Clear Sky Science · nl
De meest veelbelovende indicaties voor nieuwe oncologische behandelingen vinden
Waarom het vinden van de juiste patiënten ertoe doet
Moderne kankergeneesmiddelen kunnen levensreddend zijn, maar bepalen welke specifieke patiëntgroepen baat hebben is traag, kostbaar en onzeker. Elk nieuw middel moet in specifieke kankertypen en subtypes worden getest, en het kiezen van de verkeerde kan jaren onderzoek en miljoenen dollars verspillen—terwijl patiënten wachten. Deze studie presenteert een datagedreven manier om die keuzes eerder en systematischer te sturen, gebruikmakend van informatie van miljoenen echte patiënten in plaats van grotendeels te vertrouwen op intuïtie en toevallige ontdekkingen.
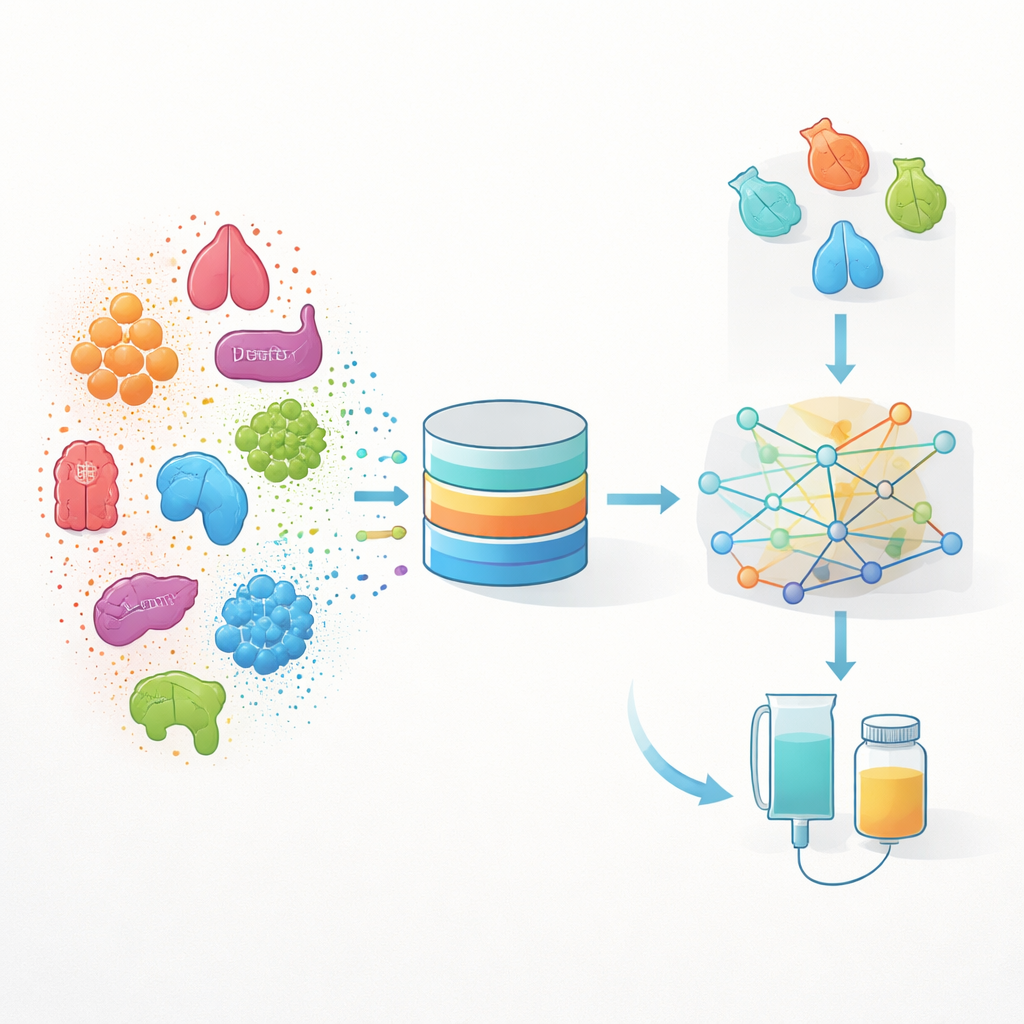
Alledaagse medische gegevens omzetten in een kaart
De auteurs bouwen een aanpak die ze INSPIRE noemen, wat staat voor “INdication Selection and Prioritization In Real-world data and Evaluation.” In plaats van alleen te beginnen bij laboratoriumexperimenten, leert INSPIRE van grote real-world datasets die tijdens routinezorg in de Verenigde Staten zijn verzameld—elektronische patiëntendossiers en verzekeringsclaims voor meer dan twee miljoen mensen met kanker. Deze dossiers bevatten een lange reeks gebeurtenissen voor elke patiënt: diagnoses, behandelingen, labtests, tumormonsters en meer. Het team zet elk van deze gebeurtenissen om in een wiskundige “kenmerk” en gebruikt vervolgens machine learning om ze in een gedeelde ruimte te plaatsen, waarbij medische gebeurtenissen die in vergelijkbare patiënten vaak samen voorkomen dicht bij elkaar eindigen.
Verder kijken dan brede kankerlabels
De meeste ziekenhuis- en declaratiesystemen beschrijven ziekten met administratieve codes die benadrukken waar een tumor zich bevindt (bijvoorbeeld welk deel van de long) in plaats van hoe hij er onder de microscoop uitziet. Voor ontwikkeling van kankergeneesmiddelen is dat vaak niet precies genoeg, omdat twee tumoren in hetzelfde orgaan zich heel verschillend kunnen gedragen en op verschillende therapieën kunnen reageren. INSPIRE pakt dit aan door rechtstreeks met pathologierapporten te werken—de gedetailleerde beschrijvingen van tumorweefsel. Uit deze rapporten bouwt de methode fijnmazige kanker-categorieën zoals specifieke longkankersubtypen en scheidt vroege ziekte van gevorderde, metastatische ziekte. Vervolgens "zendt" het deze tumorinformatie uit langs de tijdlijn van de patiënt zodat die kan worden gekoppeld aan behandelingen, testresultaten en andere gebeurtenissen die later plaatsvinden.
De methode testen op een belangrijke immunotherapie
Om te zien of INSPIRE echte beslissingen in de praktijk had kunnen sturen, richtten de onderzoekers zich op middelen die PD‑1 blokkeren, een immuuncheckpoint dat wordt aangestuurd door veelgebruikte kankerimmunotherapieën. Ze bootsten de situatie na waarin deze middelen nog nieuw waren door alleen gegevens uit 2012 tot 2015 te gebruiken en alle patiënten uit te sluiten die een PD‑1-middel kregen of de gerelateerde biomarkertest hadden. Ze kozen drie kankers die tot de eersten behoorden die goedkeuring voor PD‑1-behandeling kregen als “referentie”ziekten. INSPIRE mat vervolgens hoe vergelijkbaar elk ander kankersubtype in de data was met deze referenties, gebaseerd op patronen in de patiënttrajecten, en produceerde een gerangschikte lijst van veelbelovende indicaties zonder te weten welke later officiële goedkeuring zouden krijgen.
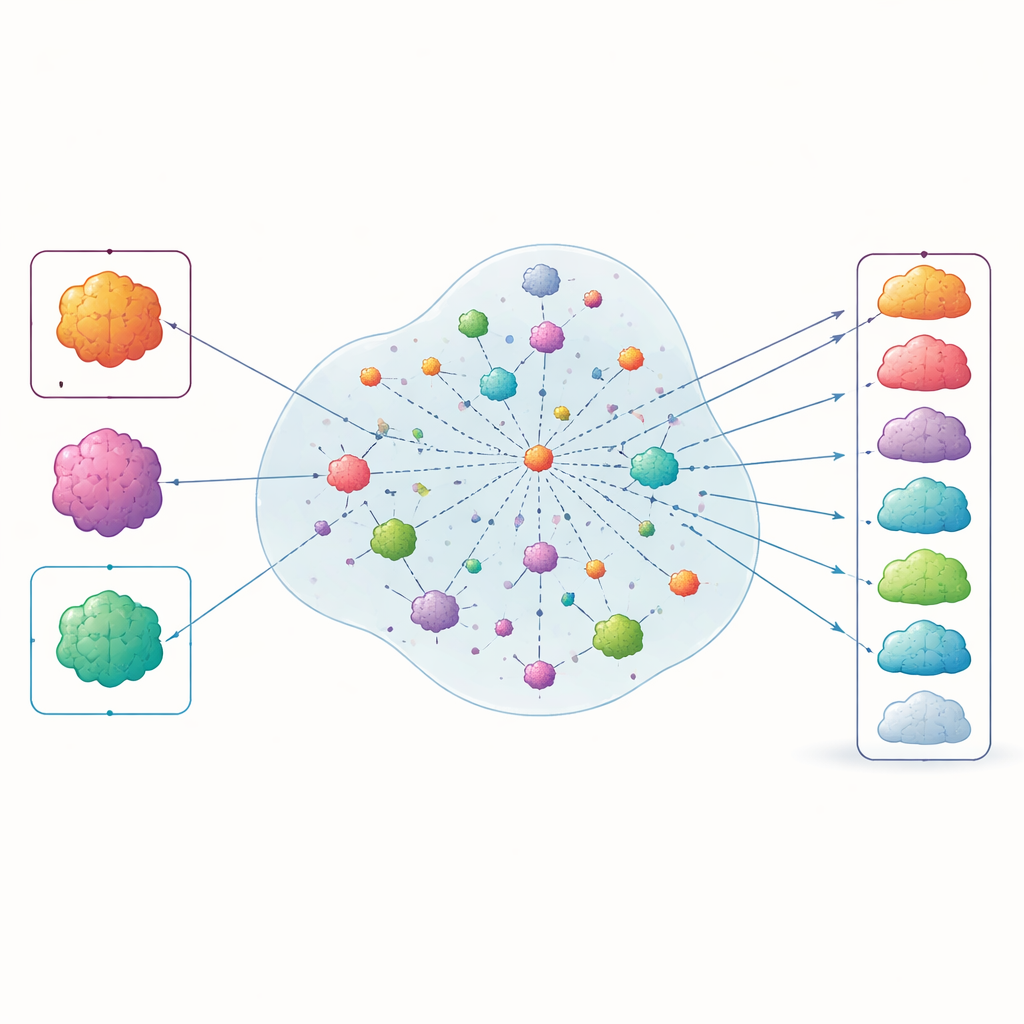
Wat de ranglijsten onthulden
Toen de auteurs de resultaten "ontraadden" en INSPIRE’s gerangschikte lijst vergeleken met de goedkeuringen die toezichthouders na 2015 zouden verlenen, verscheen ongeveer 70 procent van de kankeraanduidingen die uiteindelijk PD‑1-goedkeuring kregen in de top 50. Kankers waarbij PD‑1-middelen herhaaldelijk faalden in proeven hadden de neiging lager te scoren. De methode liet vergelijkbare prestaties zien toen de onderzoekers het tijdvenster uitbreidden naar recentere jaren en toen zij de interne parameters van het model varieerden, wat suggereert dat de aanpak redelijk robuust is. Analyses gaven ook aan dat INSPIRE’s interne kaart van kenmerken medisch verwante items groepeerde—zoals tumortypen, behandelingen en biomarkers—wat ondersteunt dat het betekenisvolle klinische structuren vastlegt in plaats van willekeurige patronen.
Hoe dit de ontwikkeling van kankergeneesmiddelen kan veranderen
INSPIRE is niet bedoeld om laboratoriumwetenschap of klinisch oordeel te vervangen, maar om een extra bewijsbron toe te voegen. In de praktijk zou een bedrijf of academische groep die een nieuw kankergeneesmiddel ontwikkelt een klein aantal tumortypen kunnen invoeren waarvoor al sterk bewijs van werkzaamheid bestaat. INSPIRE zou dan de real-world datakaart gebruiken om andere kankersubtypen te markeren die er vergelijkbaar uitzien wat betreft hoe patiënten zich presenteren, hoe de ziekte vordert en hoe ze worden behandeld. Die indicaties kunnen worden geprioriteerd voor verder biologisch onderzoek en uiteindelijk voor klinische proeven. Door de kans te vergroten de juiste kankers te kiezen om eerst te testen, kunnen benaderingen zoals INSPIRE ontwikkeltijden verkorten, kosten verlagen en patiënten eerder toegang geven tot effectieve therapieën.
Bronvermelding: Eckhoff, M., Klingelschmitt, S., Van Ruijssevelt, L. et al. Finding the most promising indications for novel treatments in oncology. npj Precis. Onc. 10, 135 (2026). https://doi.org/10.1038/s41698-026-01352-x
Trefwoorden: ontwikkeling van kanker geneesmiddelen, real-world data, machine learning in oncologie, immunotherapie, selectie van behandelindicaties