Clear Sky Science · pl
Ulepszony uczeniem głębokim system predykcyjny wydajności bio‑oleju z odpadów organicznych z chemicznie sensownymi cechami
Przekształcanie codziennych odpadów w użyteczne paliwo
Odpady domowe, resztki jedzenia, pozostałości z gospodarstw i osady ściekowe zazwyczaj stają się problemem, za którego utylizację płacimy. Tymczasem wszystkie te odpady organiczne są bogate w energię, którą można przekształcić w płynne paliwo zwane bio‑olejem. Trudność polega na tym, że różne odpady zachowują się bardzo odmiennie podczas nagrzewania, co utrudnia inżynierom wcześniejsze oszacowanie, ile użytecznego oleju otrzymają. W artykule pokazano, jak model uczenia głębokiego, zaprojektowany z uwzględnieniem wiedzy chemicznej, może dokładnie przewidywać wydajność bio‑oleju dla szerokich mieszanek odpadów, ułatwiając przekształcanie śmieci w bardziej niezawodne źródło czystej energii.
Dlaczego przewidywanie bio‑oleju jest takie trudne
Bio‑olej jest zwykle produkowany w procesie zwanym pirolizą, gdzie materiał organiczny jest szybko podgrzewany w warunkach beztlenowych. W teorii można w ten sposób przetwarzać wszystko, od resztek pochodzenia roślinnego po algi, na ciecz, którą można następnie ulepszać do postaci paliw i chemikaliów. W praktyce wyniki bywają bardzo zróżnicowane. Mieszanka węgla, wodoru, tlenu, popiołu (minerałów nieorganicznych) i wilgoci różni się w zależności od strumienia odpadów, a laboratoria stosują różne reaktory i warunki nagrzewania. Wcześniejsze badania z użyciem uczenia maszynowego próbowały przewidywać wydajności, lecz często opierały się na małych, wąskich zestawach danych i stosowały stosunkowo proste modele, które miały problemy z opisaniem złożonej, nieliniowej chemii zachodzącej w procesie.
Budowa bogatego, zharmonizowanego obrazu danych
Aby sprostać tym wyzwaniom, autorzy zgromadzili zharmonizowany zbiór danych obejmujący 245 przypadków eksperymentalnych z literatury, wszystkie dotyczące stałych odpadów organicznych. Każdy wpis zawiera szczegółowe informacje o składzie materiału (węgiel, wodór, azot, tlen, popiół, węgiel utwardzony i zawartość lotnych), temperaturze pirolizy i innych warunkach operacyjnych oraz o uzyskanej wydajności bio‑oleju. Staranna selekcja usunęła rekordy z brakującymi lub niejasnymi wartościami, a wszystkie wydajności zostały przeliczone na wspólną podstawę, by umożliwić uczciwe porównania liczb z różnych badań. Następnie zastosowano kontrole statystyczne, aby zrozumieć powiązania między zmiennymi i wykryć ukryte redundancje, które mogłyby zdezorientować algorytm uczący się.
Dodanie chemicznego wglądu do liczb
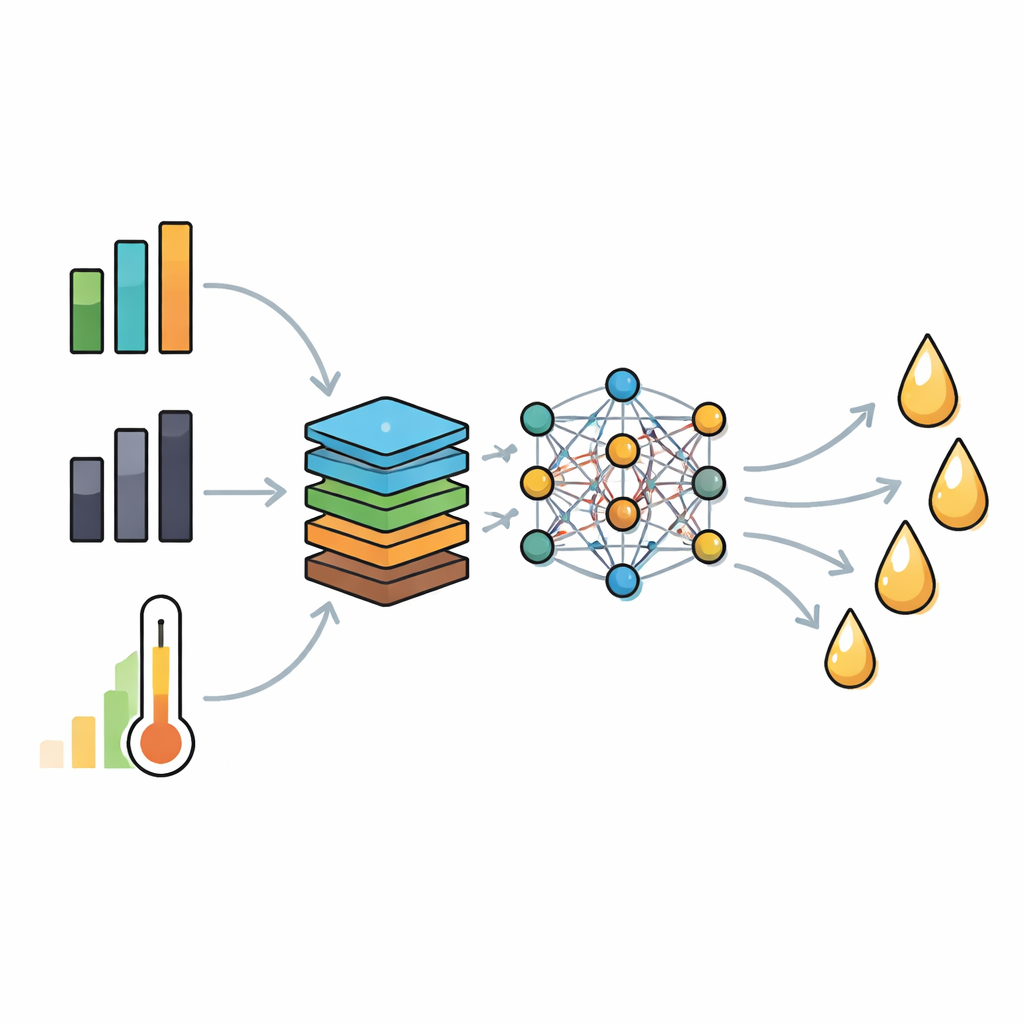
Zamiast podawać modelowi wyłącznie surowe pomiary, badacze skonstruowali nowe, chemicznie istotne cechy. Stworzyli stosunki, takie jak wodór‑do‑węgla i tlen‑do‑węgla, miarę, ile materiału przechodzi w opary w porównaniu z węglem stałym (char), skorygowaną względem popiołu frakcję lotnych uwzględniającą minerały hamujące tworzenie oleju oraz indeks gęstości energetycznej podsumowujący bogactwo paliwowe. Zastosowali następnie analizę inflacji wariancji, by wyeliminować nakładające się informacje i zachować zwarty zestaw dziewięciu kluczowych wejść. Ten przycięty zestaw cech zachowuje fizyczne znaczenie chemii, unikając jednocześnie pułapek statystycznych, które mogą destabilizować modele.
Nauczanie sieci neuronowej „czytania” odpadów
Dysponując tym dopracowanym zestawem wejściowym, zespół wytrenował dwa rodzaje modeli predykcyjnych: sieć neuronową głębokiego uczenia oraz popularną metodę opartą na drzewach — Light Gradient Boosting. Oba modele były dostrajane za pomocą zaawansowanych algorytmów poszukiwania, które eksplorują liczne kombinacje ustawień (takich jak szybkość uczenia czy głębokość sieci), by znaleźć te najlepiej dopasowane do danych. Model głęboki ostatecznie używał trzech ukrytych warstw oraz technik regularizacyjnych, takich jak dropout i normalizacja wsadowa, by zapobiegać przeuczeniu. W wielokrotnych cyklach trenowania i testowania zoptymalizowana sieć głęboka konsekwentnie przewyższała konkurencyjne podejścia, osiągając współczynnik determinacji (R²) równy 0,98 oraz błąd średniokwadratowy (RMSE) nieco powyżej jednego punktu procentowego przy przewidywaniu nowych, niewidzianych wcześniej wydajności bio‑oleju.
Co najbardziej wpływa na produkcję oleju
Ponad samą dokładnością, autorzy chcieli wiedzieć, które cechy odpadów i parametry procesu najsilniej wpływają na wydajność. Globalne badanie wrażliwości wykazało, że największą rolę odgrywają zawartość węgla, węgiel utwardzony, popiół i temperatura — zarówno indywidualnie, jak i poprzez wzajemne interakcje. Wysoka zawartość lotnych i korzystny poziom wodoru pomagają, lecz ich efekty często są powiązane z wymienionymi głównymi zmiennymi. To uporządkowanie odpowiada ustalonemu rozumieniu chemii pirolizy: więcej węgla i lotnych sprzyja tworzeniu oleju, podczas gdy wysoki udział popiołu i nadmiar węgla utwardzonego kierują materiał w stronę charu i gazu. Zgodność „widzianych” przez model zależności z intuicją chemiczną zwiększa pewność, że model nie dopasowuje się jedynie do szumów.
Od inteligentnych predykcji do lepszego projektowania konwersji odpadów w paliwo
Mówiąc prościej, badanie pokazuje, że dobrze zaprojektowany system uczenia głębokiego, osadzony w rzeczywistej chemii zamiast w ślepym poszukiwaniu wzorców, potrafi z wyprzedzeniem powiedzieć, ile płynnego paliwa można oczekiwać z danego odpadu organicznego i określonych warunków nagrzewania. Ułatwia to wybór obiecujących surowców, dobór efektywnych okien operacyjnych oraz planowanie bardziej zielonych projektów konwersji odpadów bez prowadzenia nieskończonych eksperymentów metodą prób i błędów. Choć autorzy zauważają, że większe i bardziej zróżnicowane zbiory danych poprawią niezawodność, ich ramy już teraz ustanawiają nowy punkt odniesienia wydajności i wskazują drogę ku projektowaniu napędzanemu danymi dla czystszej, bardziej przewidywalnej produkcji bio‑oleju.
Cytowanie: Almansour, S., Alkwai, L.M., Yadav, K. et al. Deep learning enhanced prediction framework for bio oil yield from organic solid waste with chemically informed features. Sci Rep 16, 13667 (2026). https://doi.org/10.1038/s41598-026-43604-7
Słowa kluczowe: predykcja bio‑oleju, odpady organiczne stałe, uczenie głębokie, piroliza, energia biomasy