Clear Sky Science · fr
Nouvelle méthode explicable d'apprentissage profond pour prédire la sensibilité aux médicaments en traitement précoce du cancer du sein
Pourquoi cette recherche compte pour les patients
Les médicaments contre le cancer du sein n'ont pas la même efficacité pour tout le monde. Les médecins doivent souvent recourir à des essais et erreurs pour trouver le bon médicament et la bonne posologie. Cette étude examine comment l'intelligence artificielle peut apprendre à partir de vastes jeux de données de laboratoire pour prédire comment des cellules de cancer du sein réagiront à de nombreux médicaments différents. À l'avenir, de tels outils pourraient aider à orienter des choix thérapeutiques plus précoces et mieux adaptés tout en accélérant la découverte de nouvelles thérapies.
Apprendre aux ordinateurs à lire les schémas de réponse aux médicaments
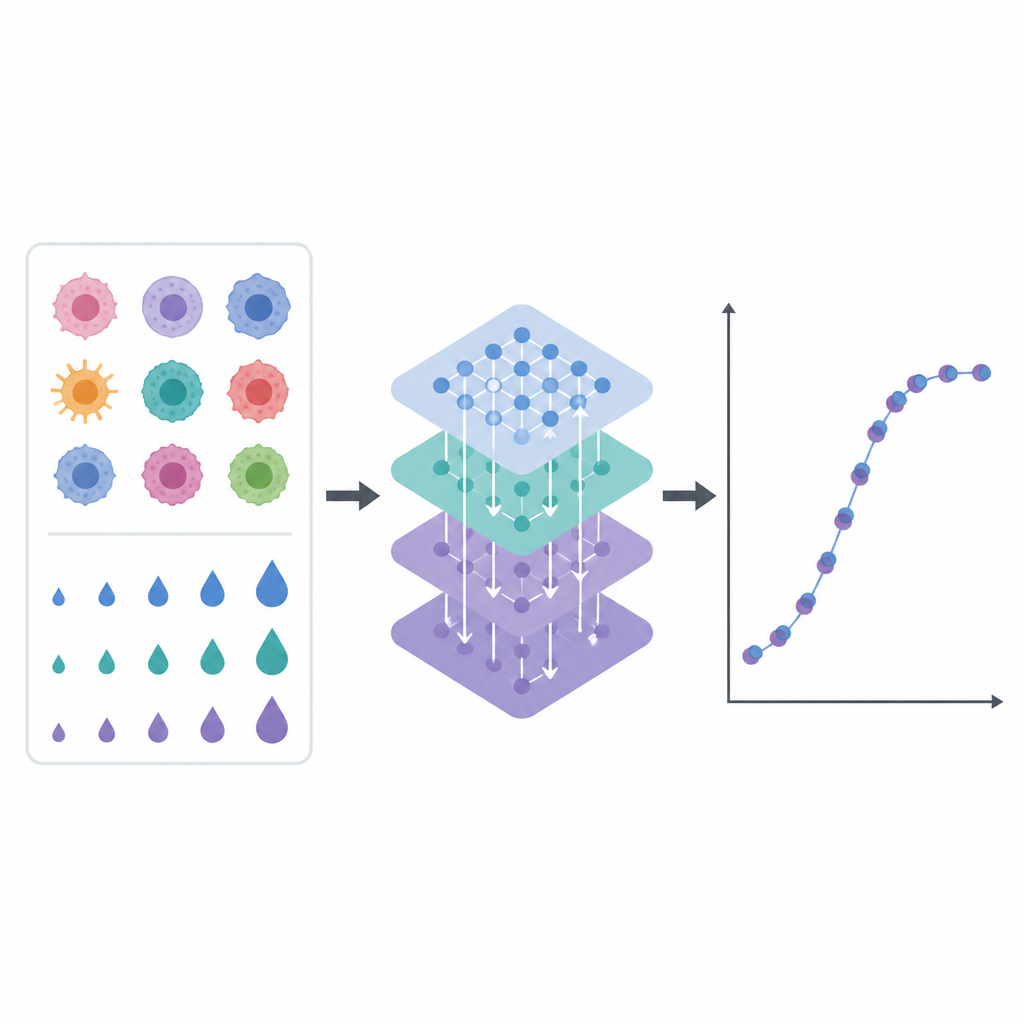
Les laboratoires modernes peuvent tester des centaines de médicaments sur de nombreuses lignées cellulaires du cancer du sein, en enregistrant dans quelle mesure chaque médicament ralentit la croissance cellulaire à différentes doses. Le résultat est un énorme tableau de chiffres difficile à interpréter visuellement. Les auteurs ont entraîné un modèle informatique à lire ces schémas et à prévoir la sensibilité d'une lignée cellulaire donnée à un médicament et à une dose spécifiques. Ils se sont appuyés sur une ressource particulièrement riche de mesures provenant de dizaines de lignées cellulaires du cancer du sein et de plus d'une centaine de composés médicamenteux, chacun testé à de nombreux niveaux de concentration.
Nettoyer et enrichir les données en coulisses
Les données de laboratoire du monde réel sont désordonnées. Certaines mesures sont manquantes, les noms des lignées cellulaires peuvent être incohérents et les répétitions d'un même test ne concordent pas toujours. L'équipe a développé une chaîne de traitement rigoureuse pour nettoyer ces informations. Ils ont rapproché les lignées cellulaires du cancer du sein entre plusieurs ressources publiques, unifié les noms des médicaments et des doses, et moyenné les mesures répétées pour réduire le bruit. Ils ont ensuite ajouté de nouvelles caractéristiques temporelles décrivant comment les effets des médicaments varient avec les doses proches, comme les tendances à court terme et les moyennes lissées. Ces indices supplémentaires aident le modèle informatique à comprendre les courbes de réponse aux doses au lieu de traiter chaque point de données isolément.
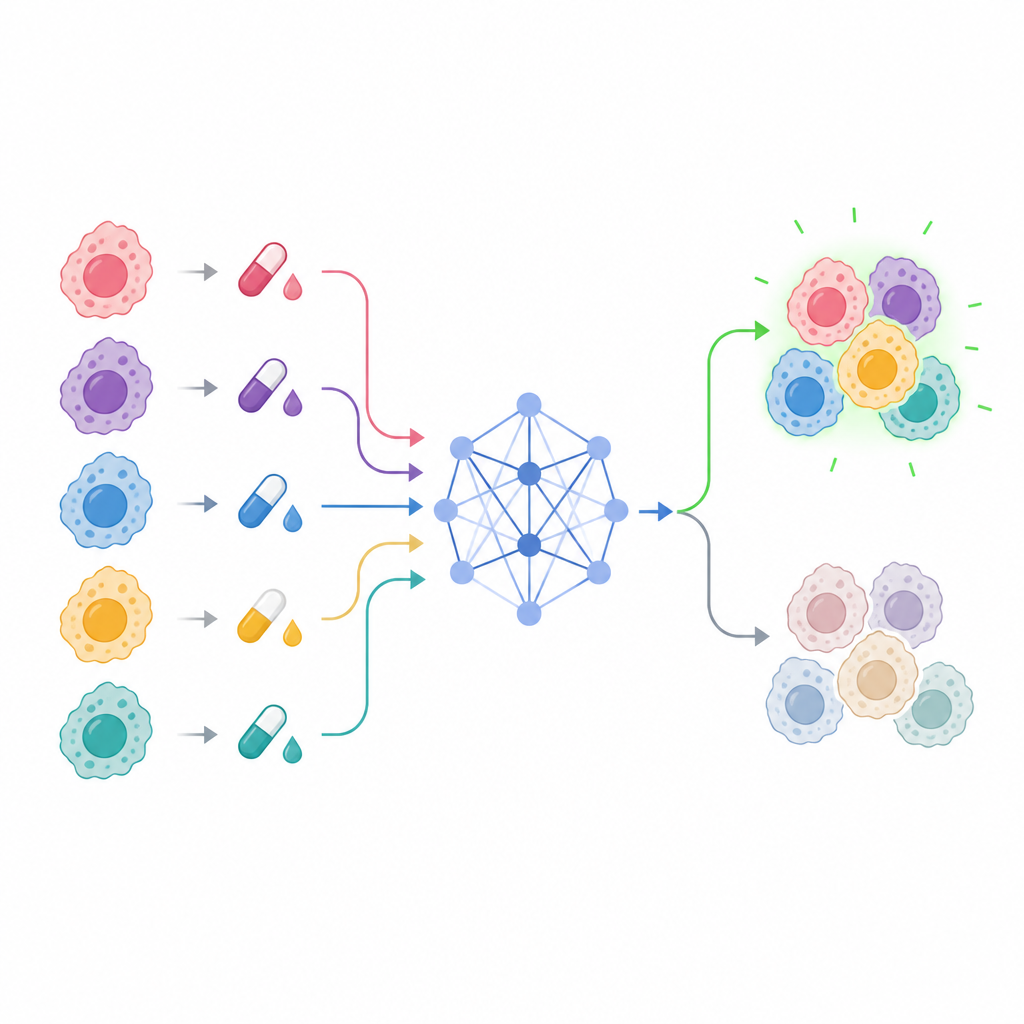
Comment le nouveau modèle apprend à partir des cellules et des médicaments
Le cœur du travail est un modèle nommé Explainable Drug Graph Attention Transformer, ou EDrGAT. En termes simples, il s'agit d'un type de réseau d'apprentissage profond qui considère ensemble le nom du médicament, la lignée cellulaire cancéreuse et la dose, et apprend leurs interactions. Il représente chaque médicament et chaque lignée cellulaire comme un point dans un espace numérique, puis utilise un mécanisme d'attention pour se concentrer sur les combinaisons les plus informatives. Le modèle intègre également les caractéristiques d'historique de dose conçues afin de capturer la façon dont les réponses s'accumulent ou se lissent à travers des concentrations proches. Ce faisant, il peut estimer la sensibilité probable d'une lignée cellulaire du cancer du sein même à des niveaux de dose qui n'ont jamais été testés directement.
Vérifier la précision et ouvrir la boîte noire
Pour évaluer les performances d'EDrGAT, les auteurs l'ont entraîné sur la majeure partie des données puis l'ont testé sur des paires médicament–lignée cellulaire–dose qu'il n'avait jamais vues auparavant. Le modèle a expliqué près de 90 % de la variation de la sensibilité aux médicaments sur cet ensemble de test retenu et a largement surpassé plusieurs approches existantes, y compris d'autres systèmes d'apprentissage profond et des méthodes d'apprentissage automatique plus traditionnelles. Tout aussi important, l'équipe a analysé pourquoi le modèle produisait ces prédictions. À l'aide d'outils attribuant des scores d'influence à chaque caractéristique d'entrée, ils ont constaté que les tendances récentes de réponse aux médicaments et les doses voisines jouaient le rôle le plus déterminant, tandis que l'identité de la lignée cellulaire et du médicament contribuait de façon moindre mais néanmoins significative. Ce type de transparence est essentiel si de tels outils doivent appuyer des décisions cliniques.
Ce que cela pourrait signifier pour les soins futurs du cancer du sein
L'étude montre qu'un modèle d'IA, entraîné sur de vastes jeux de données de tests médicamenteux et renforcé par un traitement rigoureux des données, peut fournir des prédictions précises et explicables sur la façon dont les cellules du cancer du sein répondent à différents médicaments et doses. Bien que ce travail utilise des données de lignées cellulaires plutôt que des prélèvements patients directs, il indique une perspective où les médecins pourraient utiliser des modèles similaires pour réduire les options thérapeutiques, éviter des médicaments vraisemblablement inefficaces et choisir des niveaux de dose avec plus d'assurance. Il pourrait aussi aider les chercheurs à prioriser les candidats-médicaments à développer, rapprochant des thérapies du cancer du sein plus personnalisées de la réalité.
Citation: Anushya, A., Alreshidi, A., Varshini, N.H. et al. Novel explainable deep learning based drug sensitivity prediction for early treatment of breast cancer. Sci Rep 16, 14833 (2026). https://doi.org/10.1038/s41598-026-44617-y
Mots-clés: cancer du sein, sensibilité aux médicaments, apprentissage profond, oncologie de précision, pharmacogénomique