Clear Sky Science · ru
Диагностика грамматических ошибок с помощью графовых сверточных сетей с интеграцией графа знаний
Почему важны более «умные» средства проверки грамматики
Кто сталкивался с тем, как текстовый редактор подчеркивает предложения, знает: автоматические проверяющие грамматику далеки от совершенства. Они часто пропускают тонкие ошибки, и когда предлагают исправление, редко объясняют, почему. В этой статье представлен новый тип системы для диагностики грамматики, задуманный не только для исправления ошибок в английской письменности, но и для демонстрации рассуждений, стоящих за этими исправлениями — что делает её более полезной для студентов, преподавателей и всех, кто учит или использует английский как второй язык.
Преобразование предложений в сети
Большинство современных инструментов для проверки грамматики воспринимают текст как простую последовательность слов. Авторы утверждают, что это слишком поверхностно, потому что в реальных предложениях есть структура: подлежащее связано с глаголом, части предложения сгруппированы, а смысл зависит от того, кто с кем связан. Их система использует приём из современной искусственной intelligence — графовую сверточную сеть. Вместо того чтобы рассматривать предложение как плоскую строку, она превращает каждое предложение в маленькую сеть, где каждое слово — это узел, а связи между узлами фиксируют грамматические отношения, такие как «подлежащее у» или «дополнение у». Модель затем распространяет информацию по этой сети слой за слоем, так что представление каждого слова формируется не только за счёт соседних слов, но и за счёт тех слов, с которыми оно грамматически связано, даже если они находятся далеко друг от друга в предложении.
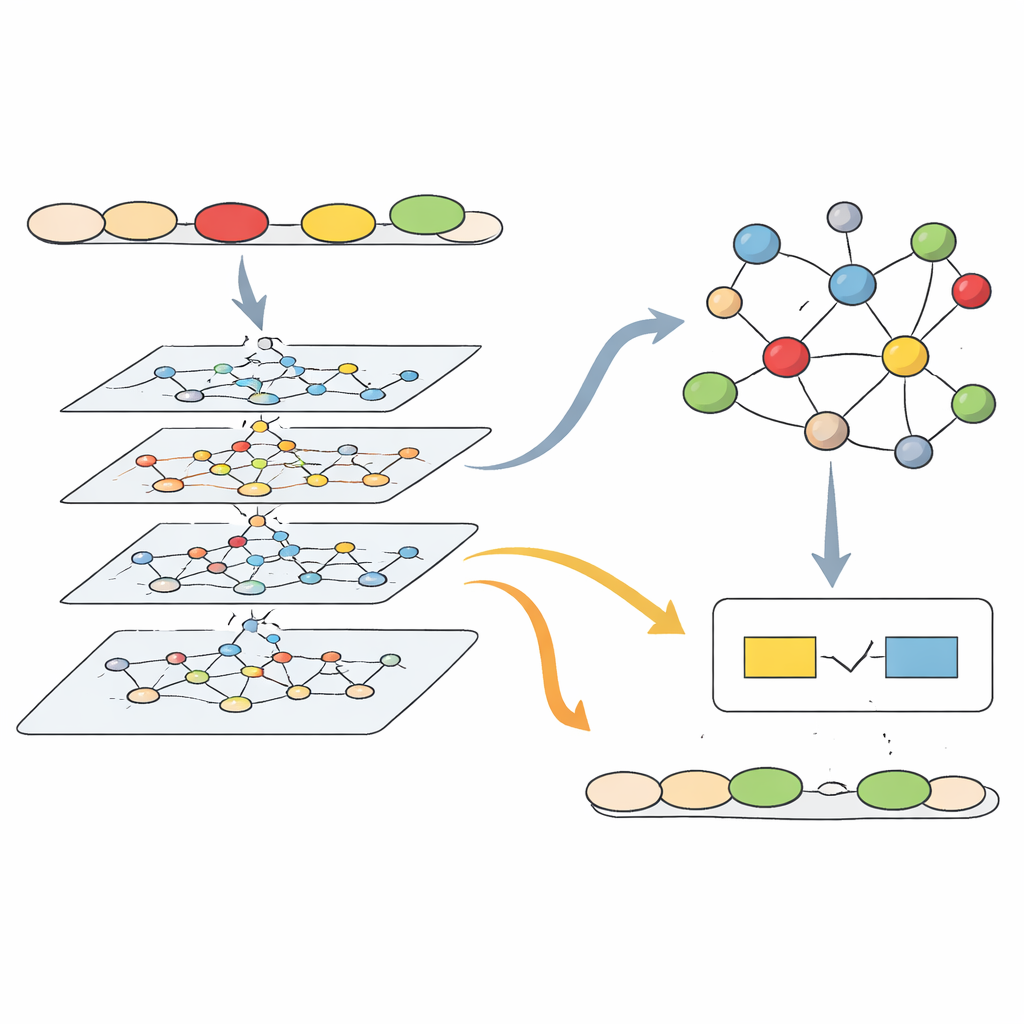
Построение карты грамматических знаний
Поверх сети предложения исследователи создают вторую структуру: крупный грамматический граф знаний. Это как тщательно организованная карта английской грамматики, собранная из классических справочников, экзаменационных руководств и образовательных ресурсов. Она содержит тысячи «узлов» для таких понятий, как время глагола, употребление артикля или согласование подлежащего и сказуемого, а также отдельные узлы для распространённых типов ошибок, диагностических правил, стратегий исправления и ссылок на практические материалы. Связи кодируют отношения вроде «это правило обнаруживает эту ошибку» или «эта стратегия исправляет эту проблему». Эксперты проверяли и уточняли эти связи, чтобы граф отражал то, как преподаватели реально мыслят о грамматических проблемах в классе.
Позволяя данным и правилам работать вместе
Когда система анализирует новое предложение, она сначала строит сеть предложения и прогоняет графовую модель, чтобы определить, какие слова могут быть неверными и к какому типу ошибки они относятся. Одновременно она обращается к связанным записям в грамматическом графе знаний — например, к правилам, которые связывают слово, указывающее на прошедшее время, вроде «yesterday», с необходимостью употребления глагола в прошедшем времени. Модель сочетает то, чему она «учится» по данным, с тем, что содержится в этой карте правил. Стрелки в сети выделяют связи и правила, которые оказали наибольшее влияние, позволяя системе проследить путь от конкретной ошибки к принципу, который нарушен. В тестах такой комбинированный подход показал особую эффективность в выявлении структурных проблем, например смен времени глаголов и несоответствий подлежащее—сказуемое, которые зависят от дальних связей внутри предложения.
Проверка системы в деле
Авторы оценивали свой метод на общепринятых корпусах текстов учащихся английского языка, включая CoNLL-2014, JFLEG и BEA-2019. Эти наборы содержат эссе учащихся, где аннотаторы-человеки отмечают, где и в чём ошибки в предложениях. По сравнению с сильными существующими системами на базе трансформеров, такими как BERT, и специализированными теггерами вроде GECToR, новая графовая система достигла более высоких F1-показателей — стандартной метрики, которая уравновешивает задачу обнаружения как можно большего числа реальных ошибок и избегания ложных срабатываний. Важно, что она добилась этого при существенно меньшем числе параметров модели, что указывает на то, что явная структура и грамматические знания могут заменить чистую масштабность. Небольшое исследование в условиях класса с университетскими студентами также показало, что объяснения, основанные на графе знаний, помогли учащимся лучше замечать и понимать ошибки, хотя авторы подчёркивают, что нужны более крупные и длительные исследования.
Что это значит для повседневных авторов
Проще говоря, статья показывает, что проверяющие грамматику становятся точнее и более обучающими, когда они «видят» предложения как сети отношений и обращаются к организованной карте грамматических правил, вместо того чтобы опираться только на сопоставление шаблонов. Предложенная система не только отмечает, что что-то неверно, но и может ссылаться на базовое правило — например «множественное подлежащее требует множественной формы глагола» — и предложить целенаправленное исправление. Хотя подход по-прежнему испытывает трудности с тонким выбором слов, идиомами и очень шумными предложениями, он делает шаг к языковым инструментам, которые ведут себя скорее как терпеливый преподаватель, чем как грубое красное перо. При дальнейшем развитии похожие графовые системы могли бы поддерживать изучающих многие языки, сочетая сильные стороны современной ИИ с явными, удобочитаемыми грамматическими знаниями.
Цитирование: Zhang, J., Ma, Y. Grammar error diagnosis using graph convolutional networks with knowledge graph integration. Sci Rep 16, 10867 (2026). https://doi.org/10.1038/s41598-026-45622-x
Ключевые слова: коррекция грамматических ошибок, графовые нейронные сети, графы знаний, технологии изучения языка, обработка естественного языка