Clear Sky Science · zh
利用化学信息特征的深度学习增强框架用于从有机固体废物预测生物油产率
将日常废物转化为有用燃料
家庭垃圾、食物残渣、农场废弃物和污泥通常成为我们需要付费处理的问题。然而,所有这些有机废物都富含能量,可以转化为液体燃料,即生物油。挑战在于不同废物在加热时表现差异很大,工程师难以事先准确预测能获得多少有用的油。本文展示了一种结合化学洞见、经过精心设计的深度学习模型,如何准确预测来自各种废物混合物的生物油产率,从而有助于将垃圾转变为更可靠的清洁能源来源。
为什么预测生物油如此困难
生物油通常通过一种称为热裂解的过程制得,即在无氧条件下快速加热有机物质。原则上,这可以将从作物秸秆到藻类的一切转化为可升级为燃料和化学品的液体。实际上,结果差异很大。碳、氢、氧、灰分(无机矿物)和水分的混合物在不同废物流中各异,实验室使用的反应器和加热条件也不同。早期的机器学习研究试图预测产率,但通常基于小规模、范围有限的数据集,并使用相对简单的模型,这些模型难以处理涉及的复杂非线性化学反应。
构建丰富且统一的数据图景
为了解决这些难题,作者汇集了文献中245个实验案例的统一数据集,均聚焦于有机固体废物。每条记录包含材料组成的详细信息(碳、氢、氮、氧、灰分、固定碳和挥发分含量)、热裂解温度及其他操作条件,以及由此得到的生物油产率。通过仔细筛选,剔除了缺失或不明确的数据记录,并将所有产率换算为统一基准,以便不同研究的数字可以公平比较。随后进行了统计检查,以理解这些变量之间的关联并发现可能会干扰学习算法的潜在冗余。
为数据加入化学洞见
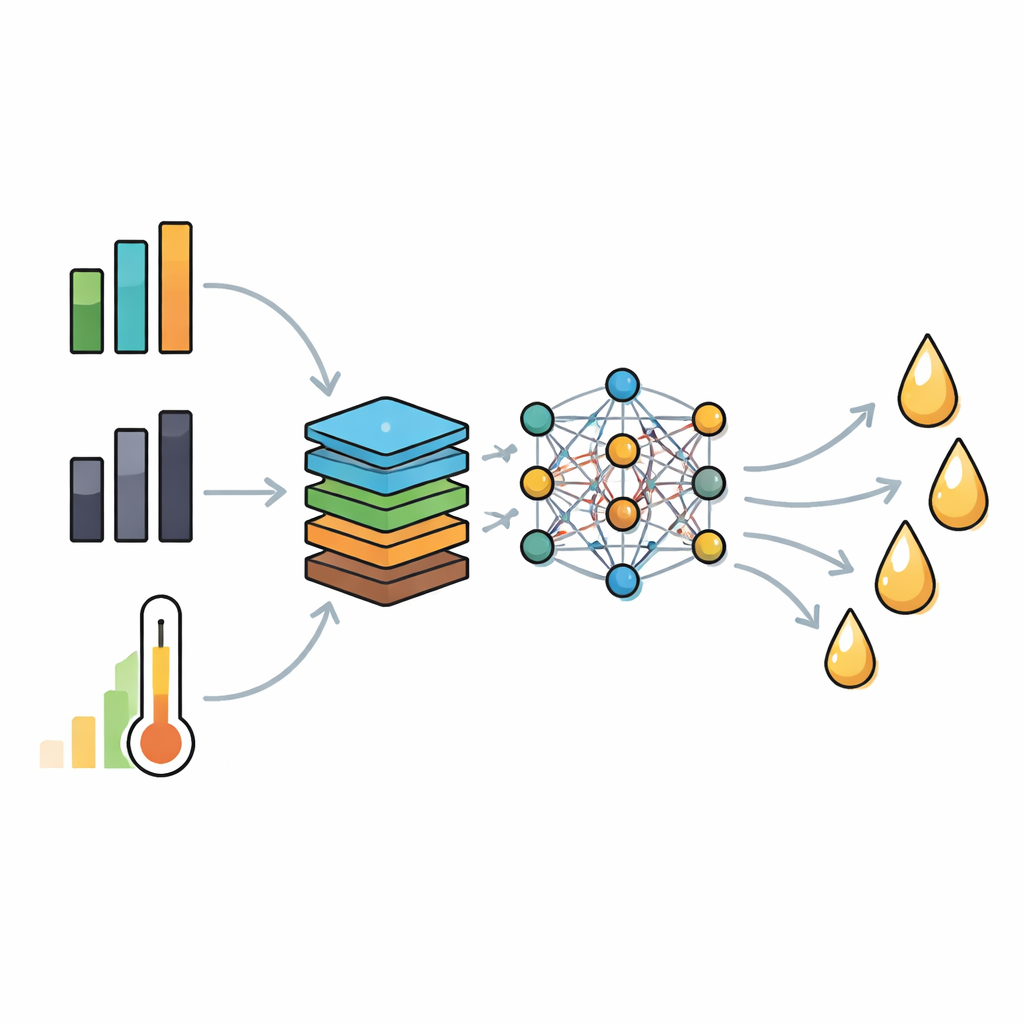
研究者没有仅将原始测量值直接输入模型,而是构建了新的、具有化学意义的特征。他们创建了氢碳比和氧碳比等比值、衡量材料转为挥发物与固体炭比例的指标、校正灰分影响的挥发分指标(考虑到阻碍油形成的矿物质),以及总结燃料富集程度的能量密度指数。随后应用方差膨胀分析来消除信息重叠,保留了一组紧凑的九个关键输入。该精简特征集在避免统计陷阱导致模型不稳定的同时,保留了化学的物理意义。
教神经网络“读懂”废物
有了这些精炼输入,团队训练了两类预测模型:深度神经网络和一种流行的基于树的方法——Light Gradient Boosting(LightGBM)。两者都通过先进的搜索算法进行调参,这些算法探索学习率、网络深度等多种模型设置组合,以找到与数据最匹配的参数。深度模型最终采用了三层隐藏层,并使用丢弃(dropout)和批规范化(batch normalization)等正则化技巧以避免过拟合。在反复的训练-测试循环中,优化后的深度网络持续优于其他方法,在预测新、未见过的生物油产率时实现了0.98的决定系数(R²)和略高于一个百分点的均方根误差。
哪些因素对产油最重要
除了原始精度之外,作者还想知道哪些废物和工艺特性对产率影响最大。全局敏感性研究显示,碳含量、固定碳、灰分和温度起主要作用,无论是单独作用还是通过相互作用共同影响。高挥发分和有利的氢含量有助于提高产率,但其效应往往与这些主要变量相关联。这一排序与已建立的热裂解化学理解一致:更多的碳和挥发分有利于油的形成,而高灰分和过多的固定碳则倾向于将物质导向炭和气体。模型“观点”与化学直觉的一致性增强了人们对其并非仅在拟合噪声的信心。
从智能预测到更聪明的废物转燃料设计
通俗地说,这项研究表明,一个以真实化学为基础而非盲目模式搜索的精心设计的深度学习系统,能够提前告诉我们给定的有机废物和加热条件下可能获得多少液体燃料。这使得筛选有前景的原料、选择高效的操作窗口以及规划更环保的废物转能项目变得更容易,无需进行无休止的试验与错误。作者也指出,更大且更多样化的数据集将进一步提高可靠性,但他们的框架已经设定了新的性能基准,并为数据驱动的、更清洁且可预测的生物油生产系统设计指明了方向。
引用: Almansour, S., Alkwai, L.M., Yadav, K. et al. Deep learning enhanced prediction framework for bio oil yield from organic solid waste with chemically informed features. Sci Rep 16, 13667 (2026). https://doi.org/10.1038/s41598-026-43604-7
关键词: 生物油预测, 有机固体废物, 深度学习, 热裂解, 生物质能源