Clear Sky Science · de
Die vielversprechendsten Indikationen für neuartige Krebstherapien finden
Warum es wichtig ist, die richtigen Patientinnen und Patienten zu finden
Moderne Krebsmedikamente können Leben retten, doch herauszufinden, welche genau definierten Patientengruppen davon profitieren, ist langsam, teuer und unsicher. Jedes neue Präparat muss in bestimmten Krebsarten und -subtypen getestet werden, und die falsche Wahl kann Jahre an Forschung und Millionen von Dollar verschlingen – während Patientinnen und Patienten warten. Diese Studie stellt einen datengetriebenen Weg vor, um diese Entscheidungen früher und systematischer zu unterstützen, indem Informationen von Millionen realer Patientinnen und Patienten genutzt werden statt sich größtenteils auf Vermutungen und Zufallsfunde zu verlassen.
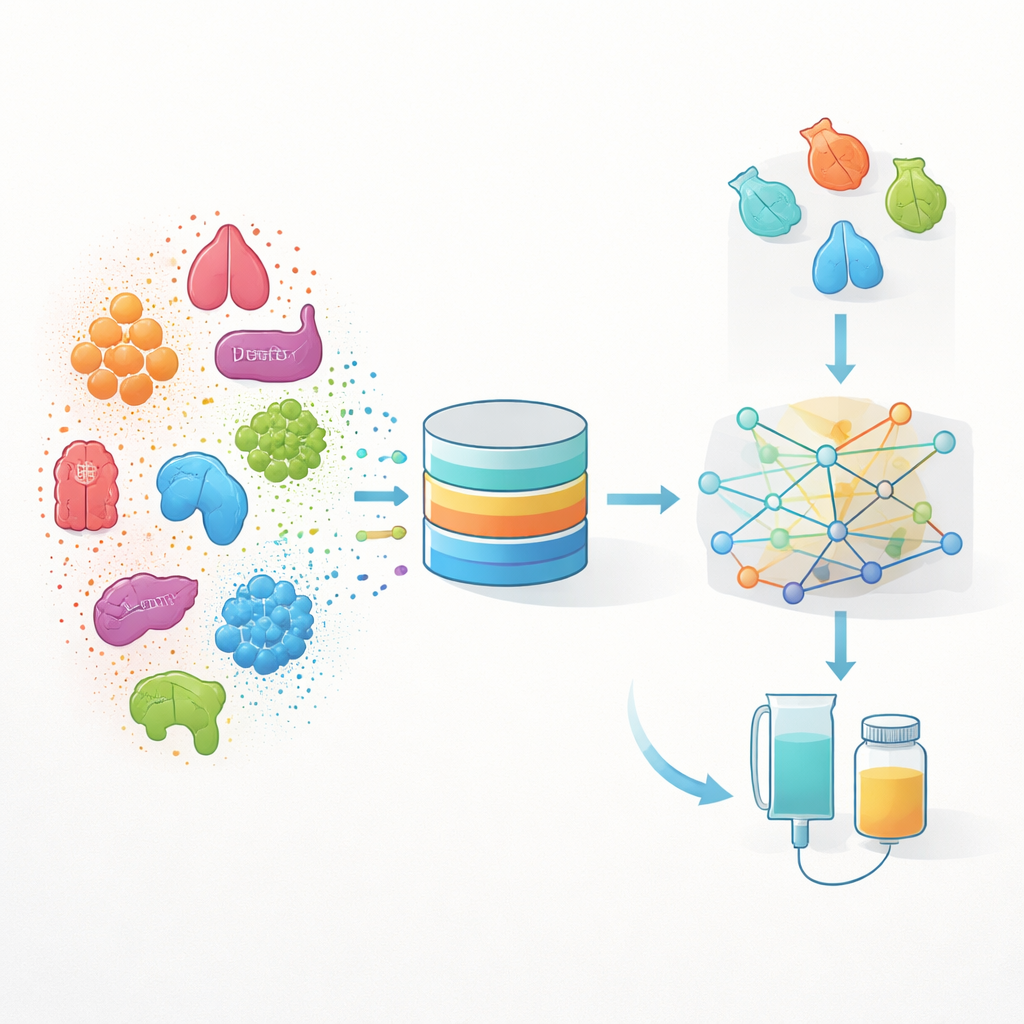
Alltägliche medizinische Daten in eine Landkarte verwandeln
Die Autoren entwickeln einen Ansatz namens INSPIRE, kurz für „INdication Selection and Prioritization In Real-world data and Evaluation“. Statt allein bei Laborexperimenten anzusetzen, lernt INSPIRE aus großen Real-World-Datensätzen, die während der Routineversorgung in den USA gesammelt wurden – elektronische Gesundheitsakten und Abrechnungsdaten für mehr als zwei Millionen Krebspatientinnen und -patienten. Diese Aufzeichnungen enthalten eine lange Abfolge von Ereignissen für jede Person: Diagnosen, Behandlungen, Laboruntersuchungen, Tumorproben und mehr. Das Team wandelt jedes dieser Ereignisse in eine mathematische „Merkmal“ um und nutzt dann maschinelles Lernen, um sie in einem gemeinsamen Raum zu platzieren, in dem medizinische Ereignisse, die bei ähnlichen Patientinnen und Patienten auftreten, nahe beieinander liegen.
Weiter denken als breite Krebskennzeichnungen
Die meisten Krankenhaus- und Abrechnungssysteme beschreiben Krankheiten mit administrativen Codes, die betonen, wo ein Tumor sitzt (zum Beispiel welcher Teil der Lunge) statt wie er unter dem Mikroskop aussieht. Für die Entwicklung von Krebsmedikamenten ist das oft nicht genau genug, weil zwei Tumoren im selben Organ sich sehr unterschiedlich verhalten und unterschiedlich auf Therapien ansprechen können. INSPIRE geht dieses Problem an, indem es direkt mit Pathologieberichten arbeitet – den detaillierten Beschreibungen des Tumorgewebes. Aus diesen Berichten baut die Methode fein differenzierte Krebs-Kategorien, etwa spezifische Untertypen von Lungenkrebs, und trennt frühe von fortgeschrittener, metastatischer Erkrankung. Anschließend „sendet“ sie diese Tumorinformationen entlang der Patienten-Zeitleiste aus, sodass sie mit späteren Behandlungen, Testergebnissen und anderen Ereignissen verknüpft werden können.
Die Methode an einer wichtigen Immuntherapie testen
Um zu prüfen, ob INSPIRE reale Entscheidungen hätte leiten können, konzentrierten sich die Forschenden auf Medikamente, die PD‑1 blockieren – einen Immun-Checkpoint, der von weit verbreiteten Krebstherapien adressiert wird. Sie ahmten die Situation nach, in der diese Medikamente noch neu waren, indem sie nur Daten von 2012 bis 2015 verwendeten und alle Patientinnen und Patienten ausschlossen, die ein PD‑1-Medikament erhalten hatten oder den zugehörigen Biomarkertest hatten. Als „Referenz“-Erkrankungen wählten sie drei Krebsarten, die zu den ersten gehörten, für die eine PD‑1-Behandlung zugelassen wurde. INSPIRE maß dann, wie ähnlich jeder andere Krebsuntertyp in den Daten diesen Referenzen war, basierend auf Mustern in den Patientenverläufen, und erstellte eine Rangliste vielversprechender Indikationen, ohne zu wissen, welche später offiziell zugelassen würden.
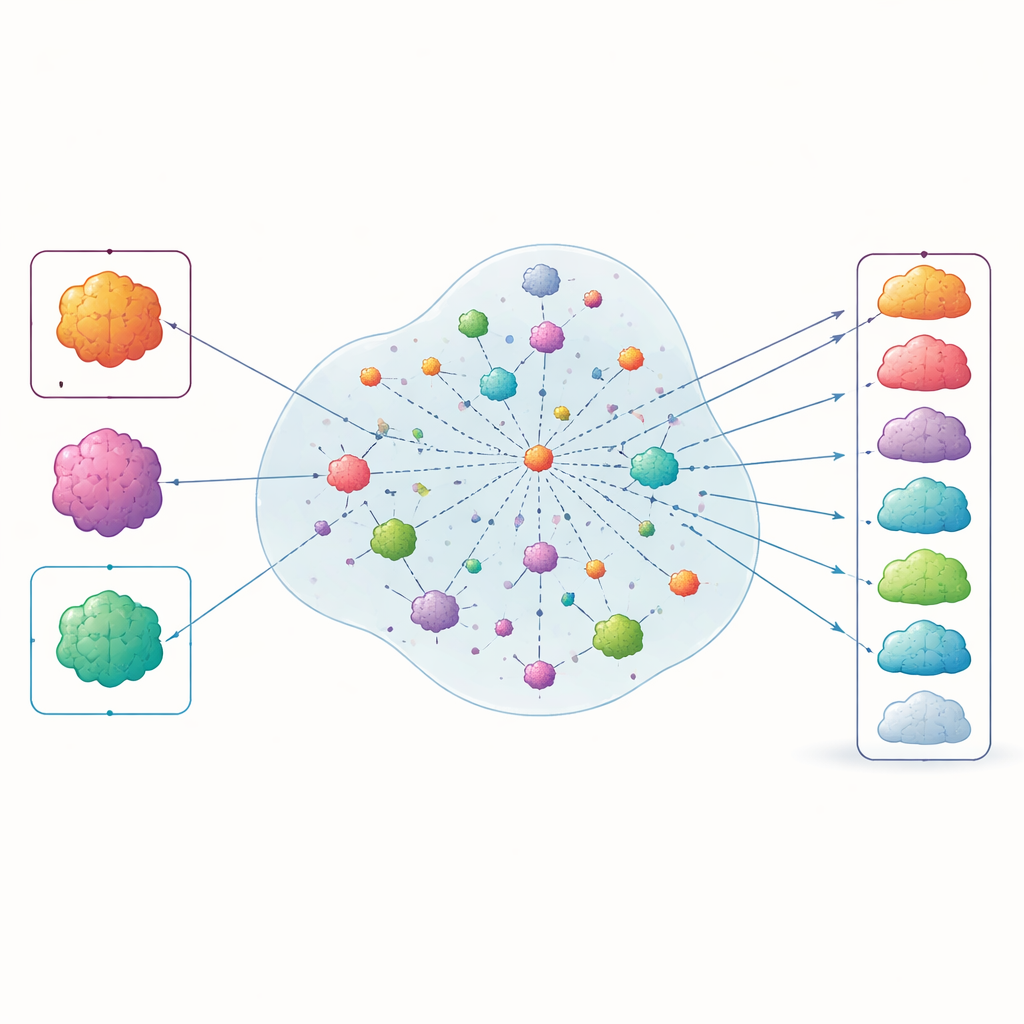
Was die Ranglisten zeigten
Als die Autorinnen und Autoren die Ergebnisse „entblindeten“ und INSPIRE’s Rangliste mit den Zulassungen verglichen, die Regulierungsbehörden nach 2015 erteilten, tauchten etwa 70 Prozent der Krebsindikationen, die schließlich PD‑1-Zulassung erhielten, unter den Top 50 auf. Krebserkrankungen, bei denen PD‑1-Präparate in Studien wiederholt versagten, rangierten tendenziell weiter unten. Die Methode zeigte ähnliche Leistungen, als die Forschenden das Zeitfenster auf jüngere Jahre ausdehnten und die internen Modellparameter variierten, was darauf hindeutet, dass der Ansatz relativ robust ist. Analysen zeigten außerdem, dass INSPIRE’s interne Merkmalskarte medizinisch verwandte Elemente – etwa Tumortypen, Behandlungen und Biomarker – zusammen gruppierte, was die Annahme stützt, dass sie sinnvolle klinische Strukturen erfasst und nicht nur zufällige Muster.
Wie das die Entwicklung von Krebsmedikamenten verändern könnte
INSPIRE soll Laborwissenschaft und klinisches Urteilsvermögen nicht ersetzen, sondern eine zusätzliche Evidenzquelle bieten. In der Praxis könnte ein Unternehmen oder eine akademische Gruppe, die ein neues Krebsmedikament entwickelt, eine kleine Anzahl von Tumortypen eingeben, für die es bereits starke Hinweise auf Wirksamkeit gibt. INSPIRE würde dann die Real-World-Daten-Landkarte nutzen, um andere Krebsuntertypen hervorzuheben, die in Bezug auf Präsentation, Verlauf und Behandlung der Patientinnen und Patienten ähnlich erscheinen. Diese Indikationen könnten für weitergehende biologische Untersuchungen und schließlich für klinische Studien priorisiert werden. Indem die Wahrscheinlichkeit erhöht wird, die richtigen Krebsarten zuerst auszuwählen, könnten Ansätze wie INSPIRE Entwicklungszeiten verkürzen, Kosten senken und Patientinnen und Patienten schneller den Zugang zu wirksamen Therapien ermöglichen.
Zitation: Eckhoff, M., Klingelschmitt, S., Van Ruijssevelt, L. et al. Finding the most promising indications for novel treatments in oncology. npj Precis. Onc. 10, 135 (2026). https://doi.org/10.1038/s41698-026-01352-x
Schlüsselwörter: Entwicklung von Krebsmedikamenten, Real-World-Daten, Maschinelles Lernen in der Onkologie, Immuntherapie, Auswahl von Therapieindikationen