Clear Sky Science · es
Modelos de aprendizaje automático para la predicción del riesgo de demencia: evidencias del Sydney Memory and Ageing Study
Por qué esto importa para un envejecimiento saludable
La demencia es una de las afecciones más temidas en la tercera edad, aunque muchas personas solo reciben el diagnóstico cuando los problemas de memoria y pensamiento ya están avanzados. Este estudio plantea una pregunta esperanzadora: usando información que las clínicas ya recogen —como la edad, pruebas sencillas de función cognitiva, glucemia y salud cardíaca— ¿podemos identificar quién tiene mayor probabilidad de desarrollar demencia hasta una década antes? Si fuera así, los médicos podrían centrar la vigilancia y las medidas preventivas en quienes más las necesitan.
Una mirada más cercana a un estudio longitudinal sobre envejecimiento
Los investigadores se basaron en el Sydney Memory and Ageing Study, que ha seguido a más de mil australianos de 70 años o más que estaban libres de demencia al incorporarse. A lo largo de cerca de diez años, algunos participantes desarrollaron demencia y otros no. Al inicio, todos realizaron pruebas detalladas de memoria y función cognitiva, cuestionarios sobre el estado de ánimo y revisiones médicas que incluyeron análisis de sangre y medidas de la salud cardiaca y vascular. Al observar qué características iniciales eran más frecuentes entre quienes luego desarrollaron demencia, el equipo pudo entrenar modelos computacionales para reconocer perfiles de alto riesgo.
Enseñar a las máquinas a detectar el riesgo futuro
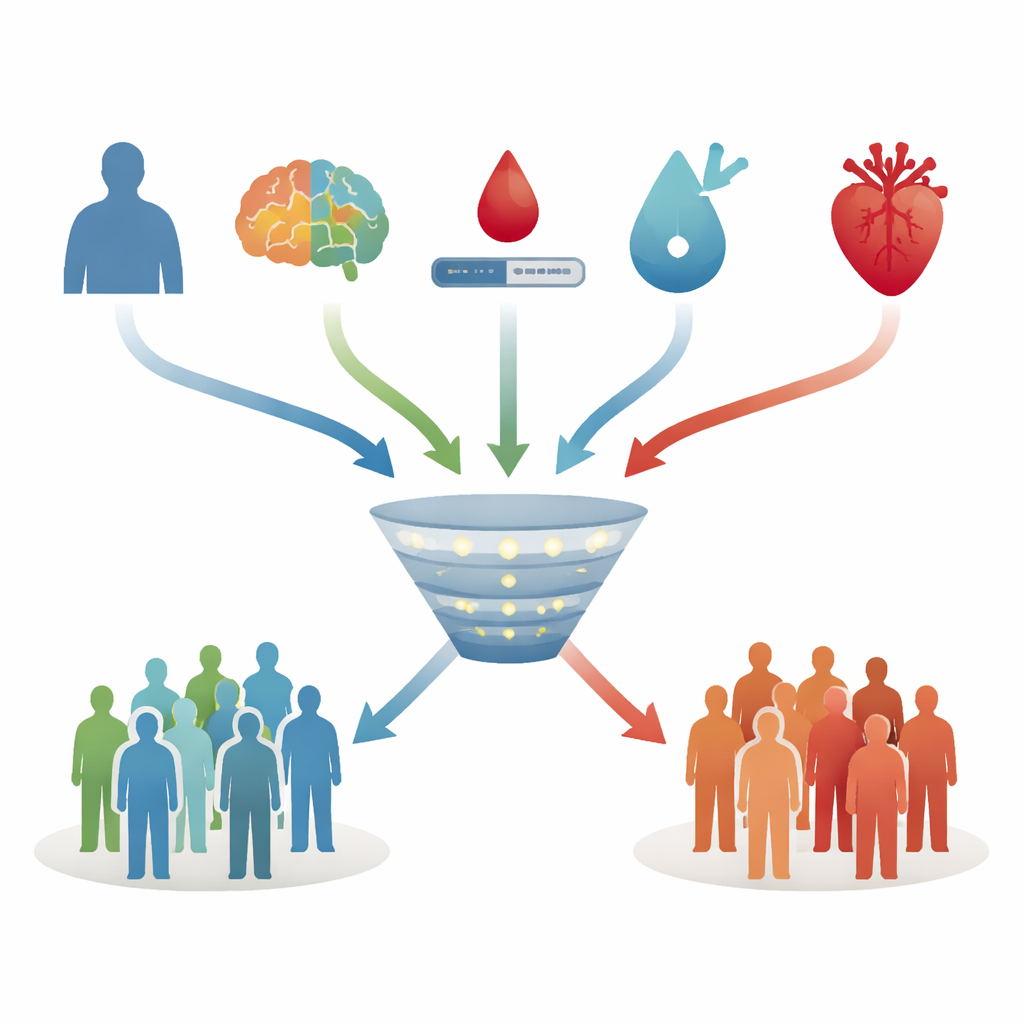
Para construir estas herramientas de predicción, los autores compararon varios métodos comunes de aprendizaje automático. Todos los modelos intentaron responder la misma pregunta: dada la información basal de una persona, ¿qué probabilidad tiene de presentar demencia diez años después, suponiendo que siga viva y sea evaluada? Los algoritmos se entrenaron con datos de aproximadamente el 70% de los participantes y luego se probaron en el 30% restante, reservado como control no visto. Las entradas incluyeron edad, educación, síntomas de ánimo, puntuaciones cognitivas detalladas, relación cintura–cadera, una puntuación estándar de riesgo de enfermedad cardíaca y medidas sanguíneas como colesterol, triglicéridos, ácido úrico, función renal, marcadores de inflamación y glucosa en ayunas. Más tarde se examinó como complemento opcional un marcador genético de riesgo conocido como APOE ε4.
Cuatro medidas simples concentran la mayor parte de la señal
Entre los distintos enfoques, un método simplificado llamado regresión LASSO fue el que mejor funcionó. A pesar de partir de muchos candidatos, este modelo conservó solo cuatro predictores: edad, rendimiento cognitivo global, glucosa en ayunas y una puntuación combinada de riesgo cardiometabólico. La edad avanzada, una glucosa más alta y un perfil cardiovascular peor aumentaban la probabilidad predicha, mientras que mejores puntuaciones cognitivas la redujeron. En el grupo de prueba retenido, este modelo de cuatro factores pudo ordenar correctamente a una persona que desarrollaría demencia por encima de otra que no lo haría en aproximadamente tres cuartas partes de los casos, un nivel considerado aceptable para herramientas clínicas de riesgo. También ofreció un buen equilibrio entre detectar casos futuros verdaderos y evitar demasiadas falsas alarmas.
Lo que no aportó mucho y cómo usar la herramienta
Sorprendentemente, añadir el estado genético APOE ε4 al modelo de mejor rendimiento no mejoró su precisión y empeoró ligeramente algunas medidas, una vez que ya se habían incluido la edad, el rendimiento cognitivo, la glucosa y el riesgo cardíaco. Esto sugiere que, al menos en este grupo de adultos mayores, la historia principal la cuentan la información clínica de rutina más que las pruebas genéticas o marcadores sanguíneos experimentales. Los autores proporcionan una fórmula simple que se puede implementar en una hoja de cálculo para convertir estos cuatro valores en una estimación del riesgo de demencia a diez años, que luego puede compararse con un umbral sugerido para clasificar a una persona como de “riesgo elevado” frente a “riesgo menor”. También explican cómo los sistemas de salud podrían ajustar el punto de partida del modelo si la demencia es más o menos común en sus propias poblaciones o en distintos grupos de edad.
Qué significa esto para pacientes y clínicos
Por ahora, este trabajo es una prueba de concepto y no un programa de cribado listo para usar. Muestra que un pequeño conjunto de medidas familiares —edad, una prueba estructurada de pensamiento, glucosa en ayunas y una puntuación estándar de riesgo cardíaco— puede clasificar de forma relevante a los adultos mayores en grupos de menor y mayor riesgo de demencia hasta una década antes del diagnóstico. Antes de usarse de forma generalizada, el modelo debe probarse en otros países, con pruebas cognitivas más sencillas que encajen en la práctica diaria y junto a cuestiones del mundo real sobre cómo responden pacientes y clínicos a estimaciones probabilísticas de riesgo. Aun así, el mensaje es alentador: prestar atención conjunta a la salud cerebral, la glucosa y la salud cardíaca puede ayudar a identificar quién podría beneficiarse más de una vigilancia más estrecha y de estrategias preventivas tempranas.
Cita: Chalmers, R.A., Cervin, M., Choo, C. et al. Machine learning models for dementia risk prediction: evidence from the Sydney Memory and Ageing Study. npj Dement. 2, 27 (2026). https://doi.org/10.1038/s44400-026-00071-1
Palabras clave: predicción del riesgo de demencia, aprendizaje automático, envejecimiento cognitivo, salud cardiometabólica, detección temprana