Clear Sky Science · es
Nueva predicción explicable de sensibilidad a fármacos basada en aprendizaje profundo para el tratamiento precoz del cáncer de mama
Por qué esta investigación importa para los pacientes
Los fármacos contra el cáncer de mama no funcionan igual en todas las personas. Los médicos a menudo deben recurrir a prueba y error para encontrar el medicamento y la dosis adecuados. Este estudio explora cómo la inteligencia artificial puede aprender de grandes colecciones de datos de laboratorio para predecir cómo responderán las células de cáncer de mama a distintos fármacos. En el futuro, estas herramientas podrían ayudar a orientar elecciones de tratamiento más tempranas y personalizadas, además de acelerar la búsqueda de nuevas terapias.
Enseñar a las máquinas a leer patrones de respuesta a fármacos
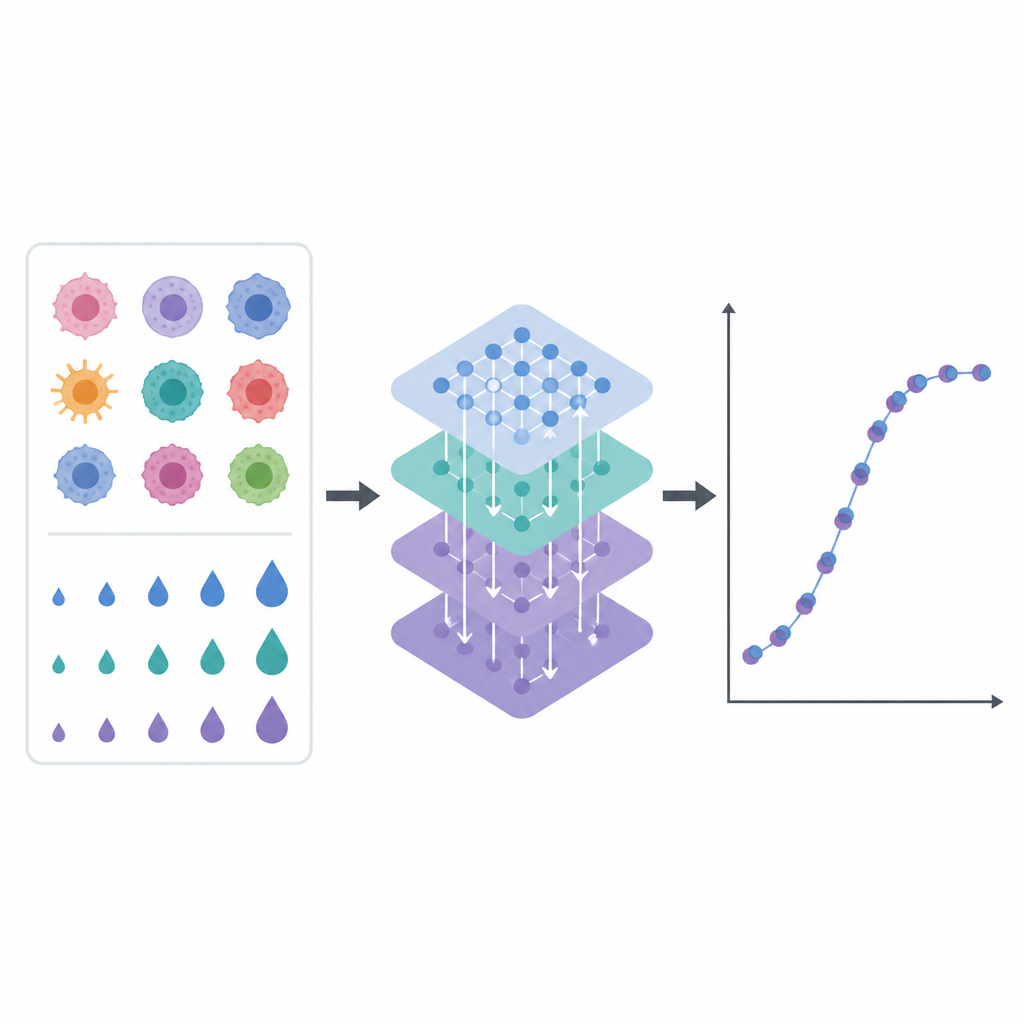
Los laboratorios modernos pueden probar cientos de medicamentos en muchas líneas celulares de cáncer de mama, registrando cuánto ralentiza cada fármaco el crecimiento celular a diferentes dosis. El resultado es una enorme tabla de números difícil de interpretar a simple vista. Los autores entrenaron un modelo informático para leer estos patrones y predecir cuán sensible será una línea celular de cáncer de mama a un fármaco y dosis específicos. Su enfoque se centró en un recurso especialmente rico de mediciones de docenas de líneas celulares y más de cien compuestos farmacológicos, cada uno probado en múltiples niveles de concentración.
Depurar y enriquecer los datos entre bastidores
Los datos de laboratorio del mundo real son desordenados. Faltan algunas mediciones, los nombres de las líneas celulares pueden ser inconsistentes y las pruebas repetidas del mismo fármaco no siempre coinciden. El equipo construyó una canalización cuidadosa para ordenar esta información. Emparejaron las líneas celulares de cáncer de mama entre varios recursos públicos, unificaron nombres de fármacos y dosis, y promediaron mediciones repetidas para reducir el ruido. Luego añadieron nuevas características temporales que describen cómo cambian los efectos del fármaco con dosis cercanas, como tendencias a corto plazo y medias suavizadas. Estas pistas adicionales ayudan al modelo informático a entender las curvas de respuesta a dosis en lugar de tratar cada punto de datos aisladamente.
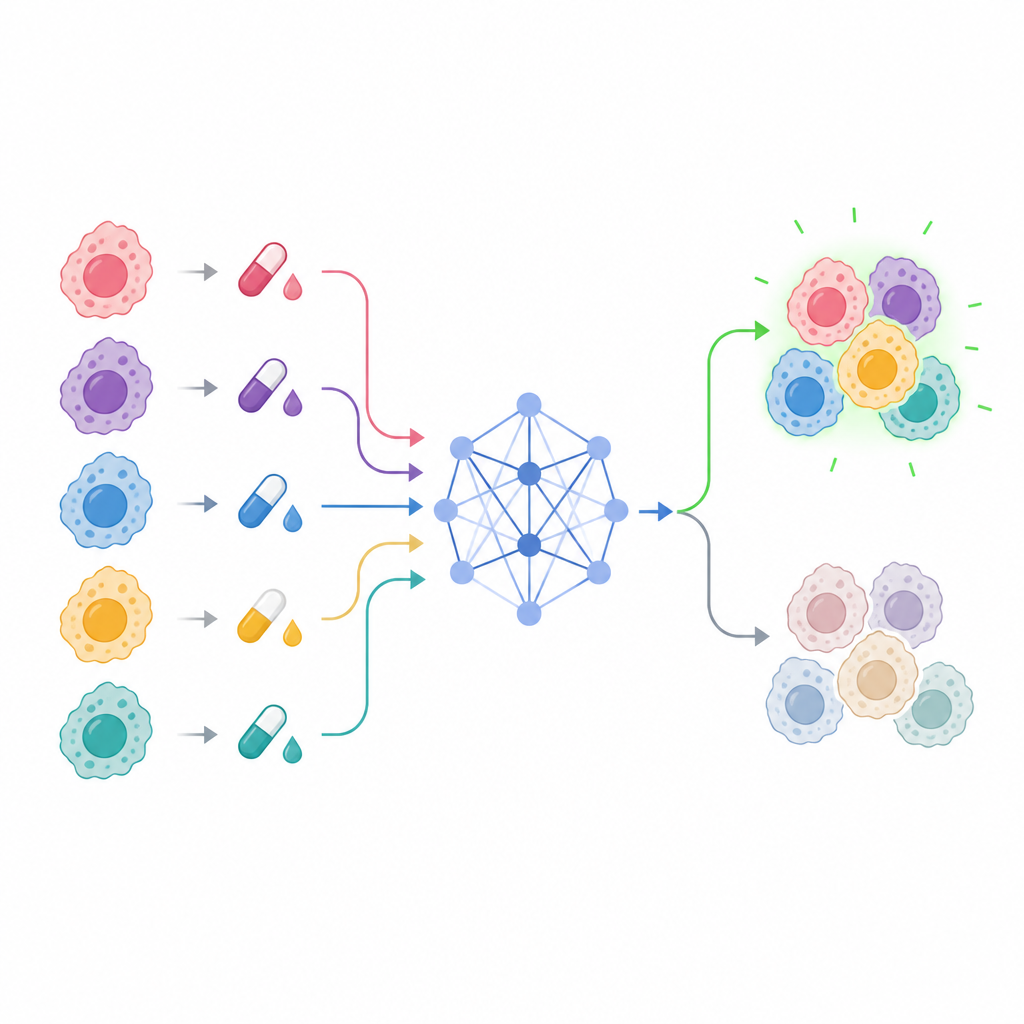
Cómo aprende el nuevo modelo a partir de células y fármacos
En el centro del trabajo está un modelo llamado Explainable Drug Graph Attention Transformer, o EDrGAT. En términos más sencillos, es un tipo de red de aprendizaje profundo que considera el nombre del fármaco, la línea celular de cáncer y la dosis conjuntamente y aprende cómo interactúan. Representa cada fármaco y cada línea celular como un punto en un espacio numérico y luego utiliza un mecanismo de atención para centrarse en las combinaciones más informativas. El modelo también incorpora las características de historial de dosis diseñadas para captar cómo las respuestas se acumulan o se suavizan a través de concentraciones cercanas. Haciendo esto, puede estimar cuán sensible es probable que sea una línea celular de cáncer de mama incluso en niveles de dosis que nunca se probaron directamente.
Comprobar la precisión y abrir la caja negra
Para evaluar el rendimiento de EDrGAT, los autores lo entrenaron con la mayor parte de los datos y luego lo probaron en pares fármaco-línea celular-dosis que nunca había visto. El modelo explicó cerca del 90 por ciento de la variación en la sensibilidad a fármacos en este conjunto retenido y superó claramente a varios enfoques existentes, incluidos otros sistemas de aprendizaje profundo y métodos de aprendizaje automático más tradicionales. Igualmente importante, el equipo examinó por qué el modelo hacía sus predicciones. Usando herramientas que asignan puntuaciones de influencia a cada característica de entrada, encontraron que las tendencias recientes de respuesta al fármaco y las dosis cercanas jugaron el papel más importante, mientras que la identidad de la línea celular y del fármaco contribuyeron en menor medida pero con efectos todavía significativos. Este tipo de transparencia es relevante si tales herramientas van a respaldar decisiones clínicas.
Qué podría significar esto para la futura atención del cáncer de mama
El estudio muestra que un modelo de IA, entrenado con grandes conjuntos de datos de pruebas de fármacos y reforzado mediante un manejo cuidadoso de los datos, puede hacer predicciones precisas y explicables sobre cómo responden las células de cáncer de mama a distintos fármacos y dosis. Aunque este trabajo utiliza datos de líneas celulares en lugar de muestras directas de pacientes, apunta hacia un futuro en el que los médicos podrían usar modelos similares para reducir opciones de tratamiento, evitar fármacos probablemente ineficaces y seleccionar niveles de dosis con más confianza. También puede ayudar a los investigadores a priorizar qué candidatos farmacológicos avanzar en su desarrollo, acercando terapias para el cáncer de mama más personalizadas a la realidad.
Cita: Anushya, A., Alreshidi, A., Varshini, N.H. et al. Novel explainable deep learning based drug sensitivity prediction for early treatment of breast cancer. Sci Rep 16, 14833 (2026). https://doi.org/10.1038/s41598-026-44617-y
Palabras clave: cáncer de mama, sensibilidad a fármacos, aprendizaje profundo, oncología de precisión, farmacogenómica