Clear Sky Science · zh
使用与知识图谱集成的图卷积网络进行语法错误诊断
更智能的语法工具为何重要
任何见过文字处理软件在句子下划线的人都知道,自动语法检查器远非完美。它们常常漏掉微妙的错误,而且在提出修改建议时很少解释原因。本文介绍了一种新的语法诊断系统,设计目标不仅是修正英语写作中的错误,还要展示这些修正背后的推理——使其对学生、教师以及任何作为第二语言学习或使用英语的人更有用。
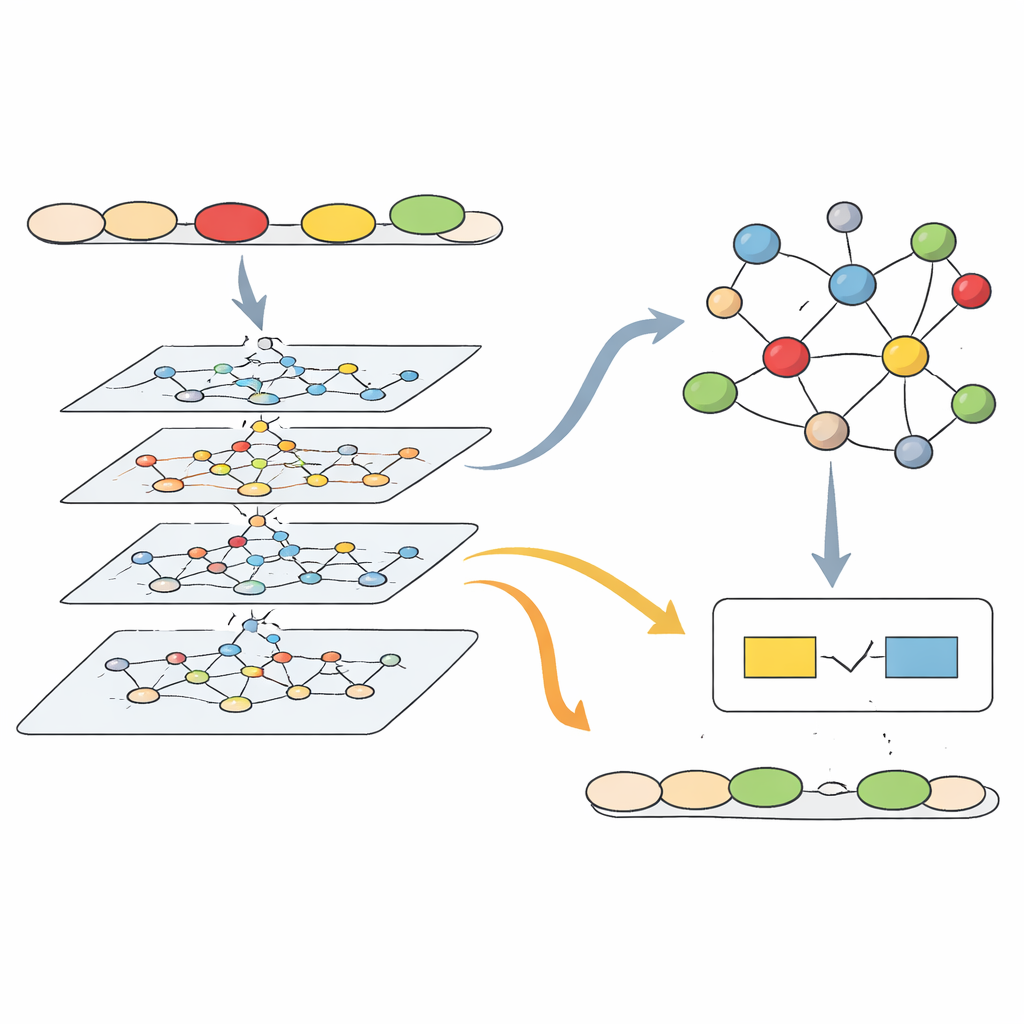
将句子转为网络结构
大多数现有语法工具把文本当作一行平铺的单词来处理。作者认为这太浅显,因为真实句子具有结构:主语与动词相连,分句彼此依附,意义取决于谁与谁有关联。他们的系统采用了现代人工智能中的一种技术——图卷积网络。它不是把句子当作平坦的字符串,而是将每个句子转换为一个小网络,每个单词为一个点,点与点之间的连线捕捉诸如“主语”为何或“宾语”为何等语法关系。模型随后在这个网络上逐层传播信息,使得每个单词的表示不仅受邻近词影响,还受与其在语法上有关联的远端单词影响,即便这些词在句子中相距甚远。
构建语法知识地图
在这个句子网络之上,研究者构建了第二个结构:大型语法知识图谱。这类似于一张精心组织的英语语法地图,由经典参考书、考试指南和教育资源拼接而成。它包含数千个“节点”,代表诸如动词时态、冠词使用或主谓一致等概念,以及表示常见错误类型、诊断规则、纠正策略和练习材料链接的独立节点。连边编码了诸如“该规则检测此错误”或“该策略可修复该问题”之类的关系。专家们对这些连边进行了检查和细化,使得图谱反映教师在课堂上实际思考语法问题的方式。
让数据与规则协同工作
当系统分析一个新句子时,它首先构建句子网络并运行图模型,以检测哪些词可能有误以及它们代表何种错误。与此同时,它会在语法知识图谱中查找相关条目——例如,将像“yesterday”这样的表过去时间的词与需要使用过去时动词的规则相连接。模型将从数据中“学到”的内容与存储在规则地图中的知识融合。网络中的箭头突出显示了哪些连接和规则最具影响力,从而允许系统追溯从具体错误到其所违背原理的路径。在测试中,这种结合方法在捕捉诸如动词时态变化和主谓不一致等依赖句内长距离联系的结构性问题上表现尤为出色。
系统测试情况
作者在广泛使用的学习者英语语料集上评估了他们的方法,包括 CoNLL-2014、JFLEG 和 BEA-2019。这些数据集包含学习英语者的作文,并由人工标注者标出每个句子错误的地点和类型。与基于变换器模型(如 BERT)和专用标注器(如 GECToR)等强基线系统相比,这种基于图的方法取得了更高的 F1 分数——这一标准衡量了尽可能多地发现真实错误与避免误报之间的平衡。重要的是,它在模型参数远少于这些大型模型的情况下达到了这一结果,这表明显式结构和语法知识可以在某种程度上替代原始规模。对大学学习者进行的小型课堂风格研究进一步暗示,基于知识图谱的解释有助于学生提高发现和理解错误的能力,但作者强调需要更大规模和更长期的研究来验证这一点。
对日常写作者的意义
简而言之,论文表明,当语法检查器将句子视为关系网络并查阅有组织的语法规则地图,而不是仅依赖模式匹配时,它们会变得更准确也更具有教育意义。所提出的系统不仅能标出问题所在,还能指回所违背的基本规则——例如“复数主语需要复数动词”——并建议有针对性的修正。尽管该方法在细微的用词选择、习语和极其噪声的句子上仍有困难,但它朝着让语言工具更像耐心教师而非生硬红笔的方向迈出了一步。随着进一步发展,类似的基于图的系统可能通过将现代人工智能的优势与显式、可读的语法知识相结合,支持多种语言的学习者。
引用: Zhang, J., Ma, Y. Grammar error diagnosis using graph convolutional networks with knowledge graph integration. Sci Rep 16, 10867 (2026). https://doi.org/10.1038/s41598-026-45622-x
关键词: 语法错误纠正, 图神经网络, 知识图谱, 语言学习技术, 自然语言处理