Clear Sky Science · nl
Nieuwe uitlegbare deep learning-gebaseerde voorspelling van medicijngevoeligheid voor vroege behandeling van borstkanker
Waarom dit onderzoek van belang is voor patiënten
Geneesmiddelen tegen borstkanker werken niet voor iedereen op dezelfde manier. Artsen moeten vaak vertrouwen op proberen en toetsen om het juiste middel en de juiste dosis te vinden. Deze studie onderzoekt hoe kunstmatige intelligentie kan leren van grote verzamelingen laboratoriumgegevens om te voorspellen hoe borstkankercellen reageren op uiteenlopende geneesmiddelen. In de toekomst zouden dergelijke hulpmiddelen kunnen helpen eerdere en beter op maat gemaakte behandelkeuzes te begeleiden en tegelijkertijd het zoeken naar nieuwe therapieën versnellen.
Computers leren responspatronen van geneesmiddelen lezen
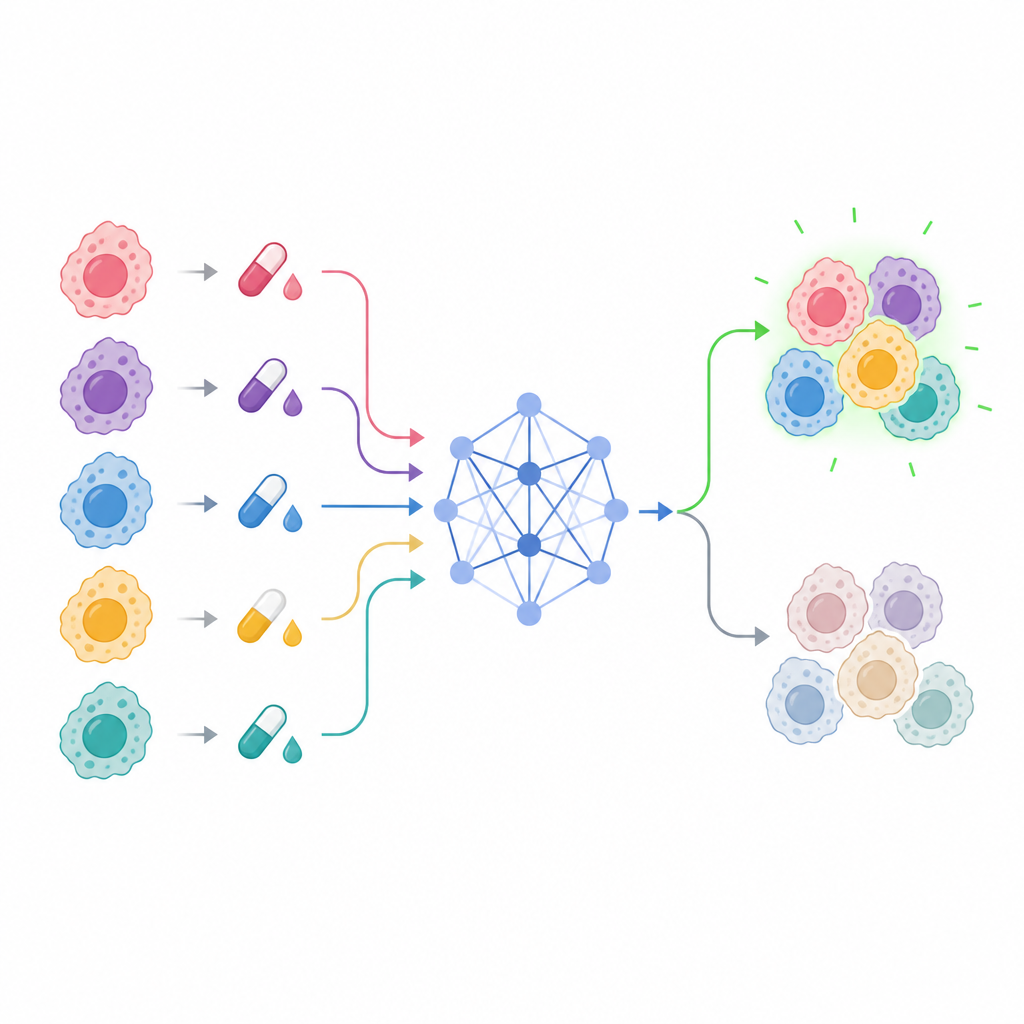
Moderne laboratoria kunnen honderden middelen testen over veel borstkankercellijnen en vastleggen hoe sterk elk geneesmiddel de celgroei remt bij verschillende doses. Het resultaat is een enorme tabel met cijfers die moeilijk met het blote oog te interpreteren is. De auteurs trainden een computermodel om deze patronen te lezen en te voorspellen hoe gevoelig een gegeven borstkankercellijn zal zijn voor een specifiek geneesmiddel en dosis. Hun focus lag op een bijzonder rijke bron van metingen uit tientallen borstkankercellijnen en meer dan honderd geneesmiddelverbindingen, elk getest op vele concentratieniveaus.
De gegevens achter de schermen opschonen en verrijken
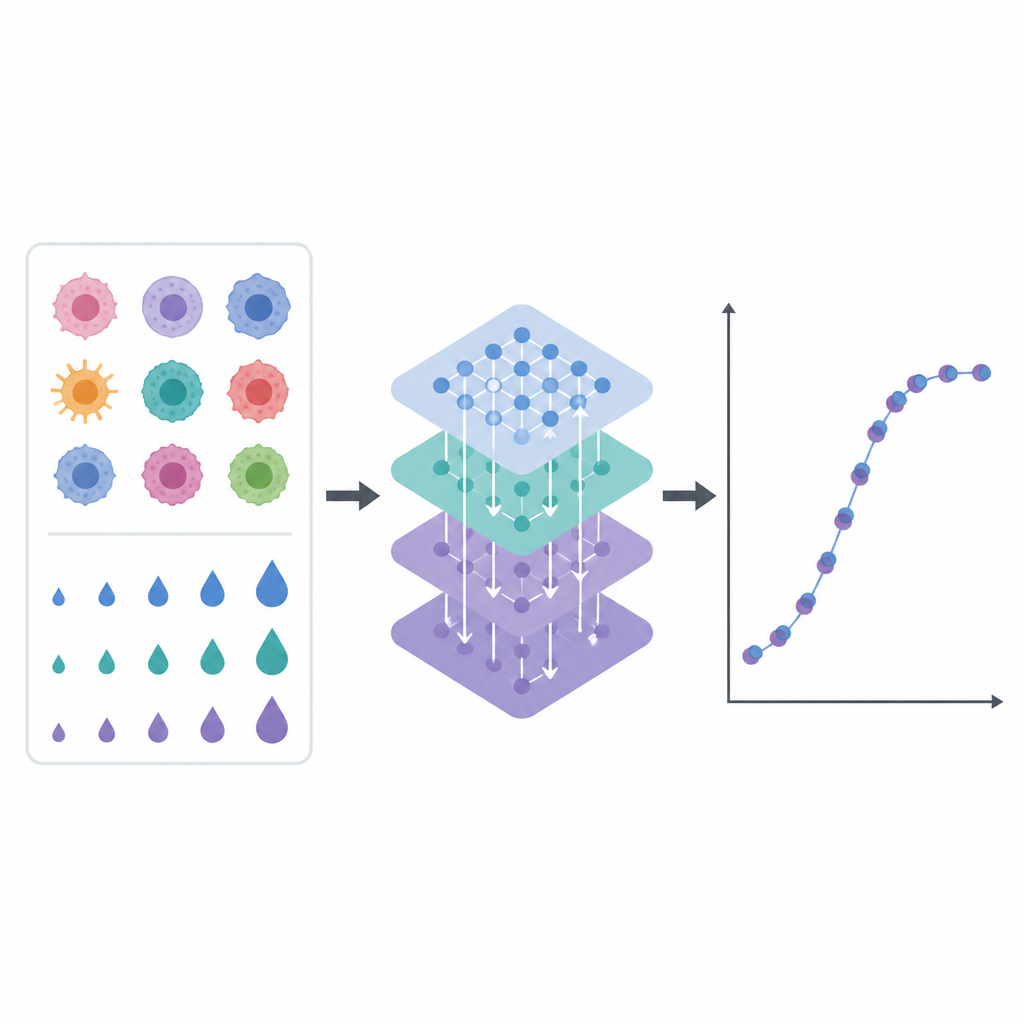
Laboratoriumgegevens uit de echte wereld zijn rommelig. Sommige metingen ontbreken, namen van cellijnen kunnen inconsistent zijn en herhaalde tests van hetzelfde middel komen niet altijd overeen. Het team bouwde een zorgvuldig pipeline om deze informatie op te schonen. Ze brachten borstkankercellijnen in kaart over meerdere openbare bronnen, uniformeerden geneesmiddelnamen en doses, en middelen herhaalde metingen om ruis te verminderen. Vervolgens voegden ze nieuwe tijdgebonden kenmerken toe die beschrijven hoe geneesmiddel effecten veranderen bij aangrenzende doses, zoals kortetermijntrends en gladde gemiddelden. Deze extra aanwijzingen helpen het computermodel dosis-responscurves te begrijpen in plaats van elk datapunt geïsoleerd te behandelen.
Hoe het nieuwe model leert van cellen en geneesmiddelen
Centraal in het werk staat een model dat de Explainable Drug Graph Attention Transformer heet, of EDrGAT. Simpel gezegd is het een type deep learning-netwerk dat gelijktijdig kijkt naar geneesmiddelnamen, de kankercellijn en de dosis en leert hoe ze met elkaar interageren. Het representeert elk geneesmiddel en elke cellijn als een punt in een numerieke ruimte en gebruikt vervolgens een attention-mechanisme om zich te concentreren op de meest informatieve combinaties. Het model neemt ook de geconstrueerde dosisgeschiedeniskenmerken op, zodat het kan vastleggen hoe responsen zich opbouwen of uitsmeren over aangrenzende concentraties. Hierdoor kan het inschatten hoe gevoelig een borstkankercellijn waarschijnlijk is, zelfs bij dosisniveaus die nooit rechtstreeks zijn getest.
Nauwkeurigheid controleren en de zwarte doos openen
Om te beoordelen hoe goed EDrGAT presteert, trainden de auteurs het op het merendeel van de gegevens en testten het vervolgens op geneesmiddel–cellijn–dosisparen die het nog nooit eerder had gezien. Het model verklaarde bijna 90 procent van de variatie in medicijngevoeligheid op deze apart gehouden set en deed het duidelijk beter dan verschillende bestaande benaderingen, waaronder andere deep learning-systemen en meer traditionele machine learning-methoden. Even belangrijk onderzochten de onderzoekers waarom het model zijn voorspellingen maakte. Met behulp van tools die invloedsscores toekennen aan elke invoerkenmerk, ontdekten ze dat recente trends in geneesmiddelrespons en aangrenzende doses de grootste rol speelden, terwijl de identiteit van de cellijn en het geneesmiddel kleinere maar nog steeds betekenisvolle effecten bijdroegen. Deze vorm van transparantie is belangrijk als zulke hulpmiddelen medische beslissingen moeten ondersteunen.
Wat dit kan betekenen voor toekomstige borstkankerzorg
De studie toont aan dat een AI-model, getraind op grote datasets met medicijntests en versterkt door zorgvuldige gegevensverwerking, nauwkeurige en uitlegbare voorspellingen kan doen over hoe borstkankercellen reageren op verschillende middelen en doses. Hoewel dit werk cellijngegevens gebruikt in plaats van directe patiëntmonsters, wijst het op een toekomst waarin artsen vergelijkbare modellen zouden kunnen gebruiken om behandelopties te verkleinen, waarschijnlijk ineffectieve middelen te vermijden en dosisniveaus met meer vertrouwen te selecteren. Het kan ook onderzoekers helpen prioriteit te geven aan welke kandidaat-geneesmiddelen verder ontwikkeld moeten worden, waardoor meer gepersonaliseerde borstkankertherapieën dichterbij komen.
Bronvermelding: Anushya, A., Alreshidi, A., Varshini, N.H. et al. Novel explainable deep learning based drug sensitivity prediction for early treatment of breast cancer. Sci Rep 16, 14833 (2026). https://doi.org/10.1038/s41598-026-44617-y
Trefwoorden: borstkanker, medicijngevoeligheid, deep learning, precisie-oncologie, farmacogenomica