Clear Sky Science · zh
用于乳腺癌早期治疗的可解释深度学习药物敏感性预测新方法
这项研究对患者的重要性
乳腺癌药物对不同个体的疗效存在差异。医生常常需要通过反复试验来找到合适的药物和剂量。本研究探索了人工智能如何从大量实验室数据中学习,预测乳腺癌细胞对多种药物的反应。未来,这类工具有望在更早阶段提供更个性化的治疗建议,同时加速新疗法的筛选。
教计算机识别药物反应模式
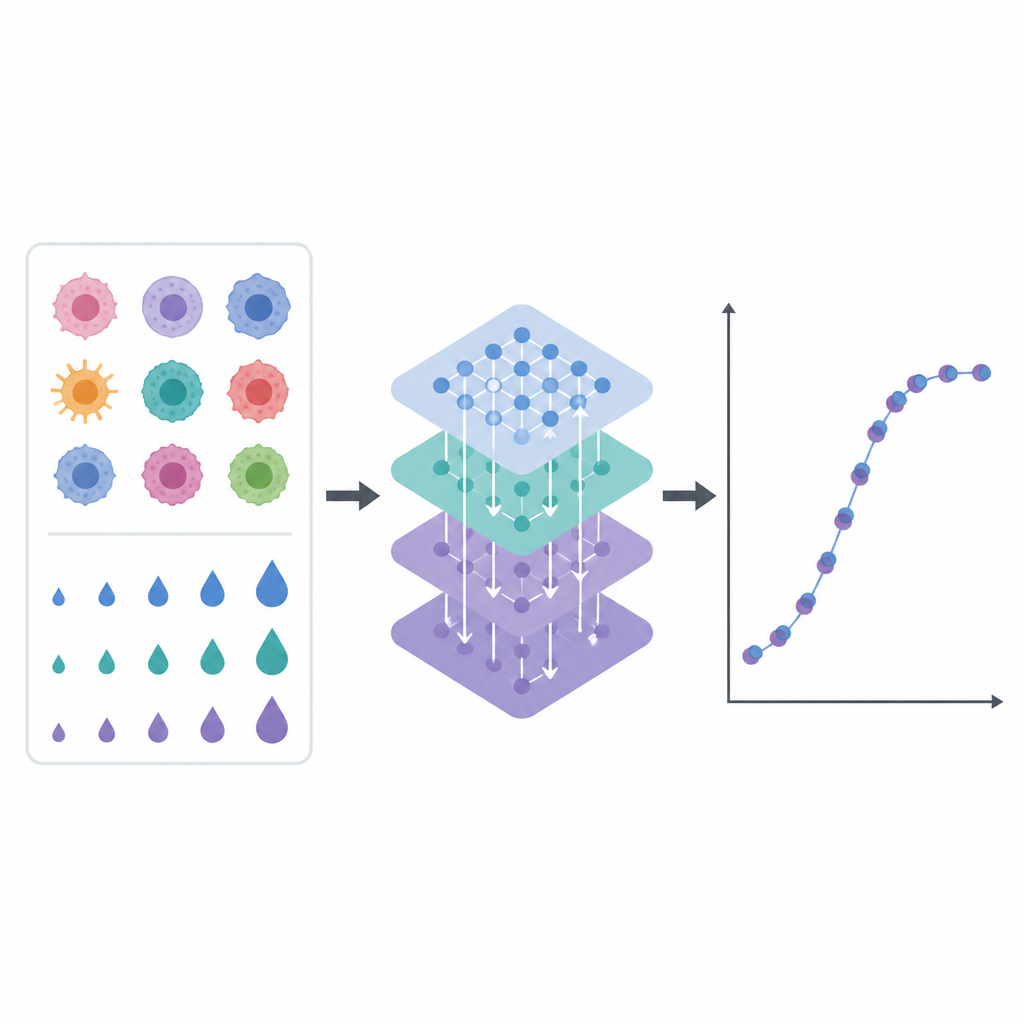
现代实验室可以在多种乳腺癌细胞系上测试数百种药物,记录每种药物在不同剂量下抑制细胞增殖的强度。结果是一个庞大的数值表格,肉眼难以解读。作者训练了一个计算机模型来读取这些模式,预测给定乳腺癌细胞系对特定药物和剂量的敏感性。他们的研究基于一套特别丰富的测量数据,涵盖数十个乳腺癌细胞系和一百多种药物化合物,每种在多个浓度水平下测试。
幕后:清洗与丰富数据
真实的实验数据往往杂乱无章。有些测量缺失,细胞系名称不一致,对同一药物的重复测试结果也可能不一致。团队构建了一个细致的数据处理管道来整理这些信息。他们在多个公共资源中匹配乳腺癌细胞系,统一药物名称和剂量,并对重复测量取平均以减少噪声。随后他们加入了基于时间的衍生特征,用于描述药物效应在相邻剂量处的变化,例如短期趋势和平滑平均。这些额外提示帮助模型理解剂量反应曲线,而不是将每个数据点孤立看待。
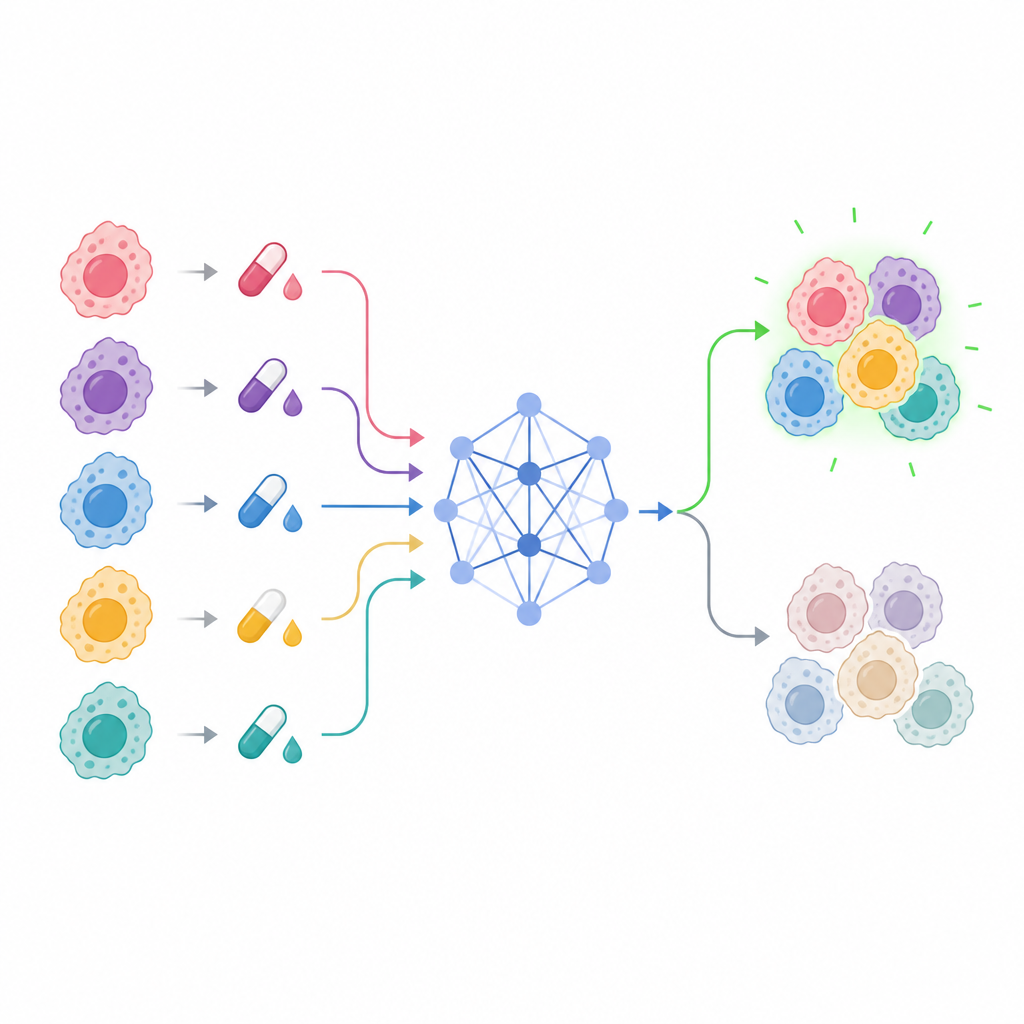
新模型如何从细胞与药物中学习
这项工作的核心是名为可解释药物图注意力变换器(Explainable Drug Graph Attention Transformer,EDrGAT)的模型。简而言之,它是一种将药物名称、癌细胞系和剂量共同考虑并学习它们相互作用的深度学习网络。模型将每种药物和每个细胞系表示为数值空间中的点,然后使用注意力机制聚焦于最有信息量的组合。模型还输入经工程化处理的剂量历史特征,以捕捉相邻浓度下反应的累积或平滑效应。通过这种方式,它能够估计即使在未直接测试的剂量水平上,乳腺癌细胞系可能的敏感性。
评估准确性并打开“黑盒”
为了评估EDrGAT的表现,作者在大部分数据上训练模型,然后在从未见过的药物-细胞系-剂量组合上进行测试。模型在该保留集上解释了近90%的药物敏感性变异,并明显优于几种现有方法,包括其他深度学习系统和更传统的机器学习方法。同样重要的是,团队分析了模型给出预测的原因。通过为每个输入特征分配影响分数的工具,他们发现近期的药物反应趋势和相邻剂量对预测的贡献最大,而细胞系和药物的身份则起到了较小但仍有意义的作用。若要将此类工具用于临床决策,这类透明性非常重要。
这对未来乳腺癌护理的意义
研究表明,基于大规模药物测试数据训练并经过细致数据处理的人工智能模型,能够对乳腺癌细胞对不同药物和剂量的反应给出准确且可解释的预测。尽管本工作基于细胞系数据而非直接的患者样本,但它指向了一个未来:医生可以使用类似模型缩小治疗选择范围,避免可能无效的药物,并更有把握地选择剂量水平。它也可能帮助研究人员优先推进哪些药物候选者进入后续开发,使更个性化的乳腺癌疗法更接近现实。
引用: Anushya, A., Alreshidi, A., Varshini, N.H. et al. Novel explainable deep learning based drug sensitivity prediction for early treatment of breast cancer. Sci Rep 16, 14833 (2026). https://doi.org/10.1038/s41598-026-44617-y
关键词: 乳腺癌, 药物敏感性, 深度学习, 精准肿瘤学, 药物基因组学