Clear Sky Science · fr
Cadre de prédiction amélioré par apprentissage profond pour le rendement en bio‑huile à partir de déchets solides organiques avec des caractéristiques chimiquement informées
Transformer les déchets quotidiens en carburant utile
Les ordures ménagères, les restes alimentaires, les résidus agricoles et les boues d’épuration finissent généralement par poser un problème dont l’élimination coûte cher. Pourtant, tous ces déchets organiques sont riches en énergie et pourraient être convertis en carburant liquide, appelé bio‑huile. Le défi vient du fait que les différents déchets réagissent très différemment lorsqu’ils sont chauffés, ce qui rend difficile pour les ingénieurs de prévoir à l’avance quelle quantité d’huile utile sera obtenue. Cet article montre comment un modèle d’apprentissage profond, conçu avec une connaissance chimique appropriée, peut prédire avec précision les rendements en bio‑huile pour un large mélange de déchets, aidant ainsi à transformer les détritus en une ressource énergétique propre plus fiable.
Pourquoi la prédiction de la bio‑huile est si difficile
La bio‑huile est généralement produite par un procédé appelé pyrolyse, où la matière organique est chauffée rapidement en l’absence d’oxygène. En principe, cela peut transformer tout — des tiges de récolte aux algues — en un liquide susceptible d’être valorisé en carburants et produits chimiques. En pratique, les résultats varient énormément. La composition en carbone, hydrogène, oxygène, cendres (minéraux inorganiques) et humidité diffère d’un flux de déchets à l’autre, et les laboratoires utilisent des réacteurs et des conditions de chauffage différents. Les études antérieures en apprentissage automatique ont tenté de prédire les rendements, mais s’appuyaient souvent sur des jeux de données petits et limités et utilisaient des modèles relativement simples qui peinaient à capturer la chimie désordonnée et non linéaire en jeu.
Construire un portrait de données riche et harmonisé
Pour relever ces obstacles, les auteurs ont assemblé un jeu de données harmonisé de 245 cas expérimentaux tirés de la littérature, tous centrés sur des déchets solides organiques. Chaque entrée comprend des informations détaillées sur la composition du matériau (carbone, hydrogène, azote, oxygène, cendres, carbone fixe et teneur en volatils), la température de pyrolyse et autres conditions opératoires, ainsi que le rendement en bio‑huile obtenu. Un tri minutieux a éliminé les enregistrements avec des valeurs manquantes ou peu claires, et tous les rendements ont été convertis sur une base commune afin de permettre une comparaison équitable entre études. Des contrôles statistiques ont ensuite été utilisés pour comprendre les relations entre ces variables et détecter des redondances cachées susceptibles de perturber un algorithme d’apprentissage.
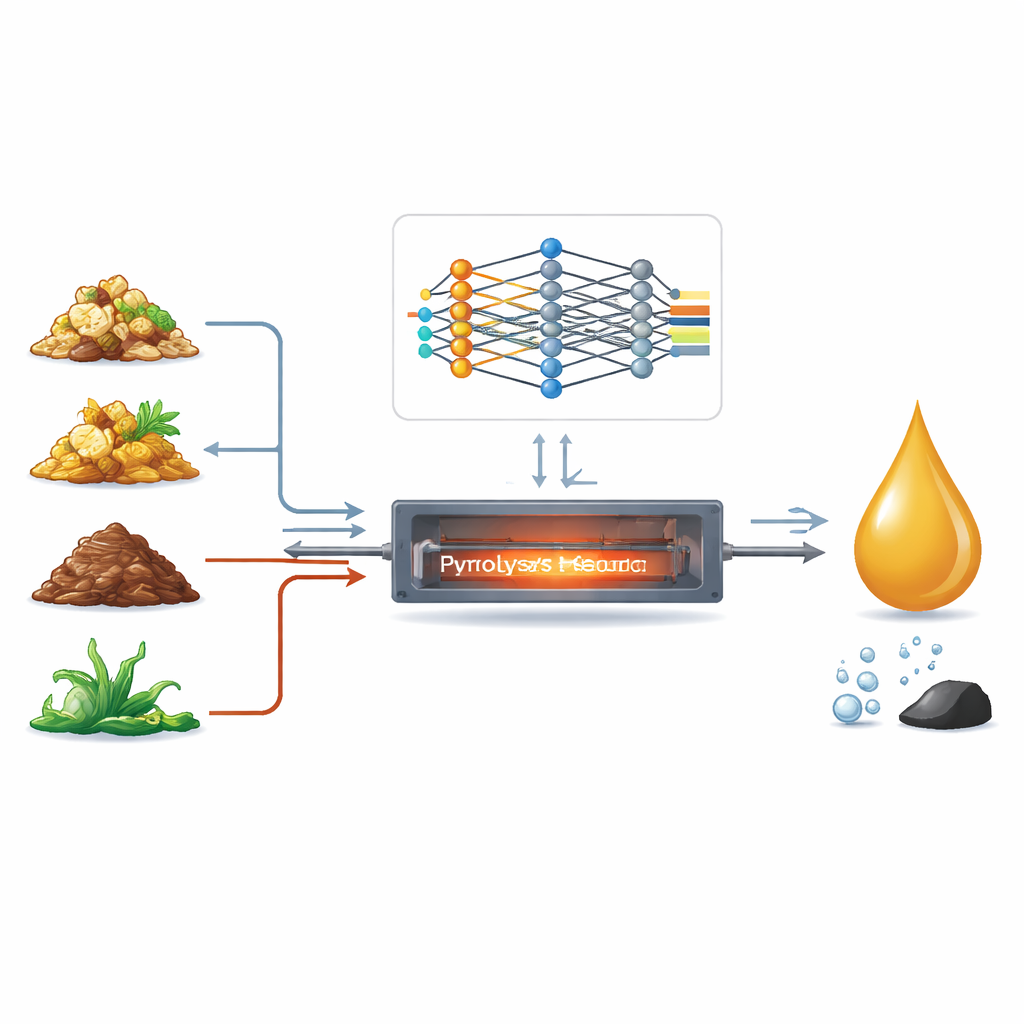
Ajouter un éclairage chimique aux chiffres
Plutôt que d’alimenter le modèle uniquement avec des mesures brutes, les chercheurs ont ingénieré de nouvelles caractéristiques chimiquement signifiantes. Ils ont créé des rapports tels que hydrogène‑sur‑carbone et oxygène‑sur‑carbone, une mesure de la part de la matière qui se transforme en vapeurs plutôt qu’en charbon solide, une fraction volatile corrigée des cendres qui tient compte des minéraux freinant la formation d’huile, et un indice de densité énergétique résumant la richesse en combustible. Ils ont ensuite appliqué une technique d’analyse de l’inflation de la variance pour éliminer les informations redondantes et conserver un ensemble compact de neuf entrées clés. Cet ensemble de caractéristiques réduit préserve la signification physique de la chimie tout en évitant les écueils statistiques qui peuvent rendre les modèles instables.
Apprendre à un réseau neuronal à lire les déchets
Avec ces entrées affinées, l’équipe a entraîné deux types de modèles prédictifs : un réseau neuronal profond et une méthode populaire basée sur les arbres appelée Light Gradient Boosting. Les deux ont été optimisés à l’aide d’algorithmes de recherche avancés qui explorent de nombreuses combinaisons d’hyperparamètres, comme le taux d’apprentissage et la profondeur du réseau, pour trouver celles qui correspondent le mieux aux données. Le modèle profond retenu utilisait finalement trois couches cachées et des techniques de régularisation telles que le dropout et la normalisation par lot pour éviter le surapprentissage. Au cours de cycles répétés d’entraînement et de test, le réseau profond optimisé a systématiquement surpassé toutes les approches concurrentes, atteignant un coefficient de détermination (R²) de 0,98 et une erreur quadratique moyenne racine légèrement supérieure à un point de pourcentage pour la prédiction de rendements en bio‑huile nouveaux et non vus.
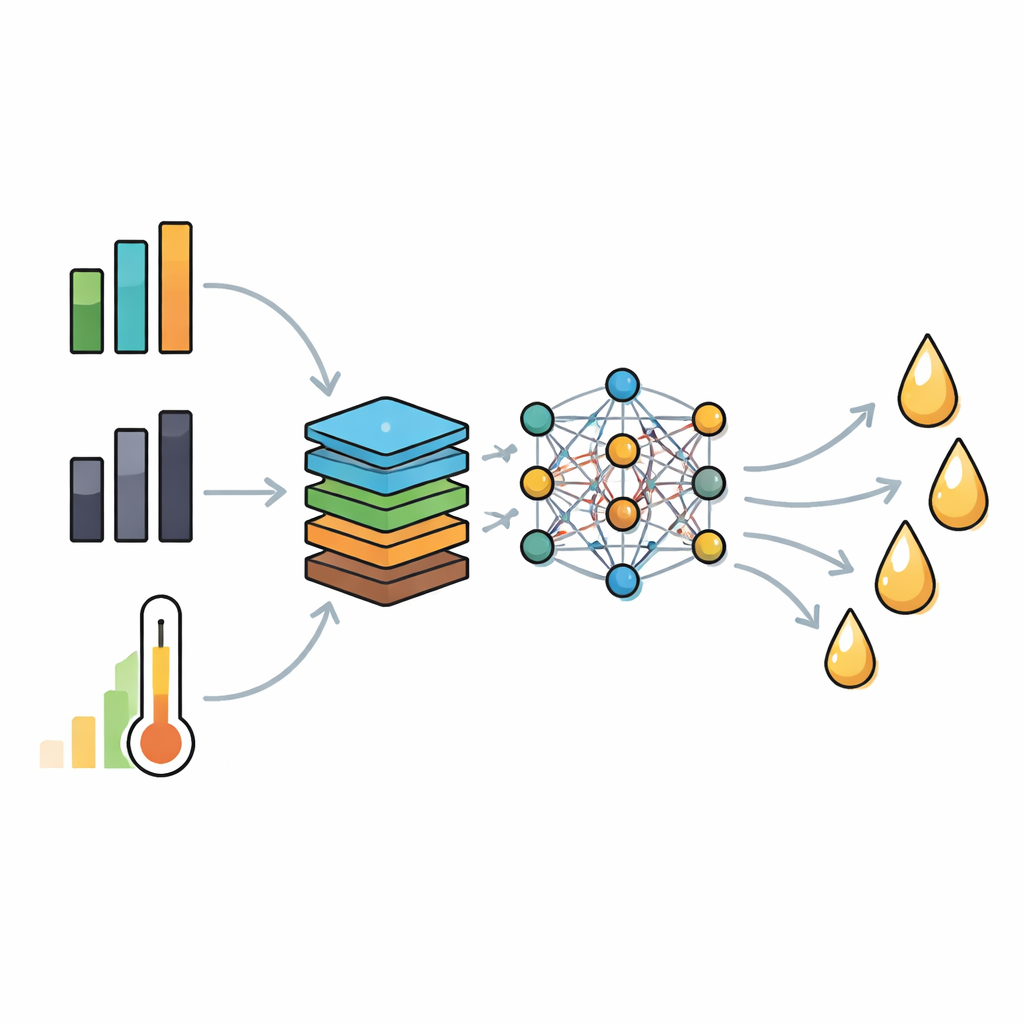
Ce qui compte le plus pour produire de l’huile
Au‑delà de la simple précision, les auteurs ont cherché à savoir quels aspects des déchets et du procédé influencent le plus fortement le rendement. Une étude de sensibilité globale a montré que la teneur en carbone, le carbone fixe, les cendres et la température jouent les rôles les plus importants, à la fois individuellement et par leurs interactions. Une forte teneur en volatils et des niveaux d’hydrogène favorables aident, mais leurs effets sont souvent liés à ces variables principales. Ce classement correspond à la compréhension établie de la chimie de la pyrolyse : plus de carbone et de volatils tendent à soutenir la formation d’huile, tandis que des cendres élevées et un carbone fixe excessif orientent la matière vers le charbon et les gaz. L’accord entre les « vues » du modèle et l’intuition chimique renforce la confiance que le modèle ne se contente pas d’ajuster du bruit.
Des prédictions intelligentes à une conception plus avisée de la valorisation des déchets
En termes simples, l’étude montre qu’un système d’apprentissage profond bien conçu, ancré dans la chimie réelle plutôt que dans une simple recherche de motifs, peut nous dire à l’avance quelle quantité de carburant liquide on est susceptible d’obtenir d’un déchet organique donné et de conditions de chauffage données. Cela facilite le tri des matières premières prometteuses, le choix de plages opératoires efficaces et la planification de projets de valorisation des déchets plus écologiques sans multiplier les expériences d’essai‑erreur. Si les auteurs notent que des jeux de données plus larges et plus diversifiés amélioreront encore la fiabilité, leur cadre établit déjà un nouveau repère de performance et indique la voie vers une conception basée sur les données de systèmes de production de bio‑huile plus propres et plus prévisibles.
Citation: Almansour, S., Alkwai, L.M., Yadav, K. et al. Deep learning enhanced prediction framework for bio oil yield from organic solid waste with chemically informed features. Sci Rep 16, 13667 (2026). https://doi.org/10.1038/s41598-026-43604-7
Mots-clés: prédiction de bio‑huile, déchets solides organiques, apprentissage profond, pyrolyse, énergie de la biomasse