痴呆风险,并可与建议的阈值比较以将某人分类为“升高风险”或“较低风险”。他们还解释了如果在不同人群或不同年龄段中痴呆更常见或更少见,卫生系统如何调整模型的初始基线。
这对患者和临床医生意味着什么
目前,这项工作是一项概念验证而非现成的筛查计划。它表明一小组熟悉的指标——年龄、一项结构化的认知测试、空腹血糖和一个标准的心脏风险评分——可以在诊断前最多十年内有意义地区分老年人的较低与较高痴呆风险。在广泛应用之前,该模型需要在其他国家进行验证、使用更符合日常临床实践的简化认知测试,并结合现实世界中患者与临床医生对概率性风险估计的反应研究。尽管如此,结论令人鼓舞:同时关注大脑健康、血糖与心脏健康,可能有助于识别出最有可能从更密切监测和早期预防策略中受益的人群。
引用: Chalmers, R.A., Cervin, M., Choo, C. et al. Machine learning models for dementia risk prediction: evidence from the Sydney Memory and Ageing Study. npj Dement. 2, 27 (2026). https://doi.org/10.1038/s44400-026-00071-1
关键词: 痴呆风险预测, 机器学习, 认知衰老, 心代谢健康, 早期检测