Clear Sky Science · en
Deep learning enhanced prediction framework for bio oil yield from organic solid waste with chemically informed features
Turning Everyday Waste into Useful Fuel
Household garbage, food scraps, farm leftovers, and sewage sludge usually end up as a problem we pay to get rid of. Yet all of this organic waste is rich in energy that could be turned into liquid fuel, known as bio‑oil. The challenge is that different wastes behave very differently when heated, making it hard for engineers to know in advance how much useful oil they will get. This paper shows how a deep learning model, carefully designed with chemical insight, can accurately predict bio‑oil yields from a wide mix of wastes, helping to turn trash into a more reliable clean‑energy resource.
Why Predicting Bio‑Oil Is So Hard
Bio‑oil is commonly produced by a process called pyrolysis, where organic material is rapidly heated in the absence of oxygen. In principle, this can turn everything from crop stalks to algae into a liquid that can be upgraded into fuels and chemicals. In practice, results vary wildly. The mix of carbon, hydrogen, oxygen, ash (inorganic minerals), and moisture differs from one waste stream to another, and laboratories use different reactors and heating conditions. Earlier machine‑learning studies tried to predict yields, but were often built on small, narrow datasets and used relatively simple models that struggled with the messy, nonlinear chemistry involved.
Building a Rich, Harmonized Data Picture
To tackle these hurdles, the authors assembled a harmonized dataset of 245 experimental cases from the literature, all focused on organic solid wastes. Each entry includes detailed information on the material’s composition (carbon, hydrogen, nitrogen, oxygen, ash, fixed carbon, and volatile content), the pyrolysis temperature and other operating conditions, and the resulting bio‑oil yield. Careful screening removed records with missing or unclear values, and all yields were converted to a common basis so that numbers from different studies could be fairly compared. Statistical checks were then used to understand how these variables were related and to spot hidden redundancies that could confuse a learning algorithm.
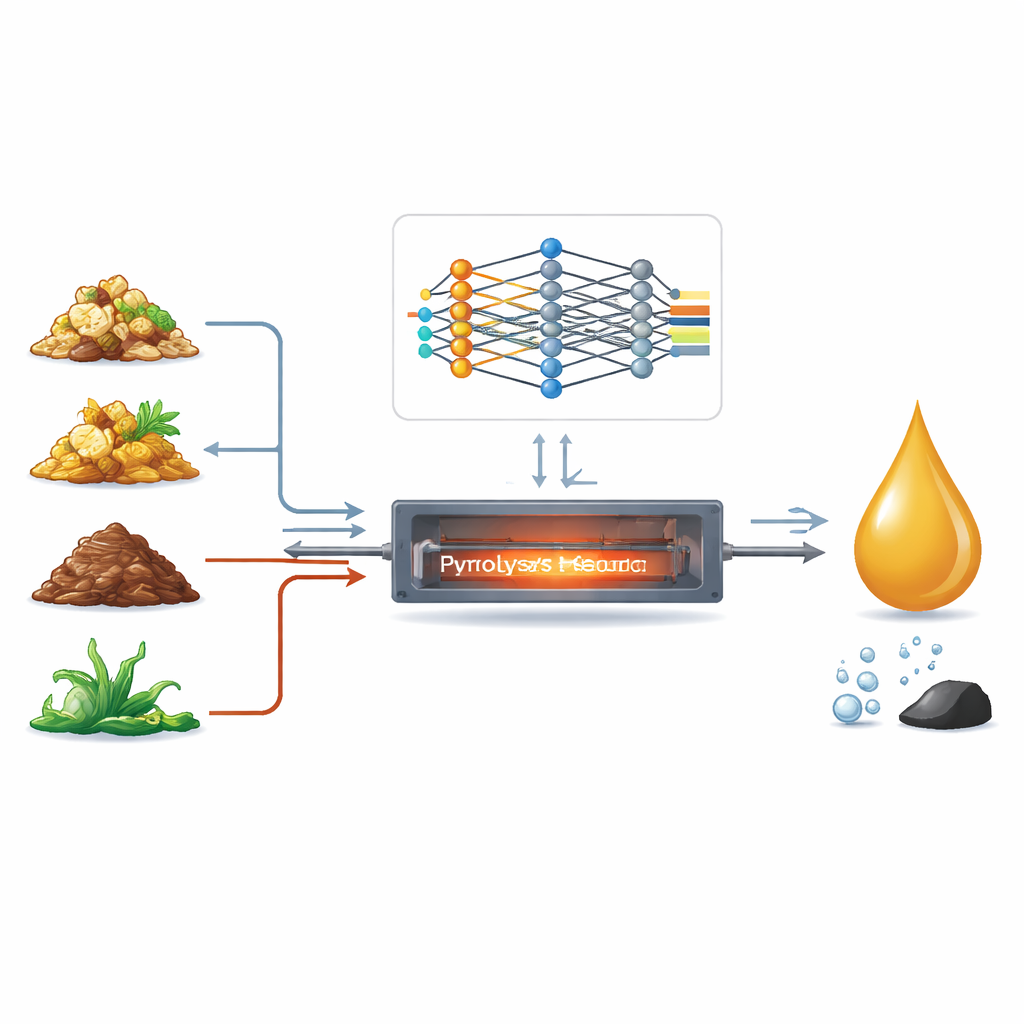
Adding Chemical Insight to the Numbers
Rather than feeding only raw measurements into a model, the researchers engineered new, chemically meaningful features. They created ratios such as hydrogen‑to‑carbon and oxygen‑to‑carbon, a measure of how much of the material turns into vapors versus solid char, an ash‑corrected volatile fraction that accounts for minerals that hinder oil formation, and an energy‑density index summarizing fuel richness. They then applied a technique called variance inflation analysis to eliminate overlapping information and keep a compact set of nine key inputs. This trimmed feature set preserves the physical meaning of the chemistry while avoiding the statistical pitfalls that can make models unstable.
Teaching a Neural Network to Read Waste
With this refined input, the team trained two kinds of predictive models: a deep neural network and a popular tree‑based method called Light Gradient Boosting. Both were tuned using advanced search algorithms that explore many combinations of model settings, such as learning rate and network depth, to find those that best match the data. The deep model ultimately used three hidden layers and regularization tricks like dropout and batch normalization to avoid overfitting. Across repeated train‑and‑test cycles, the optimized deep network consistently outperformed all competing approaches, achieving a coefficient of determination (R²) of 0.98 and a root‑mean‑square error just above one percentage point in predicting new, unseen bio‑oil yields.
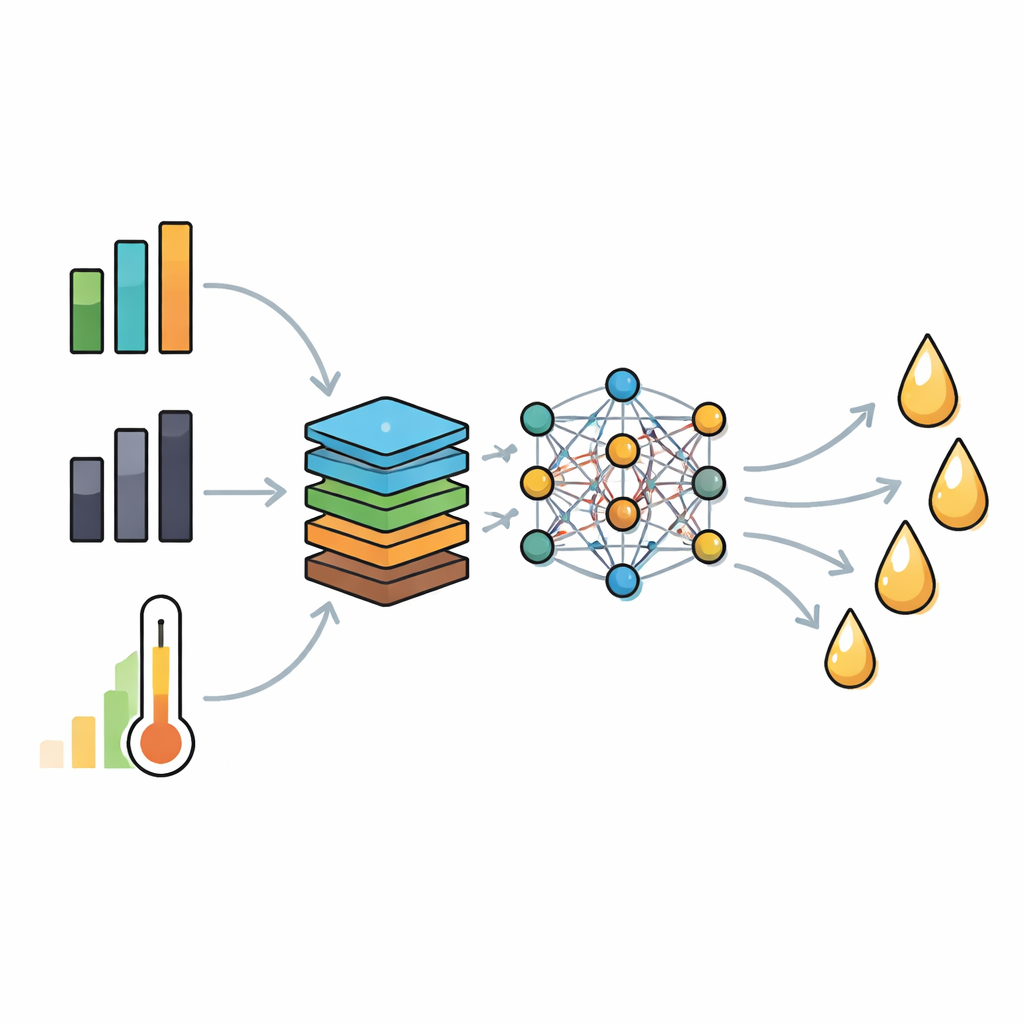
What Matters Most for Making Oil
Beyond raw accuracy, the authors wanted to know which aspects of the waste and process most strongly influence yield. A global sensitivity study showed that carbon content, fixed carbon, ash, and temperature play the largest roles, both individually and through their interactions. High volatile content and favorable hydrogen levels help, but their effects are often tied to these main variables. This ranking matches established understanding of pyrolysis chemistry: more carbon and volatiles tend to support oil formation, while high ash and excessive fixed carbon steer material toward char and gas. The agreement between the model’s “views” and chemical intuition boosts confidence that it is not just fitting noise.
From Smart Predictions to Smarter Waste‑to‑Fuel Design
In everyday terms, the study shows that a well‑designed deep learning system, grounded in real chemistry rather than blind pattern hunting, can tell us in advance how much liquid fuel we are likely to get from a given organic waste and set of heating conditions. This makes it easier to screen promising feedstocks, pick efficient operating windows, and plan greener waste‑to‑energy projects without running endless trial‑and‑error experiments. While the authors note that larger and more diverse datasets will further improve reliability, their framework already sets a new performance benchmark and points the way toward data‑driven design of cleaner, more predictable bio‑oil production systems.
Citation: Almansour, S., Alkwai, L.M., Yadav, K. et al. Deep learning enhanced prediction framework for bio oil yield from organic solid waste with chemically informed features. Sci Rep 16, 13667 (2026). https://doi.org/10.1038/s41598-026-43604-7
Keywords: bio-oil prediction, organic solid waste, deep learning, pyrolysis, biomass energy