Clear Sky Science · nl
Diagnose van grammaticafouten met grafconvolutionele netwerken en integratie van kennismodellen
Waarom slimere grammaticatools ertoe doen
Wie wel eens een tekstverwerker heeft zien onderstrepen weet dat automatische grammaticacontrolers verre van perfect zijn. Ze missen vaak subtiele fouten en wanneer ze wel een wijziging voorstellen, leggen ze zelden uit waarom. Dit artikel introduceert een nieuw type grammaticadiagnosesysteem dat niet alleen fouten in Engelstalig schrijven corrigeert, maar ook de redenering achter die correcties toont—waardoor het nuttiger wordt voor studenten, docenten en iedereen die Engels als tweede taal leert of gebruikt.
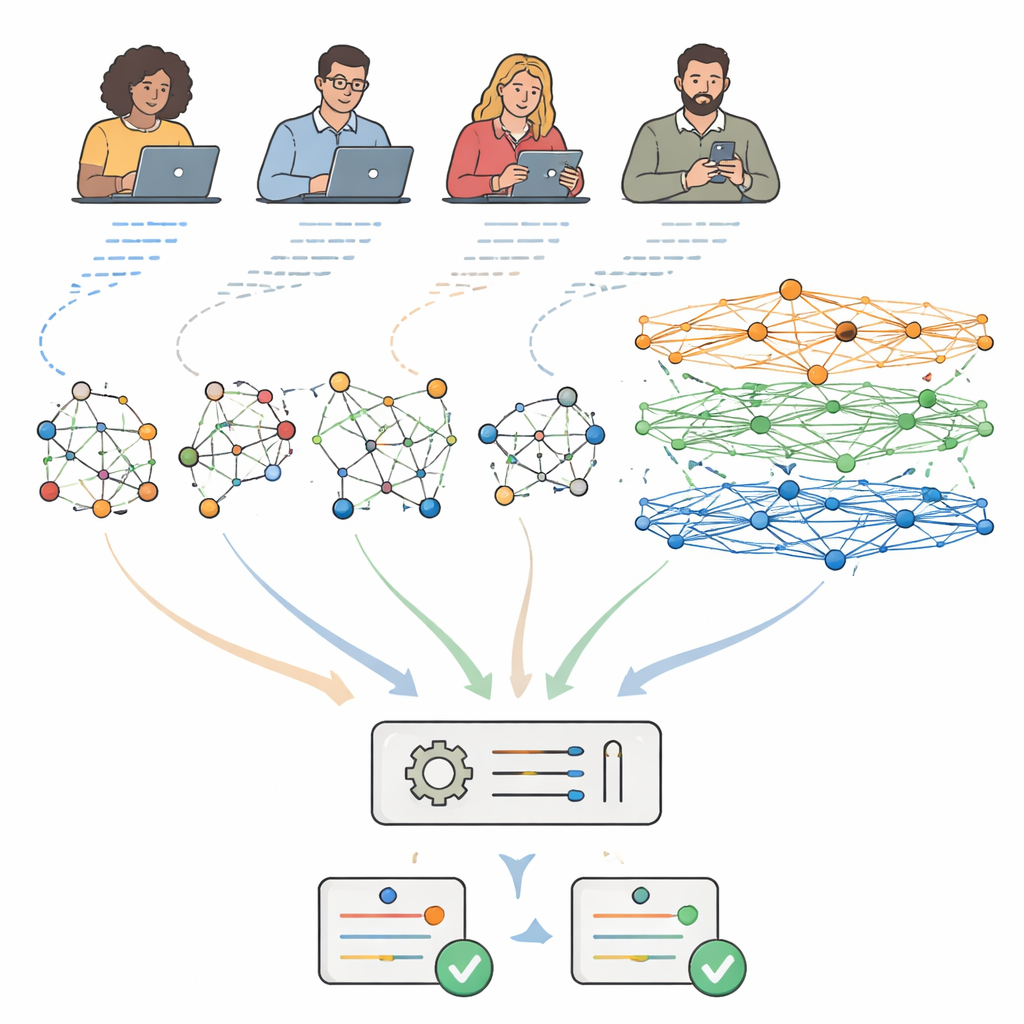
Zinnen omzetten in netwerken
De meeste huidige grammatica-instrumenten lezen tekst als een eenvoudige rij woorden. De auteurs betogen dat dat te vlak is, omdat echte zinnen structuur hebben: onderwerpen verbinden zich met werkwoorden, bijzinnen hangen samen en betekenis hangt af van wie met wat verbonden is. Hun systeem gebruikt een techniek uit moderne kunstmatige intelligentie, een graph convolutional network. In plaats van een zin als een platte reeks te behandelen, verandert het elke zin in een klein netwerk waarin elk woord een knooppunt is en lijnen tussen knooppunten grammaticale relaties vastleggen, zoals “onderwerp van” of “lijdend voorwerp van.” Het model spreidt vervolgens informatie door dit netwerk laag voor laag, zodat de representatie van elk woord wordt gevormd niet alleen door naburige woorden, maar ook door de woorden waarmee het grammaticaal verbonden is, zelfs als die ver in de zin staan.
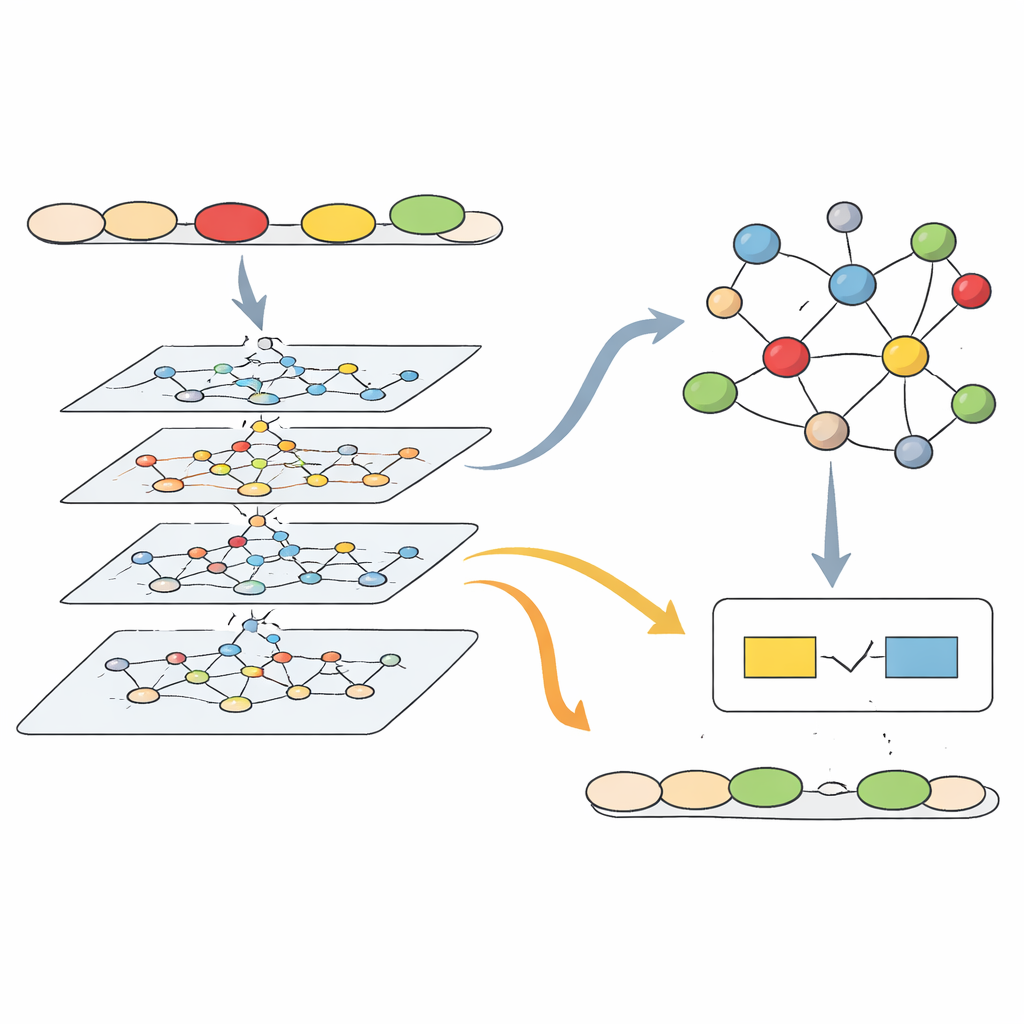
Een kaart van grammaticale kennis bouwen
Bovenop dit zinsnetwerk bouwen de onderzoekers een tweede structuur: een omvangrijke grammatica-kennisgraaf. Dit is als een zorgvuldig georganiseerde kaart van de Engelse grammatica, samengesteld uit klassieke naslagwerken, examenrichtlijnen en educatieve bronnen. Hij bevat duizenden knopen voor concepten zoals werkwoordstijd, gebruik van lidwoorden of onderwerp–werkwoordovereenstemming, plus aparte knopen voor veelvoorkomende fouttypes, diagnostische regels, correctiestrategieën en verwijzingen naar oefenmateriaal. De verbindingen coderen relaties zoals “deze regel detecteert die fout” of “deze strategie lost dat probleem op.” Experts hebben deze verbindingen gecontroleerd en verfijnd zodat de graaf weerspiegelt hoe docenten daadwerkelijk over grammaticale problemen denken in de klas.
Laten samenwerken: data en regels
Wanneer het systeem een nieuwe zin analyseert, bouwt het eerst het zinsnetwerk en voert het grafmodel uit om te detecteren welke woorden mogelijk verkeerd zijn en welk soort fout ze vertegenwoordigen. Tegelijk zoekt het gerelateerde items op in de grammatica-kennisgraaf—bijvoorbeeld regels die een woord als “yesterday” koppelen aan de noodzaak van een werkwoord in de verleden tijd. Het model mengt wat het uit data “leert” met wat in deze regelkaart is opgeslagen. Pijlen in het netwerk benadrukken welke verbindingen en regels het meest invloedrijk waren, waardoor het systeem een pad kan traceren van een concrete fout terug naar het principe dat wordt geschonden. In tests was deze gecombineerde aanpak vooral sterk in het opvangen van structurele problemen zoals verschuivingen in werkwoordstijd en onderwerp–werkwoordanoneenkomsten, die afhankelijk zijn van langafstandsverbindingen binnen een zin.
Het systeem op de proef stellen
De auteurs evalueerden hun methode op veelgebruikte verzamelingen van Engels door taalstudenten, waaronder CoNLL-2014, JFLEG en BEA-2019. Deze datasets bevatten essays van mensen die Engels leren, met menselijke annotatoren die markeren waar en hoe elke zin fout gaat. Vergeleken met sterke bestaande systemen gebaseerd op transformermodellen zoals BERT en gespecialiseerde taggers zoals GECToR behaalde het nieuwe grafgebaseerde systeem hogere F1-scores—een gebruikelijke maat die het balanceren van het vinden van zoveel mogelijk echte fouten en het vermijden van valse alarmen weerspiegelt. Belangrijk is dat het dat deed met veel minder modelparameters, wat suggereert dat expliciete structuur en grammaticakennis een alternatief kunnen bieden voor brute modelgrootte. Een kleine klasonderzoek met universitaire studenten toonde bovendien aan dat uitleg die gebaseerd is op de kennisgraaf studenten leek te helpen hun vermogen om fouten te herkennen en te begrijpen te verbeteren, hoewel de auteurs benadrukken dat grotere en langere studies nodig zijn.
Wat dit betekent voor alledaagse schrijvers
Kort gezegd laat het artikel zien dat grammaticacontroles nauwkeuriger en educatiever worden wanneer ze zinnen “zien” als netwerken van relaties en een georganiseerde kaart van grammaticaregels raadplegen, in plaats van alleen op patroonherkenning te leunen. Het voorgestelde systeem markeert niet alleen dat er iets mis is, maar kan ook terugverwijzen naar de onderliggende regel—zoals “meervoudige onderwerpen vragen om meervoudige werkwoorden”—en een gerichte correctie voorstellen. Hoewel de aanpak nog moeite heeft met genuanceerde woordkeuze, idiomen en zeer rommelige zinnen, is het een stap richting taalhulpmiddelen die meer als een geduldige docent handelen dan als een botte rode pen. Met verdere ontwikkeling zouden soortgelijke grafgebaseerde systemen leerlingen van veel talen kunnen ondersteunen door de sterke punten van moderne AI te combineren met expliciete, voor mensen leesbare grammaticale kennis.
Bronvermelding: Zhang, J., Ma, Y. Grammar error diagnosis using graph convolutional networks with knowledge graph integration. Sci Rep 16, 10867 (2026). https://doi.org/10.1038/s41598-026-45622-x
Trefwoorden: grammaticafoutcorrectie, graph neural networks, kennisgrafen, taalleertechnologie, verwerking van natuurlijke taal