Clear Sky Science · nl
Machine learning-modellen voor voorspelling van dementierisico: bewijs uit de Sydney Memory and Ageing Study
Waarom dit belangrijk is voor gezond ouder worden
Dementie is een van de meest gevreesde aandoeningen op latere leeftijd, maar veel mensen krijgen pas een diagnose wanneer geheugen- en denkproblemen al ver gevorderd zijn. Deze studie stelt een bemoedigende vraag: kunnen we met informatie die klinieken al verzamelen — zoals leeftijd, eenvoudige denktests, nuchtere bloedsuiker en hartgezondheid — mensen aanwijzen die tot een decennium eerder een grotere kans hebben om dementie te krijgen? Als dat lukt, kunnen artsen monitoring en preventieve inspanningen richten op degenen die die het meest nodig hebben.
Een nadere blik op een langlopende verouderingsstudie
De onderzoekers gebruikten gegevens uit de Sydney Memory and Ageing Study, die meer dan duizend Australiërs volgde die bij aanvang 70 jaar of ouder waren en vrij van dementie. Over ongeveer tien jaar ontwikkelden sommige deelnemers dementie en anderen niet. Aan het begin vulde iedereen uitgebreide geheugen- en denktests in, vragenlijsten over stemming en ondergingen zij medische controles, inclusief bloedonderzoek en metingen van hart- en vaatgezondheid. Door te kijken welke beginsituatiekenmerken het vaakst voorkwamen bij degenen die later dementie kregen, kon het team computermodellen trainen om risicoprofielen te herkennen.
Machines leren toekomstig risico te signaleren
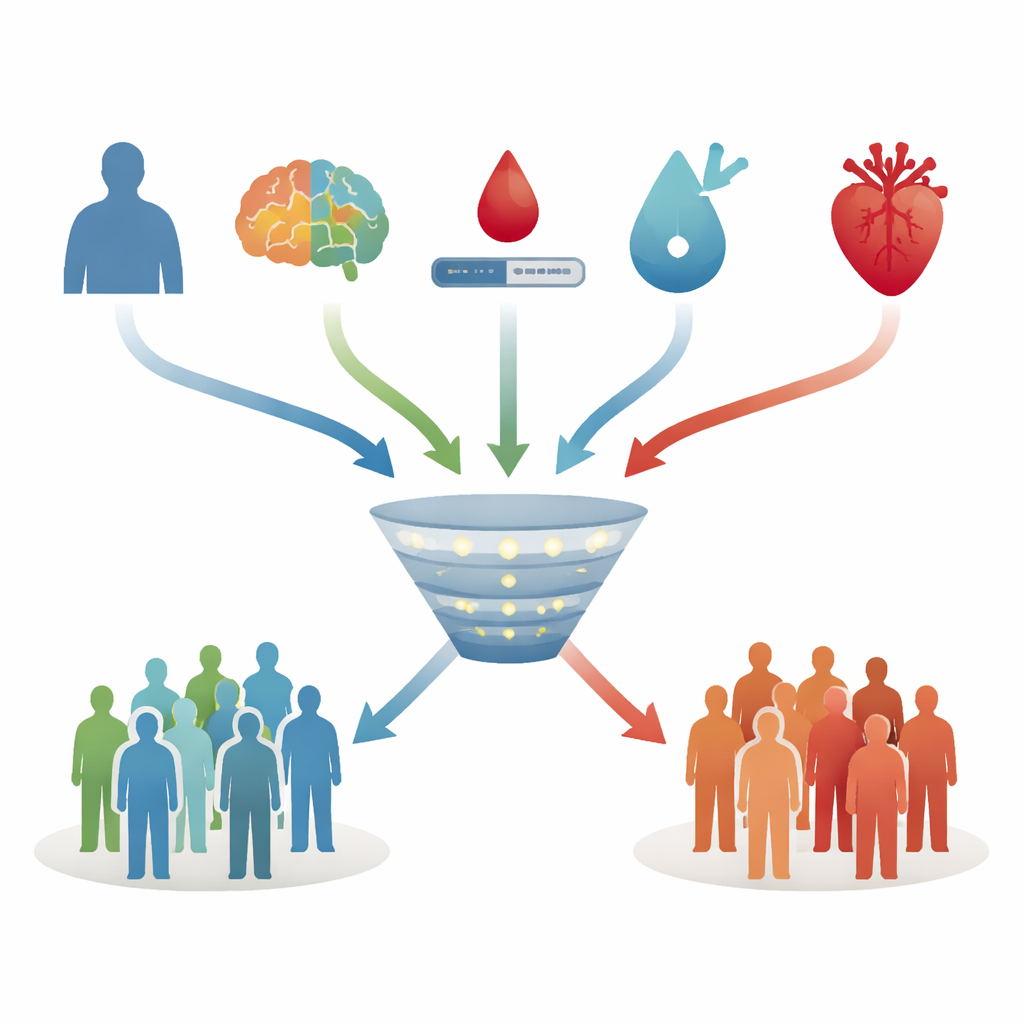
Om deze voorspellingsinstrumenten te bouwen, vergeleken de auteurs verschillende gangbare machine learning-methoden. Alle modellen probeerden dezelfde vraag te beantwoorden: gegeven iemands beginsituatie, hoe waarschijnlijk is het dat die persoon tien jaar later dementie heeft, ervan uitgaande dat hij of zij nog leeft en beoordeeld wordt? De algoritmen werden getraind op gegevens van ongeveer 70 procent van de deelnemers en vervolgens getest op de resterende 30 procent die apart werd gehouden als een onbekende test. Invoervariabelen waren onder andere leeftijd, opleiding, stemmingssymptomen, gedetailleerde denktestscores, taille-heupverhouding, een standaard risicoscore voor hartziekten en bloedwaarden zoals cholesterol, triglyceriden, urinezuur, nierfunctie, ontstekingsmarkers en nuchtere glucose. Een genetische risicomarker, bekend als APOE ε4, werd later als optionele toevoeging onderzocht.
Vier eenvoudige maten dragen het meeste signaal
Onder de verschillende benaderingen presteerde een gestroomlijnde methode genaamd LASSO-regressie het beste. Ondanks het grote aantal kandidaat-variabelen behield dit model slechts vier voorspellers: leeftijd, algemene denkprestaties, nuchtere bloedglucose en een gecombineerde score voor hart- en vaatrisico. Oudere leeftijd, hogere glucosewaarden en een slechter cardiovasculair profiel verhoogden elk het voorspelde risico, terwijl betere denkprestaties het naar beneden bijstuurden. In de apart gehouden testgroep kon dit viervoudige model in ongeveer driekwart van de gevallen correct een persoon met toekomstige dementie hoger scoren dan een persoon zonder dementie—een niveau dat als acceptabel wordt beschouwd voor klinische risicohulpmiddelen. Het bood ook een goede balans tussen het opsporen van echte toekomstige gevallen en het vermijden van te veel vals-positieve meldingen.
Wat weinig toevoegde en hoe het hulpmiddel te gebruiken
Verrassend genoeg verbeterde het toevoegen van de APOE ε4-genstatus aan het best presterende model de nauwkeurigheid niet en verslechterde sommige maten zelfs licht, zodra leeftijd, denkprestaties, bloedsuiker en hartaandoeningsrisico al waren opgenomen. Dit suggereert dat in deze groep ouderen het verhaal vooral wordt verteld door routinematige klinische informatie in plaats van door genetische tests of experimentele bloedmarkers. De auteurs geven een eenvoudige formule die in een spreadsheet kan worden toegepast om van deze vier waarden een geschat tienjaarsrisico op dementie te maken, dat vervolgens vergeleken kan worden met een voorgestelde drempel om iemand als “verhoogd risico” versus “lager risico” te classificeren. Ze leggen ook uit hoe zorgsystemen het uitgangspunt van het model kunnen aanpassen wanneer dementie in hun eigen populaties of in verschillende leeftijdsbanden vaker of minder vaak voorkomt.
Wat dit betekent voor patiënten en clinici
Voorlopig is dit werk een proof-of-concept en geen kant-en-klaar screeningsprogramma. Het laat zien dat een kleine set vertrouwde maten—leeftijd, een gestructureerde denktest, nuchtere glucose en een standaard hartscores—oudere volwassenen zinvol kan indelen in lagere en hogere dementierisicogroepen tot een decennium vóór diagnose. Voordat het breed toegepast wordt, moet het model in andere landen worden getest, met eenvoudigere denktests die in de dagelijkse praktijk passen, en naast vragen uit de echte wereld over hoe patiënten en clinici reageren op probabilistische risicoschattingen. Toch is de boodschap bemoedigend: aandacht voor hersengezondheid, bloedsuiker en hartgezondheid samen kan helpen bepalen wie het meest kan profiteren van intensievere monitoring en vroege preventieve maatregelen.
Bronvermelding: Chalmers, R.A., Cervin, M., Choo, C. et al. Machine learning models for dementia risk prediction: evidence from the Sydney Memory and Ageing Study. npj Dement. 2, 27 (2026). https://doi.org/10.1038/s44400-026-00071-1
Trefwoorden: voorspelling dementierisico, machine learning, cognitief verouderen, cardiometabole gezondheid, vroegtijdige opsporing