Clear Sky Science · zh
在肿瘤学中为新疗法寻找最有前景适应症
为何找到合适的患者至关重要
现代抗癌药物能挽救生命,但确定究竟哪些患者群体会受益的过程既缓慢又昂贵且充满不确定性。每一种新药都必须在特定的癌种和亚型中进行检验,选择错误的适应症可能会浪费数年的研究时间和数百万美元——与此同时患者在等待。该研究提出了一种以数据为驱动的方法,利用来自数百万真实患者的信息,在更早、更系统的阶段指导这些选择,而不是主要依赖直觉和偶然发现。
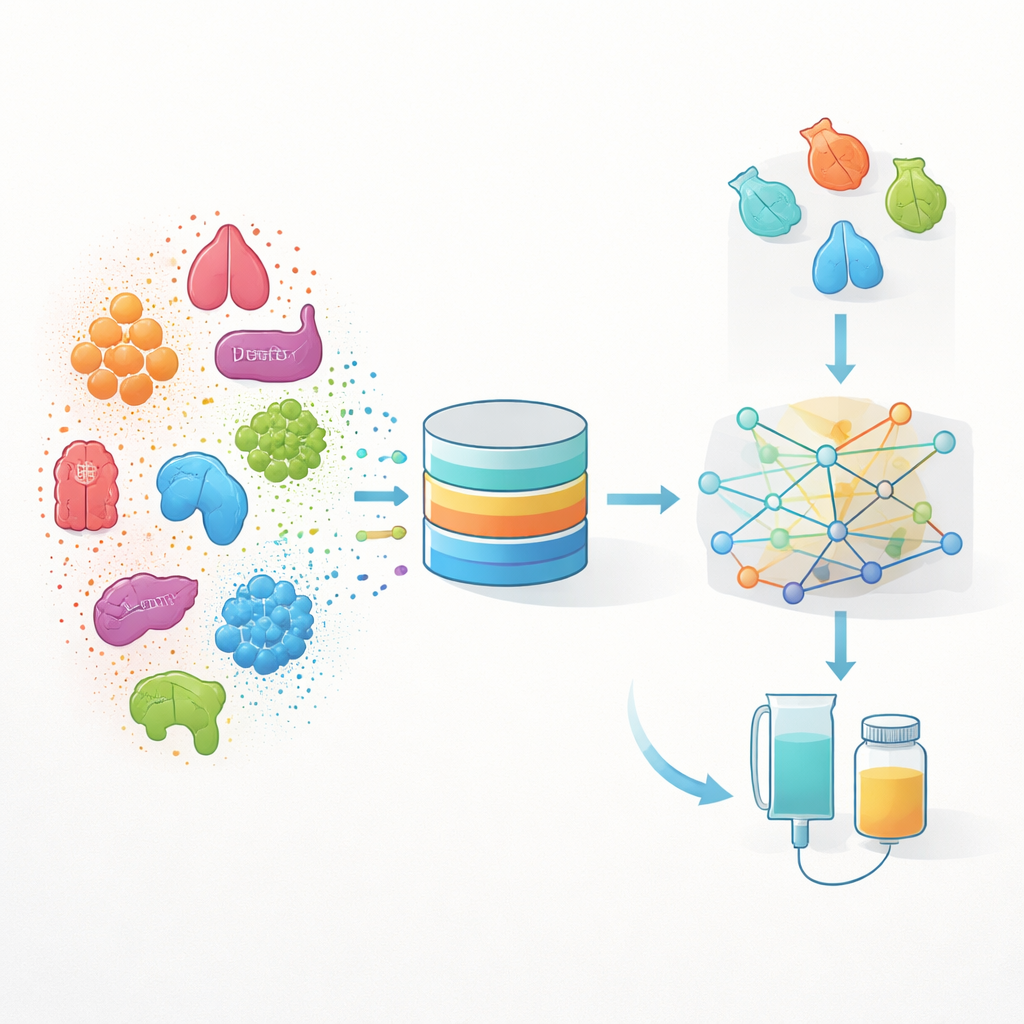
将日常医疗数据转化为一张图谱
作者构建了一种称为 INSPIRE 的方法,全称为“INdication Selection and Prioritization In Real-world data and Evaluation”。INSPIRE 并非仅从实验室研究出发,而是从美国常规护理中收集的大规模真实世界数据集中学习——包括超过两百万名癌症患者的电子健康记录和保险理赔数据。这些记录为每位患者留下了长长的事件轨迹:诊断、治疗、化验、肿瘤样本等。团队将这些事件逐一转化为数学“特征”,然后使用机器学习将它们置于共享空间中,使得在相似患者中常同时出现的医疗事件在该空间中彼此靠近。
超越大而笼统的癌症标签
大多数医院和结算系统使用的管理编码侧重于肿瘤位点(例如肺部的哪个部位),而非显微镜下的组织学特征。对于癌症药物开发而言,这种描述常常不够精确,因为同一器官内的两种肿瘤可表现截然不同并对不同疗法有不同反应。INSPIRE 通过直接处理病理报告来应对这一问题——这些报告对肿瘤组织进行详细描述。该方法基于报告构建了细分的癌症类别,例如特定的肺癌亚型,并将早期疾病与进展性、转移性疾病区分开来。随后,它将这些肿瘤信息沿患者时间线“广播”,以便将其与随后发生的治疗、检测结果和其他事件连接起来。
在一种主要免疫治疗药物上测试该方法
为检验 INSPIRE 是否能在真实世界决策中提供帮助,研究者将注意力集中在针对 PD‑1 的药物上——这是广泛使用的癌症免疫疗法的免疫检查点抑制剂。他们通过仅使用 2012 年至 2015 年的数据并排除所有接受过 PD‑1 药物或进行相关生物标志物检测的患者,模拟这些药物尚属新兴时期的情形。研究者选择了三种最早获得 PD‑1 治疗批准的癌症作为“参考”疾病。INSPIRE 随后基于患者病程模式衡量数据中每个其他癌症亚型与这些参考的相似度,并在不知道哪些癌种随后会获得官方批准的情况下,生成了一份有前景适应症的排名列表。
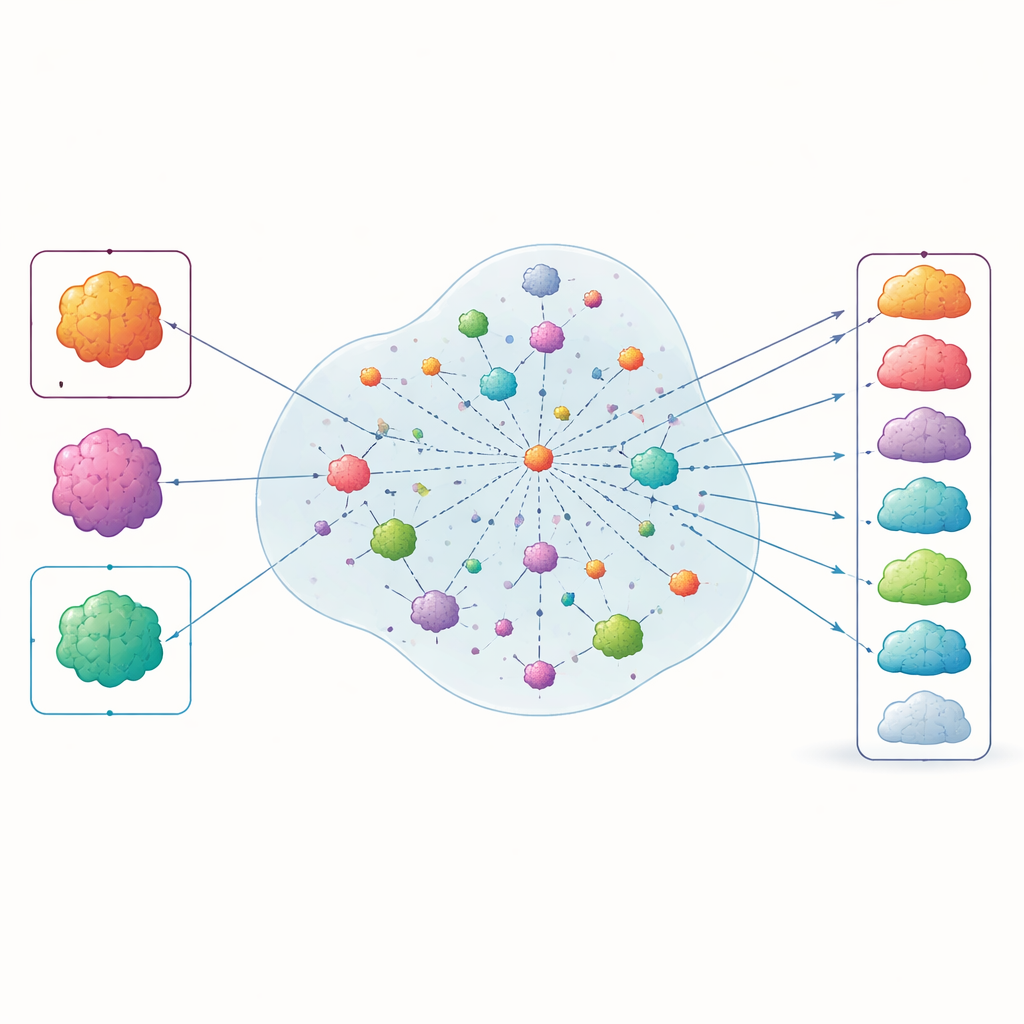
排名显示了什么
当作者“揭盲”结果并将 INSPIRE 的排名列表与 2015 年后监管机构授予的批准进行比较时,大约 70% 最终获得 PD‑1 批准的癌症适应症出现在前 50 名之中。在试验中多次失败的癌种往往排名较低。当研究者将时间窗扩大以包含更近年份或改变模型的内部参数时,该方法显示了相似的表现,表明该方法相当稳健。分析还表明,INSPIRE 的内部特征映射将医学上相关的项目(例如肿瘤类型、治疗和生物标志物)归到一起,支持其捕获到的是有意义的临床结构而非随机模式的观点。
这将如何改变癌症药物开发
INSPIRE 并非旨在取代实验室科学或临床判断,而是作为另一条证据线。在实践中,制药公司或学术团队开发新抗癌药物时,可以先输入少量已有确凿证据表明药物有效的肿瘤类型。INSPIRE 随后会利用真实世界数据图谱突出显示在患者表现、进展和治疗方式上相似的其他癌症亚型。那些适应症可被优先用于进一步的生物学研究,并最终进入临床试验。通过提高首先选择正确癌种进行测试的几率,像 INSPIRE 这样的做法可以缩短开发周期、降低成本,并帮助患者更早获得有效疗法。
引用: Eckhoff, M., Klingelschmitt, S., Van Ruijssevelt, L. et al. Finding the most promising indications for novel treatments in oncology. npj Precis. Onc. 10, 135 (2026). https://doi.org/10.1038/s41698-026-01352-x
关键词: 癌症药物开发, 真实世界数据, 肿瘤学中的机器学习, 免疫治疗, 治疗适应症选择