Clear Sky Science · de
Diagnose von Grammatikfehlern mithilfe von Graph-Convolutional-Netzwerken mit Integration eines Wissensgraphen
Warum intelligentere Grammatik-Tools wichtig sind
Wer schon einmal zugesehen hat, wie ein Textverarbeitungsprogramm Sätze unterkringelt, weiß, dass automatische Grammatikprüfer weit davon entfernt sind, perfekt zu sein. Sie übersehen oft subtile Fehler, und wenn sie eine Änderung vorschlagen, erklären sie selten, warum. Dieses Paper stellt ein neues Diagnoseverfahren für Grammatikfehler vor, das nicht nur Fehler im Englischen korrigiert, sondern auch die zugrunde liegende Begründung für diese Korrekturen zeigt — wodurch es für Lernende, Lehrende und alle, die Englisch als Zweitsprache verwenden, nützlicher wird.
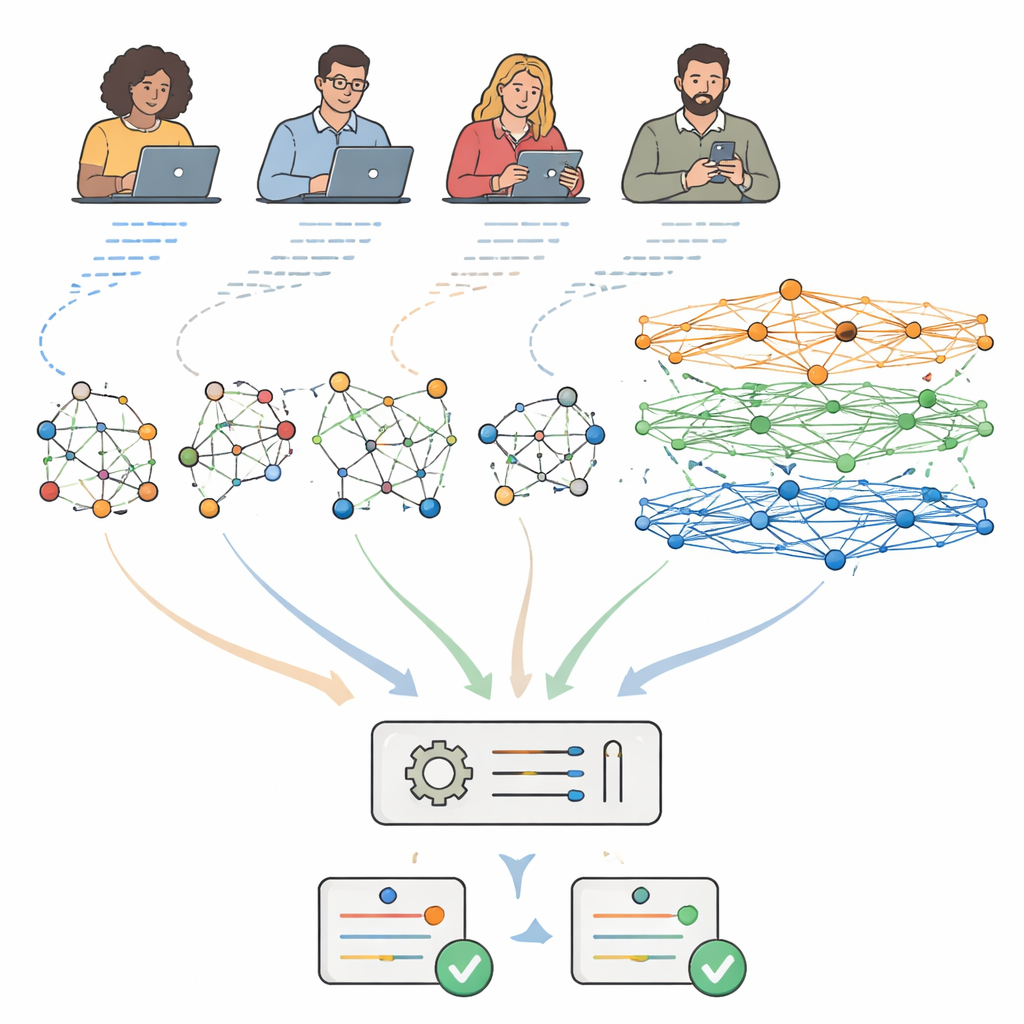
Sätze in Netzwerke verwandeln
Die meisten aktuellen Grammatikwerkzeuge lesen Text als einfache Wortfolge. Die Autoren argumentieren, dass das zu oberflächlich ist, weil echte Sätze Struktur haben: Subjekte stehen zu Verben in Beziehung, Nebensätze hängen zusammen und die Bedeutung hängt davon ab, wer womit verknüpft ist. Ihr System verwendet eine Technik aus der modernen Künstlichen Intelligenz namens Graph-Convolutional-Network. Anstatt einen Satz als flache Zeichenkette zu behandeln, wandelt es jeden Satz in ein kleines Netzwerk um, in dem jedes Wort ein Punkt ist und Linien zwischen Punkten grammatische Beziehungen wie „Subjekt von“ oder „Objekt von“ abbilden. Das Modell verteilt dann Informationen schichtweise über dieses Netzwerk, sodass die Repräsentation jedes Wortes nicht nur von seinen Nachbarn, sondern auch von den Wörtern geprägt wird, zu denen es grammatisch verbunden ist — selbst wenn diese weit entfernt im Satz stehen.
Einen Wissensatlas der Grammatik aufbauen
Auf dieses Satznetzwerk setzen die Forschenden eine zweite Struktur: einen großen Grammatik-Wissensgraphen. Das ist wie eine sorgfältig organisierte Landkarte der englischen Grammatik, zusammengesetzt aus klassischen Nachschlagewerken, Prüfungsrichtlinien und Bildungsressourcen. Er enthält tausende „Knoten“ für Konzepte wie Tempus, Artikelgebrauch oder Subjekt‑Verb‑Übereinstimmung sowie separate Knoten für häufige Fehlertypen, Diagnose-Regeln, Korrekturstrategien und Verweise auf Übungsmaterialien. Die Verbindungen kodieren Beziehungen wie „diese Regel erkennt diesen Fehler“ oder „diese Strategie behebt dieses Problem“. Expertinnen und Experten überprüften und verfeinerten diese Verknüpfungen, sodass der Graph widerspiegelt, wie Lehrende tatsächlich über Grammatikprobleme im Unterricht denken.
Daten und Regeln zusammenwirken lassen
Wenn das System einen neuen Satz analysiert, baut es zunächst das Satznetzwerk auf und lässt das Graphmodell laufen, um zu erkennen, welche Wörter möglicherweise falsch sind und um welchen Fehlertyp es sich handelt. Gleichzeitig sucht es im Grammatik-Wissensgraphen nach verwandten Einträgen — zum Beispiel Regeln, die ein wortbezogenes Signal wie „yesterday“ mit der Notwendigkeit eines Verbs im Präteritum verbinden. Das Modell mischt, was es aus Daten «gelernt» hat, mit dem, was in dieser Regelkarte gespeichert ist. Pfeile im Netzwerk heben jene Verbindungen und Regeln hervor, die am einflussreichsten waren, sodass das System einen Pfad von einem konkreten Fehler zurück zu dem Prinzip nachzeichnen kann, das verletzt wurde. In Tests war dieser kombinierte Ansatz besonders stark beim Erfassen struktureller Probleme wie Tempuswechseln und Subjekt‑Verb‑Übereinstimmungsfehlern, die auf langreichweitige Verbindungen innerhalb eines Satzes angewiesen sind.
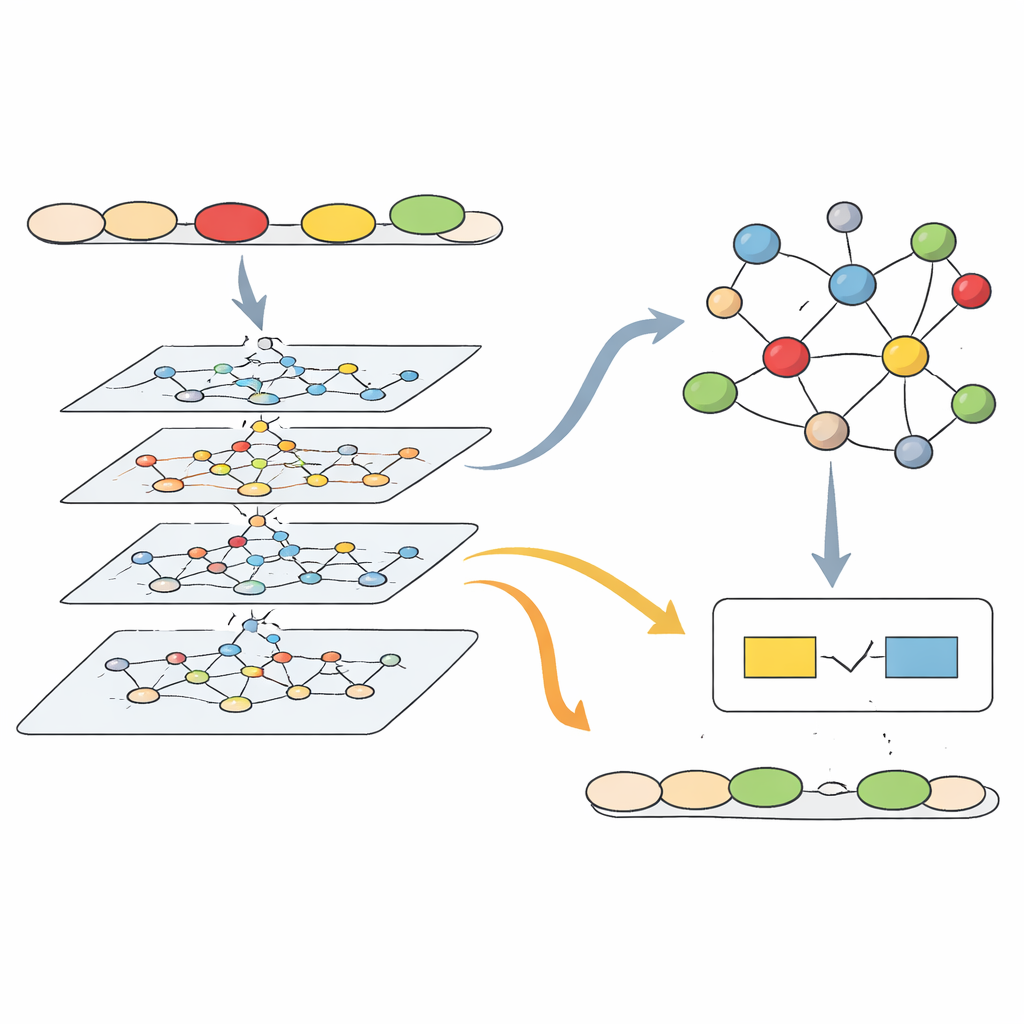
Das System auf die Probe stellen
Die Autoren evaluierten ihre Methode an häufig genutzten Sammlungen von Englischlernertexten, darunter CoNLL-2014, JFLEG und BEA-2019. Diese Datensätze enthalten Essays von Personen, die Englisch lernen, wobei menschliche Annotatorinnen und Annotatoren markieren, wo und wie jeder Satz fehlerhaft ist. Verglichen mit starken bestehenden Systemen, die auf Transformer-Modellen wie BERT und spezialisierten Taggern wie GECToR basieren, erzielte das neue graphbasierte System höhere F1-Werte — ein gängiges Maß, das das Erkennen möglichst vieler echter Fehler mit dem Vermeiden von Fehlalarmen ausbalanciert. Wichtig ist, dass es dies mit deutlich weniger Modellparametern erreichte, was darauf hindeutet, dass explizite Struktur und Grammatikwissen die rohe Modellgröße teilweise ersetzen können. Eine kleine, klassenähnliche Studie mit Hochschulstudierenden deutete außerdem an, dass Erklärungen, die im Wissensgraphen verankert sind, den Lernenden halfen, Fehler besser zu erkennen und zu verstehen, auch wenn die Autoren betonen, dass größere und längere Studien nötig sind.
Was das für alltägliche Schreiber bedeutet
Einfach gesagt zeigt das Paper, dass Grammatikprüfer genauer und lehrreicher werden, wenn sie Sätze als Netzwerke von Beziehungen „sehen“ und eine organisierte Regelkarte zu Rate ziehen, statt nur auf Mustererkennung zu setzen. Das vorgeschlagene System markiert nicht nur, dass etwas falsch ist, sondern kann auch auf die zugrunde liegende Regel verweisen — etwa „Plural‑Subjekte benötigen Plural‑Verben“ — und eine gezielte Korrektur vorschlagen. Während der Ansatz bei nuanciertem Wortgebrauch, Idiomen und sehr verrauschten Sätzen noch Schwierigkeiten hat, stellt er einen Schritt in Richtung Sprachwerkzeuge dar, die eher wie eine geduldige Lehrkraft als wie ein scharfes rotes Stift agieren. Bei weiterer Entwicklung könnten ähnliche graphbasierte Systeme Lernende vieler Sprachen unterstützen, indem sie die Stärken moderner KI mit explizitem, menschenlesbarem Grammatikwissen verbinden.
Zitation: Zhang, J., Ma, Y. Grammar error diagnosis using graph convolutional networks with knowledge graph integration. Sci Rep 16, 10867 (2026). https://doi.org/10.1038/s41598-026-45622-x
Schlüsselwörter: Korrektur von Grammatikfehlern, Graphneuronale Netze, Wissensgraphen, Technologie zum Spracherwerb, Verarbeitung natürlicher Sprache