Clear Sky Science · zh
HiAER-spike 软件-硬件可重构平台:面向大规模事件驱动类神经形态计算
为什么一种新型计算机很重要
当今大多数人工智能仍运行在为电子表格和文字处理器而设计的、已有数十年历史的硬件上,而不是为“大脑”设计的硬件。随着研究者追求更智能、更高效的机器,他们逐渐遇到功耗、速度和规模的限制。本文介绍了 HiAER-Spike —— 一种以脉冲(短暂的电信号事件)处理信息的类神经形态计算平台,类似真实神经元的工作方式。该平台作为圣地亚哥超算中心的共享资源构建,旨在让全球科学家在接近小型动物大脑规模的条件下实验类脑人工智能,同时比传统系统消耗更少的能量。
构建类脑机器
HiAER-Spike 是由大量服务器组成的集群,每台服务器都配备了可重构能力强的芯片——FPGA。这些芯片并非执行普通的软件指令,而是被配置成庞大的人工神经元和突触网络,称为脉冲神经网络。整个系统设计可支持大约1.6亿个模型神经元和400亿个突触——超过小鼠大脑神经元数量的两倍以上——并能以快于实时的速度进行模拟。一种特殊的通信方案,称为分层地址事件路由(hierarchical address-event routing),确保脉冲可在同芯片的神经元组、不同芯片以及服务器之间快速传递,在密集的局部流量和稀疏的长程连接之间取得平衡,这与大脑中灰质和白质的组织类似。
在受限硬件中容纳巨大网络
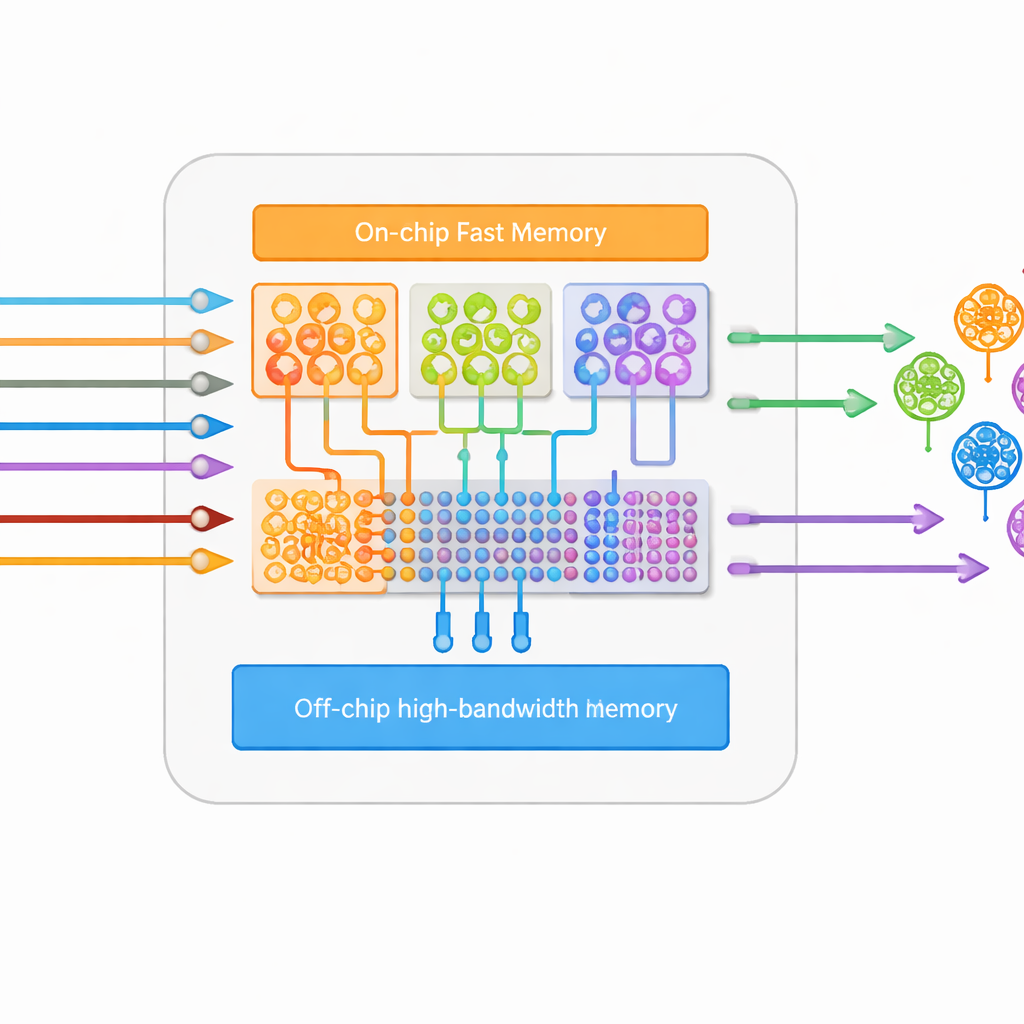
构建此类系统的一项主要挑战是存储所有连接。现代神经网络往往非常大但也很稀疏:大多数可能的连接并不存在。HiAER-Spike 利用这种稀疏性,仅以高效的列表方式存储实际存在的连接,而不是维护一个完整的可能性网格。突触权重保存在每个 FPGA 的高带宽存储器中,而神经元和轴突的快速变化状态则保存在更快的片上内存中。当脉冲发生时,系统首先查找受影响的突触,然后读取其权重并更新目标神经元。这个两步过程,结合对内存中数据的精心打包,使得即便在网络规模增长时,能耗和延迟仍然保持较低。
让先进硬件易于使用
为将该专用机器向非专家开放,作者们开发了基于 Python 和 C++ 的高级软件接口。用户通过简单的对象描述他们的脉冲网络——定义神经元类型、输入、连接和输出——而无需关心底层硬件细节。相同的代码既可作为本地软件仿真运行,也可通过 Neuroscience Gateway 门户提交到 HiAER-Spike 硬件上运行。该平台目前支持简单的二值神经元和泄漏积分-发放(leaky integrate-and-fire)神经元,支持行为中的随机性选项,并允许在同一网络中混合不同的神经元类型。此设计使研究者能够在笔记本上原型化模型,然后无缝扩展到大型类神经形态集群。
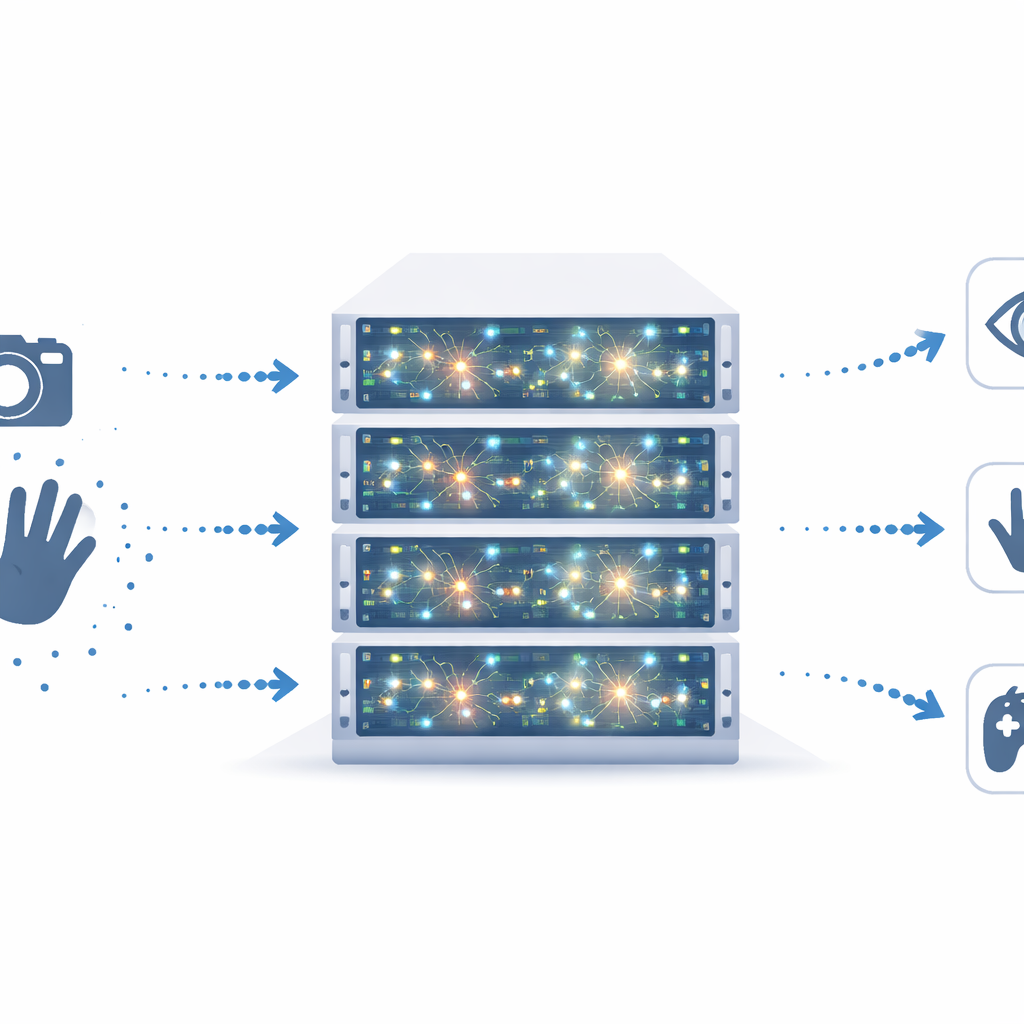
将脉冲应用于实际任务
为了展示平台能力,团队将多种标准的视觉和控制模型转换为脉冲形式,并在单个 FPGA 核心上运行它们。他们测试了经典 MNIST 数据集上的数字识别、使用事件驱动摄像头(输出脉冲而非帧)的手势识别、CIFAR-10 图像上的目标识别,甚至使用基于脉冲的运动表示来控制 Atari Pong 游戏。在这些任务中,硬件在权重量化后与软件仿真在准确率上紧密匹配,误差通常不超过几个百分点,同时提供极低的延迟和能耗。例如,一些数字识别网络在每张图像仅消耗微焦耳级能量、延迟为微秒级的情况下,准确率超过98%。
该新平台可能的前景
对普通读者来说,核心信息是 HiAER-Spike 是一个灵活的、类脑的计算测试平台,任何研究社区的成员都可以远程使用。即便在早期阶段,单核也能运行用于识别来自事件驱动摄像头的手势等任务的可观规模脉冲网络,所需的能量和时间远低于许多竞品。随着更多核心和电路板上线,以及软件引入更丰富的神经元模型和学习规则,该平台有望帮助弥合神经科学与人工智能之间的鸿沟——支持探索大量脉冲网络如何驱动高效感知、决策以及未来低功耗智能设备的实验。
引用: Frank, G., Hota, G., Wang, K. et al. HiAER-spike software-hardware reconfigurable platform for event-driven neuromorphic computing at scale. npj Unconv. Comput. 3, 22 (2026). https://doi.org/10.1038/s44335-026-00062-8
关键词: 类神经形态计算, 脉冲神经网络, FPGA 加速器, 事件驱动视觉, 类脑硬件