Clear Sky Science · en
Novel explainable deep learning based drug sensitivity prediction for early treatment of breast cancer
Why this research matters for patients
Breast cancer drugs do not work the same way for everyone. Doctors often must rely on trial and error to find the right medicine and dose. This study explores how artificial intelligence can learn from large collections of lab data to predict how breast cancer cells will respond to many different drugs. In the future, such tools could help guide earlier and more tailored treatment choices while also speeding up the search for new therapies.
Teaching computers to read drug response patterns
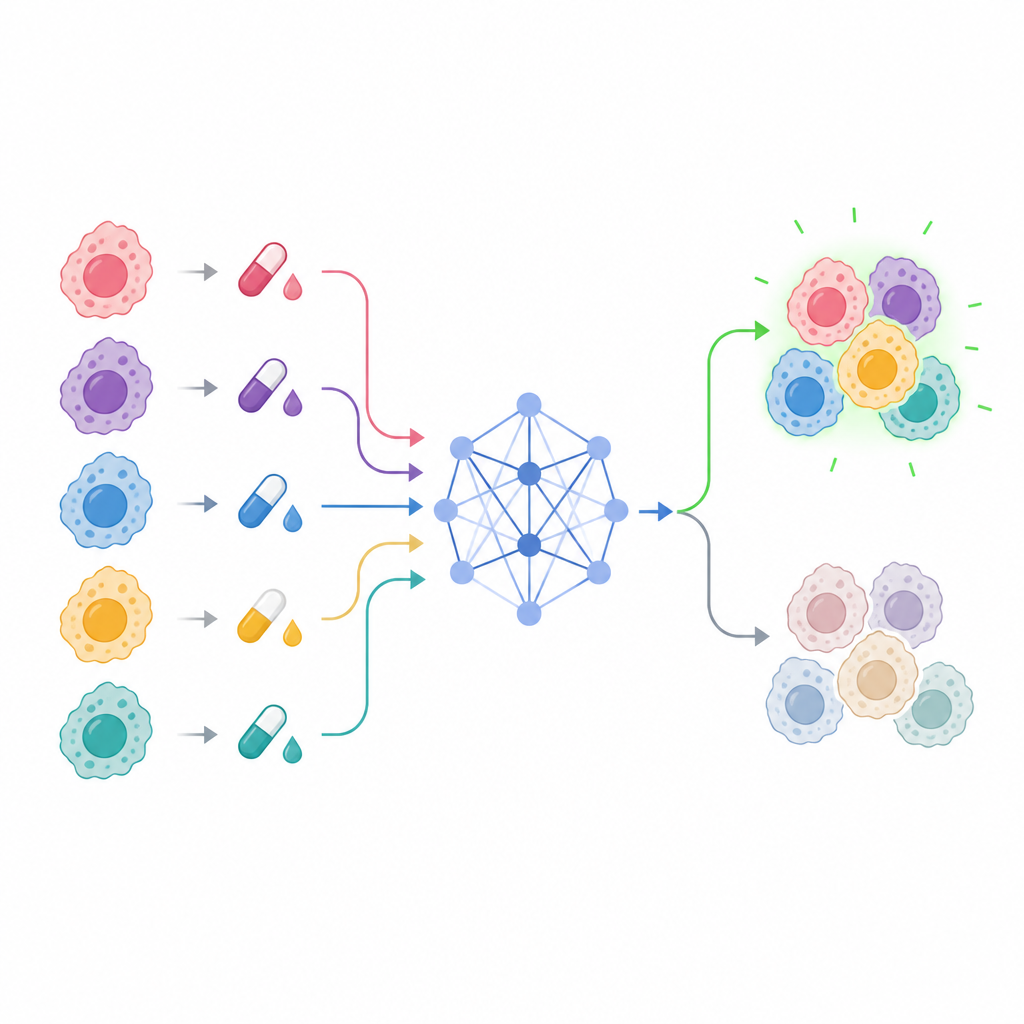
Modern labs can test hundreds of medicines across many breast cancer cell lines, recording how strongly each drug slows cell growth at different doses. The result is a huge table of numbers that is difficult for humans to interpret by eye. The authors trained a computer model to read these patterns and forecast how sensitive a given breast cancer cell line will be to a specific drug and dose. Their focus was on an especially rich resource of measurements from dozens of breast cancer cell lines and more than one hundred drug compounds, each tested at many concentration levels.
Cleaning and enriching the data behind the scenes
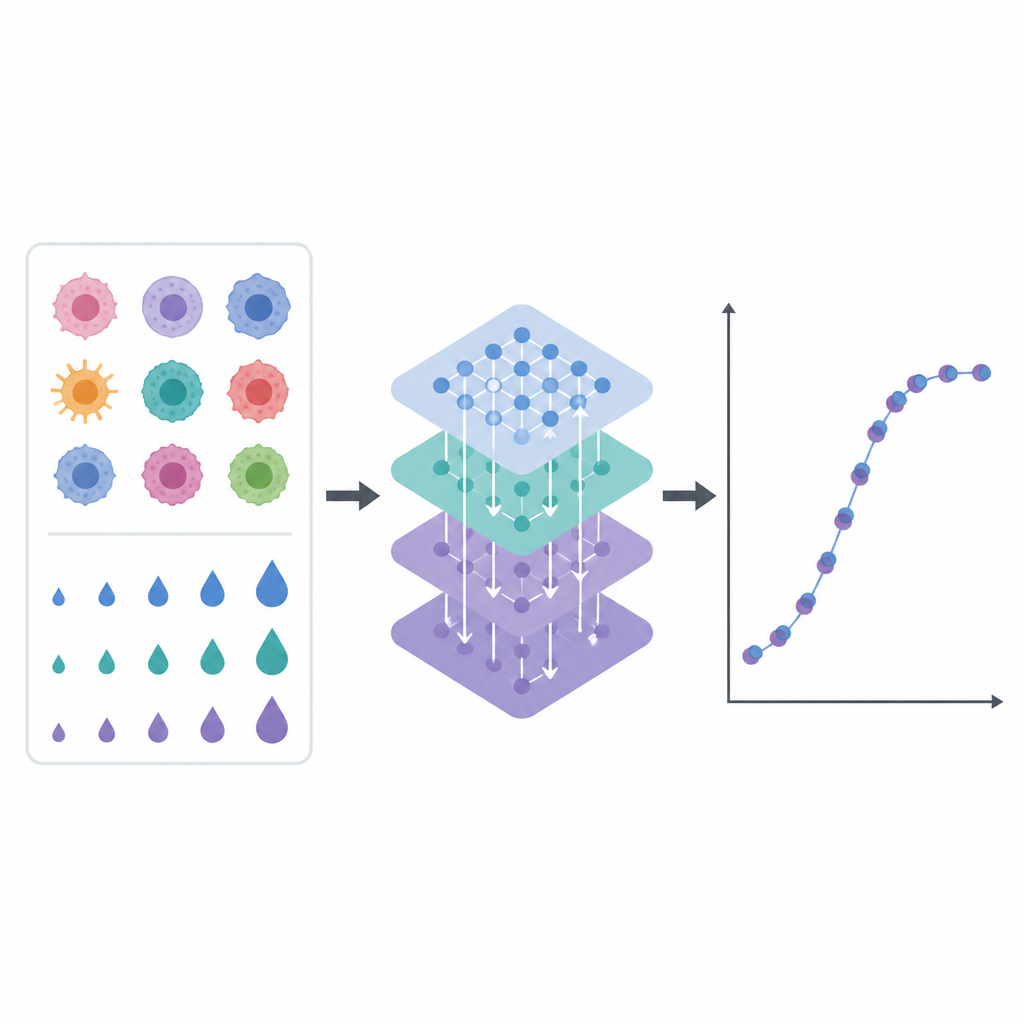
Real world lab data are messy. Some measurements are missing, cell line names can be inconsistent, and repeated tests of the same drug do not always agree. The team built a careful pipeline to tidy this information. They matched breast cancer cell lines across several public resources, unified drug names and doses, and averaged repeated measurements to reduce noise. They then added new time based features that describe how drug effects change with nearby doses, such as short term trends and smoothed averages. These extra hints help the computer model understand dose response curves rather than treating each data point in isolation.
How the new model learns from cells and drugs
At the heart of the work is a model called the Explainable Drug Graph Attention Transformer, or EDrGAT. In simpler terms, it is a type of deep learning network that looks at drug name, cancer cell line, and dose together and learns how they interact. It represents each drug and each cell line as a point in a numerical space and then uses an attention mechanism to focus on the most informative combinations. The model also takes in the engineered dose history features so it can capture how responses build up or smooth out across nearby concentrations. By doing this, it can estimate how sensitive a breast cancer cell line is likely to be even at dose levels that were never directly tested.
Checking accuracy and opening the black box
To see how well EDrGAT performs, the authors trained it on most of the data and then tested it on drug cell line dose pairs it had never seen before. The model explained close to 90 percent of the variation in drug sensitivity on this held out set and clearly outperformed several existing approaches, including other deep learning systems and more traditional machine learning methods. Just as important, the team examined why the model made its predictions. Using tools that assign influence scores to each input feature, they found that recent drug response trends and nearby doses played the largest role, while the identity of the cell line and drug contributed smaller but still meaningful effects. This sort of transparency is important if such tools are to support clinical decisions.
What this could mean for future breast cancer care
The study shows that an AI model, trained on large drug testing datasets and strengthened by careful data handling, can make accurate and explainable predictions about how breast cancer cells respond to different drugs and doses. While this work uses cell line data rather than direct patient samples, it points toward a future in which doctors could use similar models to narrow down treatment options, avoid likely ineffective drugs, and select dose levels more confidently. It may also help researchers prioritize which drug candidates to move forward in development, bringing more personalized breast cancer therapies closer to reality.
Citation: Anushya, A., Alreshidi, A., Varshini, N.H. et al. Novel explainable deep learning based drug sensitivity prediction for early treatment of breast cancer. Sci Rep 16, 14833 (2026). https://doi.org/10.1038/s41598-026-44617-y
Keywords: breast cancer, drug sensitivity, deep learning, precision oncology, pharmacogenomics